引言
在回归分析中,模型的拟合度一般采用可决系数()和修正的可决系数()来衡量,但会受到自变量个数,样本数和可决系数本身大小等多重因素的影响,所以难以得到准确的分布函数及其特征。
判断回归模型拟合优度程度优劣最常用的数量是指标可决系数(又被称为决定系数),是建立在对总离差平方和进行分解的基础上。可决系数是对回归模型拟合程度的综合度量,越大,模型拟合程度越高。越小,则模型对样本的拟合程度越差。
然而可决系数在实际的模型运用中往往会受到许多因素的影响,在检验回归方程与样本值的拟合优度是不恰当的。因此引入了修正的可决系数,即随着解释变量个数的增加而减少,不会增加,所增加解释变量个数会引起的可决系数的增大,但增大与拟合优劣无关。所以就必须对可决系数进行调整,使之能够更好的拟合。
1可决系数的定义及研究意义
1.1可决系数的定义
回归直线拟合的好坏取决于RSS及ESS的大小,或者说取决于回归平方和ESS占总平方和TSS比例(ESS/TSS)的大小。各观测点越靠近近直线,ESS/TSS则越大,直线拟合得越好。将回归平方和占总平方和的比例定义为样本决定系数,即可决系数,记为,即
可决系数表示了回归直线对观测数据的拟合优度。若所有观测点都落在直线上,残差平方和RSS=0,=1,拟合是完全的;如果Y的变化与X无关,X完全无助于解释Y的变差,此时,,则=0。可见的取值范围是[0,1]。越接近于1,说明回归平方和占总平方和的比例越大,回归直线越接近于各个观测点,用X的变化来解释Y值变差的部分就越多,回归直线的拟合程度就越好;反之,越接近于零,回归直线的拟合程度就越差。
1.2现实意义
(1)理论意义:可决系数(也称R方),指的是回归平方和(ESS-explained sum of squares)在总变差(TSS-total sum of squares)中所占据的比重(其中或)。可以当作综合度量回归模型对样本观测值拟合优度的度量指标。通常取值范围为0-1之间,取值越大表示模型的拟合程度愈高,说明变量之间的相关程度也愈高,其因变量的变化可由自变量解释部分的比重愈大。取值越小则表示模型拟合程度越低,说明变量之间的相关程度也就越低,其因变量的变化可由自变量解释部分的比重越小。
(2)现实意义:可决系数(即复可决系数或多重可决系数)为解释变差占总变差的比重,用来表示解释变量对被解释变量的解释程度。
在实际运用中,拟合优度作为一种统计方法常用来衡量模型中期望值和实际值之间的差距。换言之是用来衡量怎样将实际观测的数值进行模拟的相关预测。拟合优度同样也可以运用到医学和药物检测、食品科学、电力建设、地震研究等多方面领域。
2可决系数以及修正可决系数的研究现状
2.1国外研究现状
Karl Pearson在1900年发表的关于拟合优度检验的论文被看作是近代数理统计的开端,在这篇论文中对统计学应用一个常见的重要问题提出一个判定标准,即一组随机观测数据能否合理地看成是来自一个其分布完全已知的总体。
自Karl Pearson第一次提出了拟合优度检验的定义,对于这个问题的研究便有了很大的发展,有的是扩展和深入,有的是基于新的概念上的研究。
对于扩展和深入,其主要代表性的结论有1924年Fisher提出了估计—参数丢失—自由度的原则和所谓的极小估计。
1946年Cramer提出了著名的似然比检验结果。
1949年Neyman提出了修正的统计量
1984年Cressie和Read提出了系统的幂偏差统计量理论等。
对于在新概念上的研究,其主要代表性结论是1933年Kolmogorov提出了Kolgorov–Smilnov统计量。以及40年代末和50年代初发展起来的Cramer–von Miaes型统计量等一系列基于经验分布的检验方法。
Cramer(1987),定义可决系数是的概率极限:
对于给定的U,可以算出。然后依据,算出,其次应用系数和反复多次的随机序列,估计出Y,用估算出来的Y和原先解释变量样本回归就可以得出不同的可决系数,分析其性质,并和给定的U作对比,进而发觉可决系数的一般规律。
Press and Zellner(1978)指出的,可决系数可以反映反映模型的拟合度但由于可决系数分布的复杂性并且依附于未知参数,故其反应有限。Press and Zellner(1978)证实了在估算的准确度,选取贝叶斯方法是很有用的,可以用后验分布来估算的置信区间。
Ohtani(1994)给出了的分布函数和高阶矩函数,分别是:
其中,是分布函数,,,是Beta函数,。在公式中令和,就可以分别得出和的分布函数和高阶矩函数。而从公式中可以得知,分布函数和高阶函数包含未知参数,而又包含估计值,因此实际运用中就无法依据分布函数精准地算出和的均值和方差。
对于和的估计值和标准误差,并建立它们的置信区间可以运用迭代算法,可以分析残差的特征对迭代方法的影响。蒙特•卡洛试验证明了方法的可行性和有效性。迭代法是先依据样本估算出参数值,在应用估算出来的参数重新计算新的样本,在根据新的样本估计参数,重复一定的频率,从而得出参数估计的一个序列,用来分析其均值和方差,以反映参数的特点。
2.2国内研究现状
早在50年代初期,我国著名统计学家张里千教授就得出了Kolgorov–Smilnov统计量的精确分布,并对随机观察得到了一组以随机数据,而在90年代初,杨振海教授又运用引入的人工参数方法,从而建立出了拟合优度的线性模型,得出了检验统计量,并探究了一些关于大样本的性质。其基础思想是应用人工参数将P.P.plot作图法转变为对线性模型的说明,进而将拟合优度检验问题改变为参数的检验问题。
3可决系数和修正的可决系数在拟合优度中作用
作为检验回归方程与样本值拟合优度的指标,越大(),表明回归方程与样本拟合程度的愈好;反之,越小()表明回归方程与样本值拟合程度的就愈差。当然,我们都期望愈大愈好,而在对的使用上很简单就可以看出,与模型中解释变量的数目有关联。
4可决系数平方修正模型
4.1修正可决系数的定义
可决系数是回归解释变量数的非减函数,也就是说引入的解释变量越多可决系数可能会更高,但是并不是每个解释变量都有效的。因此引入了修正的可决系数,即随着解释变量个数的增加而减少,不会增加,所增加解释变量个数会引起的可决系数的增大,但增大与拟合优劣无关。所以就必须对可决系数进行调整,使之能够更好的拟合,其计算公式为:
式中,(n-k-1)为残差平方和()的自由度;(n-1)为总离差平方和()的自由度。
4.2可决系数与修正可决系数之间的关系
修正的可决系数与未修正的多重可决系数之间的关系如下:
从可以看出,当增加一个解释变量是,会增加,引起()的减少,但增加,因而不会增加。这样,用判定回归方程与样本值拟合优度就消除了对解释变量个数的依赖。另外从还可以看出,当k>1时,<;如果样本的观测数目n很多,与相差较小,当使用小样本时,解释变量的数目很多,就会远远小于,甚至可能会取负值。在中,当<()时,<0。此时,修正的应视为零。
在现实生活中,我们希望所建模型的越大越好。但可决系数只是对模型拟合优度的度量,越大,虽能阐述列入模型中的解释变量对被解释变量整体影响程度越大,但并不能全面阐明模型中各个解释变量对被解释变量的影响程度是显著。
5可决系数的局限性
是线性回归分析中反映回归方程对样本拟合程度的一个常用指标。但是,计量经济研究中大量的回归实践却说明,所表明的拟合优度存在重要的缺陷,在实践应用中还可见的不恰当检验,因此对数量经济学理论方法与实践的结合中往往会形成许多不好的影响。
由于其总变差的局限,作为回归模型的拟合优度在理论上是不适当的。具体体现在:拟合优度检验只能说明模型对样本数据的近视情况,利用给定的样本值得到了回归方程,我们的目标就是利用回归方程对总体进行经济分析和预测。回归方程是否可以代表总体,就是总体模型的设定是否显著,就必须进行统计学意义上的检验。但是拟合优度与拟合误差一定是相互依存的,它们之间不可能独立于对方而孤立存在。与相对应的误差概念是:
是关于Y的总变差的拟合误差率。与Y之间的残差是回归分析中最重要的拟合误差,总变差与Y总变差之间的拟合误差要次之。因此,一样由于其总变差有一定的局部性,用作回归模型的拟合误差率概念也是不确切的。
6实证分析
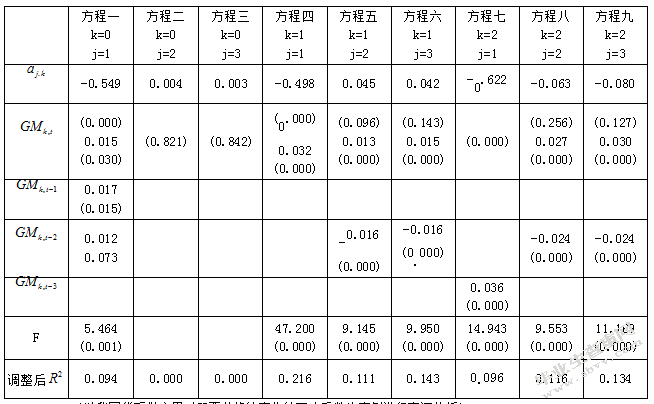

(以我国货币供应量对股票价格的变化的可决系数为案例进行实证分析)
观察以上结果,发现以下特征,当期以及提前1期和2期的M0同比增长率对上证综合指数的变化产生显著的正影响,但调整后的可决系数却变低,解释能力不强;而当期以及提前3期以内的M0的同比增长率对比上证180指数和深证综合指数却不产生影响。当期M1同比增长率对上证综合指数的变化有显著的正影响,且调整后的可决系数可达0.216,为7个整体显著的方程中最高,其他6个方程的调整后可决系数约在0.1左右;当期M1同比增长率对比上证180指数和深证综合指数的变化会产生显著的正影响,而提前2期的M1同比增长率则对当期的上证180指数和深证综合指数的变化产生显著的负影响,后者系数绝对值稍微大于前者。提前3期的M2同比增长率对上证综合指数的变化也有显著的正影响;当期M2同比增长率对上证180指数和深证综合指数的变化有显著的正影响,而提前2期的M2同比增长率则对当期的上证180指数和深证综合指数的变化有负影响,后者系数绝对值略小于前者。
对以上的实证结果进行分析,当k=1或2是,方程中回归系数显著、方程整体显著,说明M1和M2供应量的变化的确会影响股票价格水平,而M0的变化与我国股市的联系没有M1和M2那么紧密。较低的调整后可决系数表明,货币供应量的变化只能解释股票价格变动很小的一部分原因。
结束语
在因变量的总变动中,被样本回归方程所解释的部分愈多,说明样本观测值与回归直线的拟合效果愈好,否则,就说明样本观测值与回归直线的拟合效果不理想。因此,可以用回归平方和占总的离差平方和的比重来衡量模型的拟合优劣程度,称为判定系数,记作。可决系数和修正的可决系数作为检验回归方程与样本值拟合优度的指标,越大(),表明回归方程与样本拟合的愈好;反之越小,则表明回归方程与样本值拟合就愈差。但在实际生活中的运用却表明着可决系数也存在着许多不足之处,对数量经济学理论方法与应用实践造成很多不良影响。现在可决系数及修正的可决系数被广泛应用于金融及医学等方面的领域,在未来的研究过程中,应该尽量修复可决系数的缺陷,降低其造成的不良影响,提高拟合优度的准确性,使其更广泛的应用于更多领域。
参考文献
[1]Daniel C.Jupiter.Investigator’s Corner:Snug as a Bug:Goodness of Fit and Quality of Models[J]2017
[2]Martin Eling.Data breaches:Goodness of Fit,pricing,and risk measurement[J]2017
[3]王巧英.回归估计标准误差与可决系数的比较[J],统计与决策,2006
[4]李军军;张建涛.回归模型可决系数的可决性研究[J],统计与决策,2005
[5]王重;刘黎明.拟合优度检验统计量的设定方法[J],统计与决策,2010
[6]郭丽红.多元分布拟合优度检验及其应用[D],华北电力大学,2014
[7]孙立宏.析二因素无交互作用方差分析中数学模型的建立[J],职大学报,2010
[8]李子奈.《计量经济学》[M],高等教育出版社,2000
[9]李景华;朱尚伟:关于的几点质疑[J],数量经济技术经济研究,2013
[10]赵松山:对拟合优度的影响因素分析与评价[J],东北财经大学学报,2003
[11]赵文奇:经济计量学建模方法论研究[M],成都:西南财经大学出版社,1998
[12]姜诗章,王锦功:计量经济学教程[M],吉林:吉林大学出版社,1989
[13]刘明:线性回归模型的统计检验关系辨析[J],统计与信息论坛,2011
[14]程维虎:拟合优度检验的回归分析方法及其应用[J],北京工业大学学报,2000
[15]黄兴旺;胡四修;郭军:中国股票市场的二因素模型[J],当代经济科学,2002
下载提示:
1、如文档侵犯商业秘密、侵犯著作权、侵犯人身权等,请点击“文章版权申述”(推荐),也可以打举报电话:18735597641(电话支持时间:9:00-18:30)。
2、网站文档一经付费(服务费),不意味着购买了该文档的版权,仅供个人/单位学习、研究之用,不得用于商业用途,未经授权,严禁复制、发行、汇编、翻译或者网络传播等,侵权必究。
3、本站所有内容均由合作方或网友投稿,本站不对文档的完整性、权威性及其观点立场正确性做任何保证或承诺!文档内容仅供研究参考,付费前请自行鉴别。如您付费,意味着您自己接受本站规则且自行承担风险,本站不退款、不进行额外附加服务。
原创文章,作者:写文章小能手,如若转载,请注明出处:https://www.447766.cn/chachong/13027.html,