第1章绪论
1.1研究背景及意义
骨肉瘤是一种来源于间充质细胞的恶性骨肿瘤,主要见于儿童和青少年,发病率为百万分之三,我国每年有近万人患病,患病部位以肢体长管状骨干骺端为主,在盆骨、脊柱、下颚等部位也较为常见。目前,该病的病因和致病性尚不清楚,医生的治疗手段有限,在患者患病初期,病灶通常通过手术的方式进行切除,而晚期等不可手术的情况下患者只能采取放疗与化疗的方式。针对肿瘤生长在局部的特性,采用放射治疗的方法更为适宜,但效果不理想,成功的概率仅为20%~30%,以至于患者的预后情况较差、死亡率高[1-2]。由此可见,骨肉瘤十分是一种极其凶险的肿瘤,人们目前需要更加有效的诊断策略与治疗手段。
目前,癌症的发病率逐年升高,对癌症患者进行精确的预后预测已成为目前最为重要的问题。预后,指的是预测疾病的可能病程和结局。不仅包括在某个时间段内预测某种发生的可能性等时间线索,还包括判断疾病的特定结果[3]。预后预测的好坏很大程度上能决定癌症患者后续治疗的成功与否。预后预测除了关注患者的临床信息外,还可以利用患者肿瘤发展不同时期的组学数据进行系统的分析。
随着数据量近年来的爆炸式增长,数据更新速度不断加快,已超出某一特定领域内人类所掌握常见及罕见的治疗相关分子生物学类型范围,因此精准医学需要依赖计算机驱动的临床决策支持系统(clinical decision support system,CDSS)来满足相关知识迅速及时地传递和使用[4]。这一步骤的构建包括收集各种医学数据,构建相应的各种数据结构,最后开发出适合实际情况的临床决策工具。在此前提下,将患者个人的组学数据与临床决策支持系统联系起来,这就构成了基于组学数据的临床决策支持系统,该系统可以为患者的治疗提供更精确的介入信息,有助于进一步了解肿瘤的分子机制,提高临床决策支持的准确度,改善用药的合理性,促进后期治疗方案的指定的科学性,为医生提供更加准确科学的治疗建议。
因此,通过对癌症患者的组学数据进行数据分析与数据挖掘,利用筛选得到的差异标志物进行特征选择并构建癌症诊断预测模型,从而建成基于组学数据的临床决策支持系统,该系统能够对患者进行较好的预后预测与精确的诊断与治疗。
本文采用基于R语言的数据分析和挖掘方法,开展儿童骨肉瘤的预后机制的研究,目的是建立对于医生的临床诊断和药物研发具有帮助的决策支持系统(模块)。建立的决策支持系统可以用于其他癌症和疾病,具有较好的实践意义和推广价值。
1.2国内外研究现状
组学数据是一个庞大的数据概念,其包括生命体征,检查检验,医嘱,基因组学,转录组学,蛋白组学等数据[5]。针对冗杂的癌症患者的组学数据,2006年,隶属于X健康研究院(National Institutes of Health,NIH)的X国家癌症研究所(National Cancer Institute,NCI)和国家人类基因组研究所(National Human Genome Research Institute,NHGRI)发起了癌症基因组图谱(The Cancer Genome Atlas,TCGA)计划。TCGA计划的目的主要是得到一个全面的、多维的,针对多种癌症基因组的图谱,至今已经收录了33类多达2.5PB的不同类型的癌症数据。利用癌症基因组图谱(The Cancer Genome Atlas,TCGA)计划的这些分子分析数据能够对癌症患者进行精准的预后。传统上的预后大多数基于临床因素,例如:年龄,肿瘤等级,治疗方法等。目前通过结合分子信息,能够达到更好的预后效果。
2010年,Weigel MT1与Dowsett M.通过对乳腺癌中的雌激素受体(ER)和孕激素受体(PR)以及人类表皮生长因子受体2(HER2)的生物标志物进行研究,发现其对乳腺癌的预后预测具有重要的价值,并在临床应用中取得了较好的效果[6]。
2017年,施达通过分析肾透明细胞癌患者数据中lncRNAs的表达值信息,将总的数据集分为训练集和测试集,并对训练集与测试集进一步统计学分析与研究,找到了五个与肾透明细胞癌预后相关的重要lncRNAs。以这五个lncRNAs为基准,将所有的患者分为高风险和低风险两组。进行统计学分析后发现高风险组患者与低风险组患者的生存率存在显著差异,与其他临床因素相比,这五个与肾透明细胞癌预后相关的重要lncRNAs具有独立的预后价值[7]。
2018年,房晓南通过分析肝细胞癌患者的lncRNA表达谱,通过单因素和多因素Cox生存分析,发现并验证了10例与肝细胞癌预后相关的重要lncRNA。根据在这10个lncRNA上建立的风险计算模型,可以将肝细胞癌患者样本分为高风险和低风险组,这两组患者的生存率显着不同。为进一步了解肝细胞癌涉及的分子机制以及改善肝细胞癌患者的诊断,治疗和预后提供了数据[8]。
综上所述,通过与临床数据紧密结合,组学数据在癌症的预后预测和诊断治疗中发挥了重要的作用。
1.3本文的主要工作
本文利用生物信息学和数据分析、挖掘方法,通过对来自TARGET数据仓库中的88例儿童骨肉瘤患者的转录组数据进行分析,找出正常儿童和患病儿童的差异lncRNAs,建立一个基于TARGET数据库转录组数据的儿童骨肉瘤预后预测与临床决策支持模型,然后对有差异的lncRNAs进行单因素和多因素Cox生存分析,进而建立骨肉瘤预测的Cox生存模型,通过建立的Cox生存模型可以按风险情况将患者病情划分,对患者的生存情况进行预测,并对后期医生的临床决策提供支持。
1.4本文的结构安排
论文在结构上共分为五个章节。第一章是论文的绪论,其介绍了针对儿童骨肉瘤进行预后预测的研究背景和意义,表明本论文的目的是为了完善儿童骨肉瘤的预后机制,建立对于医生的临床诊断和药物研发具有帮助的决策支持系统(数据挖掘模块),有助于医生对患者疾病的诊断和预测。第二章是有关基于组学数据的临床决策支持系统的相关介绍,以及基于组学数据的临床决策支持系统的总体设计。第三章是对本文所使用儿童骨肉瘤患者的数据来源的介绍以及进行统计学分析的理论依据。第四章是依照第三章的理论依据进行统计学分析的过程,通过统计学分析得出来的数据建立生存模型并进行进一步的独立性检验。第五章对本文进行总结,指出尚存在的不足之处,并对基于组学数据的临床决策支持系统的未来发展进行展望。
第2章基于组学数据的临床决策支持系统
2.1临床决策支持系统的概念与分类
临床决策支持系统即CDSS(Clinical Decision Support System,CDSS),一般来说,它是指支持临床决策的计算机系统。该系统充分利用现有的计算机技术,通过人机交互的方式解决半结构化或非结构化的医学问题,提高了决策效率[5]。基于计算机的临床决策支持被定义为应用信息和通讯技术为医疗健康带来相关知识的实践活动。临床决策支持系统以决策支持基础可以划分为两类:一类是以知识为决策支持基础的系统称为knowledge-based CDSS;另一类以机器学习等算法或统计类算法为决策支持基础的称为non-knowledge CDSS[9]。
基于知识库的CDSS主要由知识库、推理机和人机交流接口三个部分组成。知识库(Knowledge Base)是知识工程中结构化,易操作,易利用,全面有组织的知识集群,是针对某一领域问题求解的需要,采用某种知识表示方式在计算机存储器中存储、组织、管理和使用的互相联系的知识片集合。这些知识片包括与领域相关的理论知识、事实数据,由专家经验得到的启发式知识,如某领域内有关的定义、定理和运算法则以及常识性知识等。基于CDSS的临床知识库是以患者诊断、主诉、症状、检验、检查、药品、指南和病例报告为基础,通过整合设计,关联知识点,为医生临床诊断提供决策支持以及决策依据,同时方便医生查找相关知识及病例报告,辅助医生临床诊断[10]。
基于非知识库的CDSS系统在一般情况下多采用人工智能的形式。近年来,在CDSS的研究和开发中,这种人工智能被称为机器学习,通过机器学习的方法能够使计算机可以获得经验中以及其他临床数据中存在的知识。机器学习常用的方法有人工神经网络、遗传算法、贝叶斯网络、产生式规则、逻辑条件、因果概率网络等[11]。
这两类临床决策支持系统各有优劣:基于知识库的CDSS由于有了相应专家的专业知识,对于临床诊疗具有更高的准确性,但是其也受限于知识库是有限的,对于知识库外的数据不能提供更好的参考;基于非知识库的CDSS不会受限于知识库的大小,其能够利用人工智能的方法填补缺失数据并可以对数据进行预测。
2.2基于组学数据的临床决策支持系统的研究现状
在高通量测序技术的快速发展下,涌现出了大量的多组学数据,如基因组、转录组、表观组、代谢组和蛋白组等,同时也出现了许多具有代表意义的国际项目,如DNA元件百科全书计划(The Encyclopedia of DNA Elements,ENCODE)[12]和国际人类基因组单体型图计划(Haplotype Map,HapMap)[13]等。随着数据的不断积累和基础研究的不断突破,人类对疾病的诊治迈入了精准医学时代。医生可以结合患者的组学数据[14]、表型数据、临床诊疗数据、电子病历数据及影像数据等从多方面上对疾病进行更为精准、详细的诊断与治疗。在此基础上,一个个优秀的临床决策支持系统如雨后春笋般不断涌现,基于数据分析和数据挖掘的人工智能方法在基础医学研究领域得到了迅速的发展。计算机通过对数据进行数据分析和数据挖掘后,能够从数据中提取有用的信息从而构建成模型,再通过使用大量的数据来提高与完善模型性能,从而达到诊断与预测疾病的预期,最终实现为临床决策支持提供技术支持的目的[15]。
2014年,Han Leng和Yuan Yuan等在研究假基因的表达和临床相关的肿瘤亚型泛癌分析中,为了评估假基因表达谱对于两种子宫内膜样腺癌组织学亚型的预测效力,研究人员使用多种机器学习算法,其中逻辑回归算法得到的假基因表达谱可以准确区分两种组织学亚型,其AUC达到了0.892。在独立测试集上,逻辑回归算法展示出最佳性能,表明利用逻辑回归得到的假基因表达谱能够有效捕捉临床相关信息,获得有意义的肿瘤亚型,帮助医生和患者选择适当的临床治疗方案[16]。
2017年,Xu Rui-Hua等在肝癌的早期筛查模型中,利用肝癌患者和正常人血液样本中的DNA甲基化数据和生存数据,通过随机森林和LASSO等机器学习方法,得到了用于肝癌早期筛查、风险评估和预后监测的模型。在随机森林分析中,利用OOB(out of bag)误差[17]作为最小化准则,从变量森林中进行变量消去,通过设置变量每次迭代的下降分数为0.3,将变量从随机森林中缩减,最终从450000个DNA甲基化位点中筛选出了10个甲基化位点作为生物标志物,进而使用逻辑回归构建了肝癌诊断预测模型,辅助医生进行临床决策。
综上所述,基于组学数据的临床决策支持系统主要增加了对组学数据进行数据挖掘与数据分析的过程。通过增加这个过程,我们能够发现癌症在不同阶段的差异标志物,利用筛选得到的差异标志物进行特征选择并构建癌症诊断预测模型能够帮助医生更加准确地诊断与预测疾病、进行预后预测[18]。
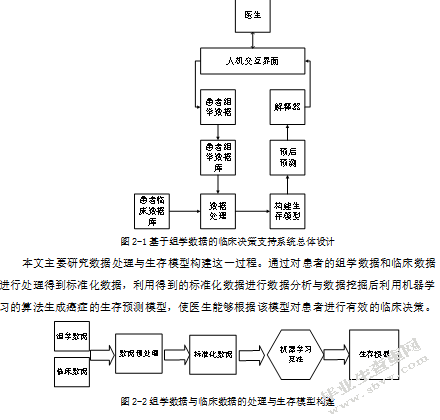
2.3基于组学数据的临床决策支持系统总体设计
基于组学数据的临床决策支持系统主要有人机交互界面、患者组学数据库、患者临床数据库、数据处理机制和解释器构成。
人机交互页面主要是针对医生设计和使用,医生可以通过人机交互页面将患者通过化验等方式得到的组学数据输入到患者组学数据库中,同样,解释器处理后的对临床有用的信息也可以通过人机交互界面较为直接的展示给医生,对医生提供精准的临床决策支持。
患者组学数据库负责存储患者的组学数据,其中包括:基因组学、蛋白组学、转录组学、代谢组学、免疫组学、糖组学和RNA组学等数据。
患者临床信息数据库负责存储患者的临床信息,其中包括:年龄、身高、体重、患病时间、患病部位、患病的阶段与进行的相应治疗等。
数据处理机制的作用是对患者的临床数据和组学数据首先进行标准化,接着采用数据分析和数据挖掘的方法对标准化后的数据进行分析与处理,基于处理后的数据进一步生成风险预测模型,然后利用大量数据对模型进一步完善,以达到提供临床决策支持的目的。
解释器是对数据处理机制得出的结果的进一步解释和说明,对复杂冗余的结果进行简化并筛选出对医生有帮助的数据,方便医生的使用。
图2-1基于组学数据的临床决策支持系统总体设计

第3章数据与方法
3.1数据获取与下载
本文的实验数据来自于TARGET数据库,TARGET数据库针对儿童肿瘤,主要疾病项目包括急性淋巴细胞白血病(Acute Lymphoblastic Leukemia),急性骨髓性白血病(Acute Myeloid Leukemia),肾脏肿瘤(Kidney Tumors),成神经细胞瘤(Neuroblastoma),骨肉瘤(Osteosarcoma)等[19]。
本文通过直接调用R的TCGABiolinks包下载数据,使用GDC官方API下载数据,能够保证数据的及时性和准确性,同时TCGABiolinks包也提供数据整理、聚类分析、差异分析、富集分析等功能。下载完成后共得到88例儿童骨肉瘤患者的数据。
3.2数据预处理
3.2.1数据的筛选
1.首先,对本文所用到的儿童骨肉瘤患者的临床数据进行筛查,由于一些临床因素(如患者的性别,生存状态等)在本次实验中是不可或缺的,我们对缺失这些因素的患者进行剔除,最后剩余86例儿童骨肉瘤患者的临床数据。
2.接着,对本文所用到的儿童骨肉瘤患者的lncRNA的表达数据进行筛查,将下载的lncRNA表达数据与从GENECODE(https://www.gencodegenes.org/releases/22.html)上下载的参考lncRNA进行比对,目的是减少冗余,最后保留至少有25%且表达量≥2的lncRNA,经过筛选后共保留了8457个lncRNA。
3.最后,对本文所用到的儿童骨肉瘤患者的蛋白编码基因的表达数据进行筛查,将整理后的蛋白编码基因与从ENSEMBL(http://uswest.ensembl.org/Help/Faq?id=468)上下载的参考蛋白编码基因(GRCh38)进行对比,去掉ENSEMBL参考蛋白编码基因中没有的蛋白编码基因,经过筛选后共保留了17987个蛋白编码基因。
经过对数据的筛选,本文以86个儿童骨肉瘤患者的临床数据,8457个lncRNA和17987个蛋白编码基因作为研究对象进行研究。
3.2.2数据的处理
首先对临床信息数据和基因表达量信息进行合并,实现合并代码如下:
clin<-clin[clin$bcr_patient_barcode%in%datExpr$bcr_patient_barcode,]
exprSet<-merge(clin,datExpr,by.x="bcr_patient_barcode",by.y="bcr_patient_barcode")
为了保证信息的准确性,合并前首先以基因表达量中的bcr_patient_barcode为基准,在临床信息中提取出基因表达量中存在的所对应bcr_patient_barcode的临床信息,然后再依照bcr_patient_barcode进行对临床信息和基因表达量信息进行合并。
将经过筛选后的全部86个儿童骨肉瘤患者在保证临床信息中的Vital Status较为均衡的前提下(即Vital Status为Alive与Dead的患者在两组中占的比重大致相当)随机分成各包含43个患者样本数据的训练集和测试集。
3.3统计分析(生存分析)
基于随机分组得到的训练集,使用单因素Cox回归分析函数计算lncRNA的表达水平与儿童骨肉瘤患者群体生存之间的关系。单因素Cox回归分析函数的结果的P-Value值如果小于0.001,那么就说明这两者之间存在显著关系,即这些分析结果显著的lncRNAs与儿童骨肉瘤患者的生存状态息息相关。在进行完单因素Cox回归分析之后,利用单因素Cox回归分析得到的显著lncRNAs进行多因素Cox回归分析。在多因素Cox回归分析的过程中,一步选择p值更小的lncRNAs,并记录下这些lncRNAs的风险分数估值以用来构建儿童骨肉瘤患者的生存风险评分公式。通过该公式可以将儿童骨肉瘤患者划分为低风险组和高风险组两类,使用kaplan-meier生存分析曲线可以将这两组不同风险患者的生存预期差异较直观的展示出来。为了进一步验证所筛选的lncRNAs预后分析能力是否独立于其他临床变量如性别等指标,利用多因素Cox回归分析加以验证。
生存分析的主要目的在于研究变量X与观察结果即生存函数(累积生存率)S(t,X)之间的关系。当S(t,X)受很多因素影响,即X=(X1,…,Xm)为向量时,传统的方法是考虑回归方程——即诸变量Xi对S(t,X)的影响。但由于生存分析研究中的数据包含删失数据。且时间变量t通常不满足正态分布和方差齐性的要求,这就造成了用一般的回归方法研究上述关系的困难[20]。
在这里就需要用到比例风险回归模型(Cox回归模型),该模型是由英国统计学家D.R.Cox于1972年提出的一种半参数回归模型。模型可以用来描述了不随时间变化的多个特征对于在某一时刻死亡率的影响,模型的基本形式如下:
h(t,X)=h0(t)exp(β1X1+β2X2+…+βmXm)(公式3-1)
其中,β1,β2,…,βm为自变量的偏回归系数,它是须从样本数据作出估计的参数;h0(t)是当X向量为0时,h(t,X)的基准危险率,它是有待于从样本数据作出估计的量。
3.4富集分析
在这里使用R中的clusterProfiler包对在儿童骨肉瘤发生过程中具有预后作用的lncRNAs与筛选后的17987个蛋白编码基因进行GO(Gene Ontology)功能富集分析和KEGG(Kyoto Encyclopedia of Gene and Genomes)通路分析来进一步研究与儿童骨肉瘤患者生存显著相关的lncRNAs的生物学功能。GO功能富集分析和KEGG通路分析在相关系数p<0.05的前提下进行。
第4章实验结果与讨论
4.1确定生存相关lncRNA
通过将86个来自于TARGET数据库的儿童骨肉瘤患者数据随机分为训练集(n=43)和测试集(n=43)。针对训练集,使用单因素Cox回归模型对数据中包含的所有lncRNAs的单个表达值与患者的生存状况进行分析。最后,选取了18个与儿童骨肉瘤患者预后相关的lncRNAs(p值<0.04;表4-1)。按照风险比(Hazard.Ratio)对这18个lncRNAs进行分析(大于1表示与事件概率正相关的协变量,因此与生存期长度负相关,HR=1:无效;HR<1:减少危害;HR>1:危险增加),发现有9个lncRNAs(ELFN1_AS1、UNC5B_AS1、IGF2BP2_AS1、AC083900.1、PARD6G_AS1、RP11_472M19.2、RP11_597M12.2、CTC_215O4.4、RP11_549L6.3)呈正相关,即这9个基因的表达量越高,对应的儿童骨肉瘤患者的生存期就越短。剩下的9个lncRNAs(RP11_679B19.1、CTD_2269F5.1、RP11_467L19.16、CTD_2341M24.1、RP11_774O3.3、RP11_70D24.2、ACTN1_AS1、RP1_30M3.5、RP11_84G21.1)呈负相关,即这9个基因在生存期较长的儿童骨肉瘤患者中有较高的表达。
表4-1与生存相关的18个lncRNA的信息
| 基因编号 | 基因名称 | 风险比 | CI95 | P.value |
| ENSG00000236081 | ELFN1_AS1 | 1.49 | 1.15-1.93 | 0.002669 |
| ENSG00000237512 | UNC5B_AS1 | 1.47 | 1.03-2.09 | 0.03332 |
| ENSG00000277954 | RP11_679B19.1 | 0.62 | 0.41-0.95 | 0.027777 |
| ENSG00000163915 | IGF2BP2_AS1 | 1.62 | 1.13-2.31 | 0.008218 |
| ENSG00000250320 | CTD_2269F5.1 | 0.6 | 0.41-0.87 | 0.007192 |
| ENSG00000225111 | AC083900.1 | 2.22 | 1.38-3.59 | 0.001103 |
| ENSG00000278626 | RP11_467L19.16 | 0.49 | 0.27-0.88 | 0.016884 |
| ENSG00000258733 | CTD_2341M24.1 | 0.55 | 0.39-0.77 | 0.000609 |
| ENSG00000267270 | PARD6G_AS1 | 1.67 | 1.08-2.57 | 0.019897 |
| ENSG00000251615 | RP11_774O3.3 | 0.51 | 0.3-0.85 | 0.009831 |
| ENSG00000231441 | RP11_472M19.2 | 2.5 | 1.3-4.8 | 0.005834 |
| ENSG00000277621 | RP11_597M12.2 | 1.61 | 1.05-2.46 | 0.028892 |
| ENSG00000278058 | RP11_70D24.2 | 0.55 | 0.32-0.97 | 0.037669 |
| ENSG00000259062 | ACTN1_AS1 | 0.46 | 0.23-0.89 | 0.021524 |
| ENSG00000266936 | CTC_215O4.4 | 2.14 | 1.15-4 | 0.016766 |
| ENSG00000272345 | RP1_30M3.5 | 0.27 | 0.13-0.56 | 0.000434 |
| ENSG00000228417 | RP11_549L6.3 | 2.89 | 1.38-6.08 | 0.004998 |
| ENSG00000257557 | RP11_84G21.1 | 0.35 | 0.18-0.69 | 0.002227 |
为了在训练集中构建儿童骨肉瘤患者预后分析模型,首先对这18个具有预后作用的lncRNA进行了多因素Cox回归分析,经过多轮迭代多因素Cox回归分析,鉴定出了2个与儿童骨肉瘤患者总体存活率显著相关的lncRNA(表4-2)。
表4-2与生存显著相关的2个lncRNA的信息
| 基因编号 | 基因名称 | coef | exp(coef) | se(coef) | z | Pr(>|z|) |
| ENSG00000266936 | CTC_215O4.4 | 0.7334 | 2.0821 | 0.3208 | 2.286 | 0.02224 |
| ENSG00000231441 | RP11_472M19.2 | 0.9258 | 2.5238 | 0.3482 | 2.659 | 0.00784 |
基于这2个预后lncRNA的表达数据和由多因素Cox回归分析产生的预后lncRNA的回归系数构建儿童骨肉瘤生存预测的风险值评分公式。公式如下:
Riskscore=lncRNA1×coef1+lncRNA2×coef2公式(4-1)
其中风险值由这2个lncRNA的表达量与多因素多因素Cox回归分析产生的预后lncRNA的回归系数coef乘积之和计算。
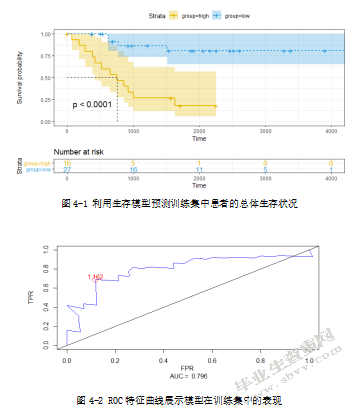
根据由这2个lncRNA构建的儿童骨肉瘤预后分析模型,计算训练集中的每位患者的风险值,然后根据风险值大小按顺序进行排列。由风险中位数作为阈值,将训练集中的43位患者分为高风险组(n=16)和低风险组(n=27)两组并用Kaplan-Meier曲线(图4-1)展示这2个组的患者的生存状态。Kaplan-Meier生存分析表明高风险组患者与低风险组患者的生存状况存在非常显著差异(p值<0.0001)。低风险患者的生存时间明显比高风险组患者长。低风险组中患者1000、2000、3000天的总体生存率分别为59%、41%、19%;而高风险组中患者在1000、2000、3000天的总体生存率分别为31%、6%、0%。为了评估由这两个2个预后lncRNA建立的儿童骨肉瘤生存模型的性能,对模型进行ROC(Receiver Operating Characteristic)曲线分析,得到该模型的AUC值为0.796(图4-2),进一步说明本次构建的预后分析模型在预测儿童骨肉瘤患者2500天内的生存时间比较准确。
4.3模型整体验证
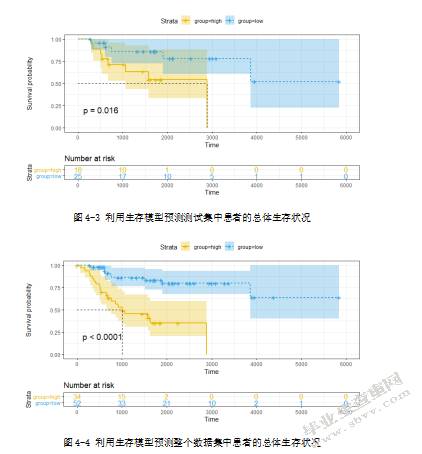
基于儿童骨肉瘤患者生存相关的lncRNAs的生存分析模型在训练集中有较好的表现,为了进一步验证该生存模型的表现,使用类似的方法在测试集中进行测试。计算测试集中的每位患者的风险值,然后根据风险值大小按顺序进行排列。由风险中位数作为阈值,将测试集中的43位患者分为高风险组(n=18)和低风险组(n=25)两组并用Kaplan-Meier曲线(图4-3)展示这2个组的患者的生存状态。Kaplan-Meier生存分析表明高风险组患者与低风险组患者的生存状况存在显著差异(p值=0.016)。与训练集中相同,低风险患者的生存时间明显比高风险组患者更长。低风险组中患者1000、2000、3000天的总体生存率分别为68%、40%、20%;高风险组中患者1000、2000、3000天的总体生存率分别为56%、6%、0%。在整个数据集中进行验证也得到相似的结果(图4-4),在全部的数据集中,将患者分为高风险组(n=34)和低风险组(n=52),同样高风险组患者的生存期明显较低风险患者短。为了评估由这两个2个预后lncRNA建立的儿童骨肉瘤生存模型的性能,在此也对测试集与整个数据集进行ROC(Receiver Operating Characteristic)曲线分析,得到该模型的AUC值为0.726与0.777。说明了这个生存计算模型在不同的数据集中都有较好的表现
4.4模型独立性验证
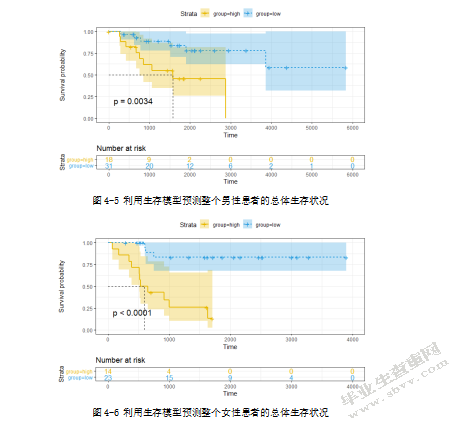
为了验证构建的生存分析模型对儿童骨肉瘤患者的生存分析的独立性,在这里对整个数据集按照性别进行分组。整个数据集的儿童骨肉瘤患者被分为男性组(n=47)以及女性组(n=39),将这两个数据集分别用构建的生存分析模型进行预后分析,发现该生存模型依旧能将男性组与女性组的患者划分为高风险和低风险两种类别,且具有较显著的差异(图4-5,p值=0.0034、图4-6,p值<0.0001)。通过该分析结果可以证明,基于骨肉瘤患者的生存分析模型具有较高的独立性,能够准确地对不同性别患者生存期进行估计。
4.5富集功能分析
上文中通过一系列的分析与验证,发现基于儿童骨肉瘤患者生存相关的lncRNAs建立的生存预测模型具有良好的预后预测的能力。为了进一步弄清楚儿童骨肉瘤患者生存相关的lncRNAs在儿童骨肉瘤发生的过程中发挥什么样的作用,进行了富集功能分析。首先进行筛选工作,针对基因的表达量进行过滤,过滤标准设置为:至少有25%的样本,基因的表达量大于2。筛选后,利用R中的clusterProfiler包(该软件包实现了分析和可视化基因与基因簇的功能概况(GO和KEGG)的方法)对基因进行功能富集分析和结果可视化(图4-7、图4-8、图4-9、图4-10)。在这里以筛选后显著的hsa04910通路为例进行KEGG通道富集可视化分析,并在pathway通路图上标记富集到的基因(图4-11)。通过以上的分析,可以发现在各个过程显著的基因,从而研究具有预后价值lncRNA的蛋白编码基因在癌症中起的作用。
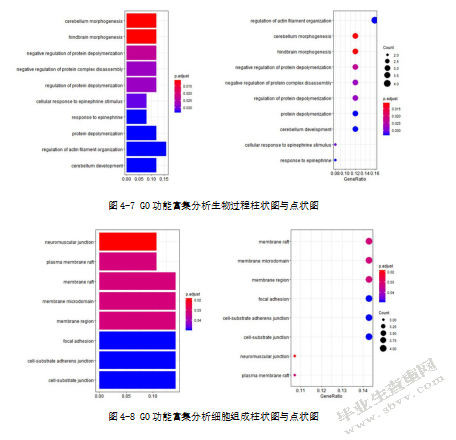
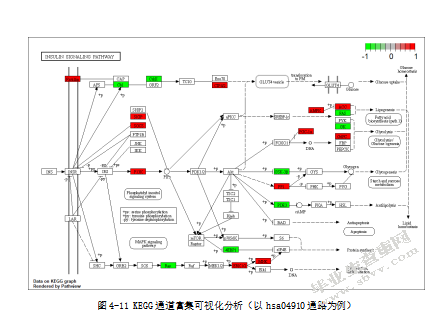
4.6讨论
lncRNA在肿瘤的产生与发展中起着重要的作用,其能通过调控重要的癌基因或抑癌基因,进而参与细胞的恶化和肿瘤的发生[21]。许多研究表明lncRNA的异常表达可以作为诊断和预后的独立生物标志物,进而判断病人是否患癌症[22-24]。近年来,有许多研究针对其他预后相关的lncRNA进行分析研究,从而建立起相应癌症的预后预测模型对患者进行预后预测[3,6,7,8],对患者的临床决策提供了有效的支持,但是尚未有研究对儿童骨肉瘤建立相应的预后预测模型进行预后预测与决策支持。因此,建立有效的风险预测模型对儿童骨肉瘤患者的临床决策具有重要作用。
本章对儿童骨肉瘤患者的临床数据和匹配的lncRNA的表达数据进行分析,发现了与儿童骨肉瘤预后相关的2个lncRNA,经过验证,发现基于这2个预后lncRNA建立的风险值预测模型可以有效地分析儿童骨肉瘤患者的预后情况。通过ROC曲线分析,其预后分析的性能是可靠的,所以基于这2个lncRNA建立的风险预测模型可以有效地分析儿童骨肉瘤患者的预后情况。
同时,经过模型的独立性验证,通过分析得到的预后相关的lncRNA能够独立于其他临床数据(如性别等)发挥作用。
结语
通过从TARGET数据库下载的儿童骨肉瘤患者的临床数据和lncRNA的表达数据进行分析,确定了2个与儿童骨肉瘤患者预后相关的lncRNA,基于这2个lncRNA建立的风险预测模型可以有效地对儿童骨肉瘤患者的生存时间进行估算。通过对转录组数据和儿童骨肉瘤患者的临床数据结合进行分析,更加深入的了解到lncRNA的差异表达与癌症患者生存之间的关系,通过该过程建立的风险预测模型能够得到充分的统计学分析结果的支持。
论文研究还有以下不足和改进之处。首先,本文所使用的来自TARGET数据库的儿童骨肉瘤患者的转录组数据和临床数据,如果能使用其他数据平台的儿童骨肉瘤患者的转录组数据和临床数据进行多重验证可以使分析结果更为准确。其次,本次数据的样本数量较少,可用的只有86例儿童骨肉瘤患者的转录组数据和临床数据,过少的样本数量构建的风险预测模型在实际应用中可能会遇到分析的结果不如在全部数据集中测试的准确。最后,对于本次研究使用的转录组数据和临床数据如果进行验证,可以使本次研究的结果更加准确。
参考文献
[1]陆军军医大学陆军特色医学中心肿瘤科副教授金丰谷一整理.骨肉瘤为何放疗效果差[N].健康报,2019-12-19(008).
[2]范璐,臧俊亭,冯娜,王鑫众.骨肉瘤化疗及耐药分子机制的研究进展[J].癌症进展,2019,17(21):2495-2497+2555.
[3]常奇.基于多组学数据的癌症患者生存期预测研究[D].大连海事大学,2017.
[4]王宇,王心慰,刘爽,杨之辉,朱卫国,弓孟春.精准医学的临床部署:顶层架构设计及关键信息技术[J].转化医学杂志,2017,6(06):321-324.
[5]马广煜.基于临床组学信息融合的EHR决策支持系统研究[D].哈尔滨工业大学,2016.
[6]Weigel Marion T,Dowsett Mitch.Current and emerging biomarkers in breast cancer:prognosis and prediction.[J].Endocrine-related cancer,2010,17(4).
[7]赵学彤,杨亚东,渠鸿竹,方向东.组学时代下机器学习方法在临床决策支持中的应用[J].遗传,2018,40(09):693-703.
[8]X.Fang,N.Liu,Y.Du,F.Yuan and Y.Li,"A Ten-Long Non-Coding RNA Model Improves Prognosis Prediction of Hepatocellular Carcinoma Patients,"2018 9th International Conference on Information Technology in Medicine and Education(ITME),Hangzhou,2018,pp.29-33.doi:10.1109/ITME.2018.00018
[9]https://baike.baidu.com/item/CDSS/386665?fr=aladdin.
[10]井立强,王艳萍,焦敬义,陈洪林.基于CDSS临床知识库应用与实践[J].中国卫生信息管理杂志,2015,12(02):176-182.
[11]李军莲,陈颖,邓盼盼,任慧玲.国外基于人工智能的临床决策支持系统发展及启示[J].医学信息学杂志,2018,39(06):2-6.
[12]王昱.基于电子病历数据的临床决策支持研究[D].浙江大学,2016.
[13]Qu HZ,Fang XD.A brief review on the human encyclopedia of DNA Elements(ENCODE)project.Genomics Prot Bioinform,2013,11(3):135–141.
[14]Altshuler DM,Gibbs RA,Peltonen L,Altshuler DM,Gibbs RA,Peltonen L,Dermitzakis E,Schaffner SF,Yu F,Peltonen L,Dermitzakis E,Bonnen PE,Altshuler DM,Gibbs RA,de Bakker PI,Deloukas P,Gabriel SB,Gwilliam R,Hunt S,Inouye M,Jia X,Palotie A,Parkin M,Whittaker P,Yu F,Chang K,Hawes A,Lewis LR,Ren Y,Wheeler D,Gibbs RA,Muzny DM,Barnes C,Darvishi K,Hurles M,Korn JM,Kristiansson K,Lee C,McCarrol SA,Nemesh J,Dermitzakis E,Keinan A,Montgomery SB,Pollack S,Price AL,Soranzo N,Bonnen PE,Gibbs RA,Gonzaga-Jauregui C,Keinan A,Price AL,Yu F,Anttila V,Brodeur W,Daly MJ,Leslie S,McVean G,Moutsianas L,Nguyen H,Schaffner SF,Zhang Q,Ghori MJ,McGinnis R,McLaren W,Pollack S,Price AL,Schaffner SF,Takeuchi F,Grossman SR,Shlyakhter I,Hostetter EB,Sabeti PC,Adebamowo CA,Foster MW,Gordon DR,Licinio J,Manca MC,Marshall PA,Matsuda I,Ngare D,Wang VO,Reddy D,Rotimi CN,Royal CD,Sharp RR,Zeng C,Brooks LD,McEwen JE.Integrating common and rare genetic variation in diverse human populations.Nature,2010,467(7311):52–58.
[15]谢兵兵,杨亚东,丁楠,斱向东.整合分析多组学数据筛选疾病靶点的精准医学策略.遗传,2015,37(7):655–663.
[16]Han Leng,Yuan Yuan,Zheng Siyuan,Yang Yang,Li Jun,Edgerton Mary E,Diao Lixia,Xu Yanxun,Verhaak Roeland G W,Liang Han.The Pan-Cancer analysis of pseudogene expression reveals biologically and clinically relevant tumour subtypes.[J].Nature communications,2014,5.
[17]Diaz-Uriarte Ramón.GeneSrF and varSelRF:a web-based tool and R package for gene selection and classification using random forest.[J].BMC bioinformatics,2007,8.
[18]Xu Rui-Hua,Wei Wei,Krawczyk Michal,Wang Wenqiu,Luo Huiyan,Flagg Ken,Yi Shaohua,Shi William,Quan Qingli,Li Kang,Zheng Lianghong,Zhang Heng,Caughey Bennett A,Zhao Qi,Hou Jiayi,Zhang Runze,Xu Yanxin,Cai Huimin,Li Gen,Hou Rui,Zhong Zheng,Lin Danni,Fu Xin,Zhu Jie,Duan Yaou,Yu Meixing,Ying Binwu,Zhang Wengeng,Wang Juan,Zhang Edward,Zhang Charlotte,Li Oulan,Guo Rongping,Carter Hannah,Zhu Jian-Kang,Hao Xiaoke,Zhang Kang.Circulating tumour DNA methylation markers for diagnosis and prognosis of hepatocellular carcinoma.[J].Nature materials,2017,16(11).
[19]吕敏,田国祥,郭晓娟,李豹,张军,吕军.TARGET数据库的介绍及数据提取[J].中国循证心血管医学杂志,2019,11(04):387-390.
[20]景学安主编;段爱旭,孔浩副主编.医学统计学供临床医学、预防医学、口腔医学、医学影像学、医学检验学等专业用:江苏科学技术出版社,2013.01
[21]梁炜,潘磊,付敏,钱晖,许文荣,张徐.LncRNA在肿瘤及微环境中的作用研究进展[J].临床检验杂志,2016,34(05):329-331.
[22]胡雪刚.一种新型的长链非编码RNA,AC012456.4,作为口腔鳞状细胞癌生存的独立预后生物标志物[C].中华口腔医学会口腔病理学专业委员会.2018口腔病理年会暨第十二次全国口腔病理学术会议论文集.中华口腔医学会口腔病理学专业委员会:中华口腔医学会,2018:36-37.
[23]范志远,刘炳亚,朱正伦,严超,刘文韬,燕敏.基于基因表达谱分析的胃癌诊断及预后相关长链非编码RNA谱识别及鉴定[J].临床与病理杂志,2015,(z1):65-65.
[24]田如月,郭水龙,曹邦伟.基于TCGA数据库筛选与胃癌预后相关的差异基因[J].临床和实验医学杂志,2020,19(05):449-452.
下载提示:
1、如文档侵犯商业秘密、侵犯著作权、侵犯人身权等,请点击“文章版权申述”(推荐),也可以打举报电话:18735597641(电话支持时间:9:00-18:30)。
2、网站文档一经付费(服务费),不意味着购买了该文档的版权,仅供个人/单位学习、研究之用,不得用于商业用途,未经授权,严禁复制、发行、汇编、翻译或者网络传播等,侵权必究。
3、本站所有内容均由合作方或网友投稿,本站不对文档的完整性、权威性及其观点立场正确性做任何保证或承诺!文档内容仅供研究参考,付费前请自行鉴别。如您付费,意味着您自己接受本站规则且自行承担风险,本站不退款、不进行额外附加服务。
原创文章,作者:写文章小能手,如若转载,请注明出处:https://www.447766.cn/chachong/15219.html,