摘要:淘宝网站作为国内最大的电子商务平台,拥有庞大的消费群体和海量的交易数据。如何对淘宝商务平台上大量的数据进行有效的收集、组织、挖掘和利用,找出其中真正有价值的信息和知识,以指导企业的商业决策行为,成为电子商务经营者关注的问题。关联规则作为数据挖掘技术(DataMining)中最为典型的一种,为解决这一问题提供了有效途径。通过关联规则挖掘,找出商品之间、商品与客户之间存在的内在联系,对于电子商务中客户关系管理、企业市场定位和商品营销有着非常重要的指导意义。针对目前淘宝平台中客户购物数据的利用问题,阐述了关联规则挖掘的一般过程,并对采集的相关记录数据进行关联分析,依据分析结果制定相应的营销策略。
关键词:电子商务;数据挖掘;关联分析
一、引言
近些年来电子商务迅猛发展,给人们生活带来了很多便利,同时也带来了不少难题和挑战。对于企业来说,进行电子商务转型和发展,需要有互联网思维,即能够从海量的交易信息中找出有用的、有潜在价值的信息,以制定更好的经营策略;对于消费者来说,需要花费大量的时间和精力来浏览网上大量的商品信息,并从中比较和选购商品。关联规则是数据挖掘技术中的一种,它可以反映大量数据间特有的联系,并将这种联系转化为数据使用者感兴趣的信息,为企业或消费者提供决策支持。
用户网上交易的原始数据是海量的,我们可以从电子商务交易中提取,也可以从百度指数和阿里指数等获得。淘宝数据魔方、量子恒道和SAS等数据挖掘分析工具能够帮助企业对这些数据进行处理。目前电子商务平台中关联规则挖掘的普及度和专业度不高,无法深入提取数据中更优质的信息,并借助这些信息去分析和发现客户的消费习惯和行为模式,从而改进营销决策和客户服务。论文针对关联规则技术在淘宝交易数据中的应用,实现指定支持度和置信度下,交易数据中关联规则的挖掘,并对提取到的规则进行分析,与淘宝商务平台现状结合,制定相应的营销策略。
二、客户购物关联分析
(一)关联分析技术
使用数据挖掘中的关联规则技术来对客户购物关联进行分析,能够把隐没在一大批看似杂乱无章的数据中的信息,集中、萃取和提炼出来,以找出所研究对象的内在规律。在互联网时代发展到大数据时代,数据呈现指数级增长。然而,百分之八十的数据是非结构化的,因此需要通过关联挖掘从数据库中存储的数据项中,找出数据中结构化的、隐藏的联系。这些数据联系中的交叉性信息反应隐含了客户的潜在购买行为,对电子商务企业的营销决策有着非常重要的价值。
购物分析是关联规则的一个典型案例。指的是当顾客购买一些商品A,B,C,D…它们一起购买是偶然,还是顾客的购买行为习惯?商品A和B同时购买的概率有多大?如果两者捆绑销售是否会刺激顾客消费?了解了顾客的购买行为,能够帮助企业制定市场营销策略。例如,什么样的商品应该放在一起,企业的顾客群体特征,顾客为什么购买这些商品。在制定商品策略和优化客户服务时,根据顾客需求,实施精准营销。
关联规则挖掘的基本模型如图1所示:
图1关联规则挖掘的基本模型
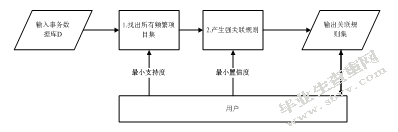

(1)输入事务数据库D,根据最小支持度找出其中所有的频繁项目集。
(2)由(1)中的频繁项目集和最小置信度产生强关联规则,在一定情况下,也可以通过附加兴趣度来对规则进行度量。
第一个子问题的核心是如何确定有效的支持度,以找出D中所有频繁项目集。支持度是事务数据库D中包含项集X的事务数与事务数据库D的总事务数的比值,一般支持度越高越好,但是在实际关联挖掘时,需要根据业务需求不断调整、尝试,才能找到最合适的支持度;第二个子问题可以直接得到结果,但也需要根据不同的求解指标如兴趣度的度量标准来进一步度量关联规则集的合理性。
(二)客户购物关联挖掘过程
1.确定业务问题
客户购物关联挖掘的主要价值应该是决策或者辅佐决策,因此评价关联分析的原点是能否满足业务需求,解决存在的业务问题。深入理解业务本身,是避免迷失在大量数据中的前提。针对电子商务平台,这里所说的业务问题可以是流量转化、活动营销、关联销售、会员提升等。不同业务的关键需求决定了关联分析的目标用户和目标价值。
2.数据探测
在确定业务问题后就要选择相关的数据,有效挖掘的关键问题有:数据来源、数据量、数据存储、数据平衡和数据转换。数据来源通常是淘宝商务平台的消费者交易数据和流量数据。数据量并不是越大越好,要以效用为导向,以实用价值为指标,结合不同的阶段性目标,进行数据采集分析。具有一定规模的企业或公司会有自己的数据库来存储海量数据,对于规模很小的店铺或个人创业等,可以借助电商平台如淘宝指数,或利用数据库软件如Oracle,SQLServer,IBMDB2,MySQL等,来存储和有组织的管理各种网站流量数据和客户购物交易数据。数据平衡是结合每个企业自身实际,规划设计数据表的特点和结构。很多情况下数据的质量难以保证,充分的数据探测是为了了解数据的分布、变化趋势和数据关系。将非结构化的数据转化可理解的、可用的结构化数据,即对应的分布与统计信息,有助于全面了解数据特征,并建立客户购物关联挖掘模型。
3.数据预处理
数据预处理有助于为客户购物关联分析提供高质量的数据。现实中数据大体上是不完整的、不一致的脏数据,无法直接进行关联分析,需要进行清理、集成、变换和归约,来纠正各种数据质量问题,否则可能会影响客户购物关联分析得到的结果。
4.数据建模(挖掘)
对于电商平台的客户购物关联分析需要选择关联规则方法,结合商务智能分析软件如WEKA、SQLServer、IBMcognis等对相应的数据进行挖掘分析。
5.结果评估
关联分析后会输出许多模式,对相关模式的合理性进行测试和评估是必要的。企业认可的与消费者认可的结果不一定相同,甚至可能是相悖的。这个阶段与业务人员的充分沟通、比对网站的交易数据是保证其效用最大化的有效途径。
6.应用部署
将分析的关联结果应用到商务决策中,在客户关系管理、个性化推荐、商品营销、提高转化率等方面,制定具体的、可执行的、可管控的战略实施计划,以产生经济效益。
三、淘宝商务平台数据分析
淘宝商务平台中的数据,信息量巨大,结构复杂,类型众多。对购物数据的分析,不再局限于商品名称、商品类型、商品价格和交易时间,也包括购买商品的客户信息。很多商家只是把这些交易信息当作一个展示页面,但基于交易数据的关联规则挖掘还是不够深入,缺乏专业的挖掘工具和分析工具以及专业的分析人员对这些信息的潜在性进行挖掘和分析。
(一)分析对象
淘宝商务平台中的商品品种繁多,价格相对便宜,支付方便,易于消费者选购,深受广大网络消费者的欢迎,淘宝中的客户购物数据庞大,关联性高,蕴含的信息多。所以本文选取淘宝商务平台中305个用户在淘宝天猫超市中交易记录,来挖掘潜在的、有价值的信息。
首先可以利用图表看一下这些记录展示出来的数据信息。

图3职业分布柱状图
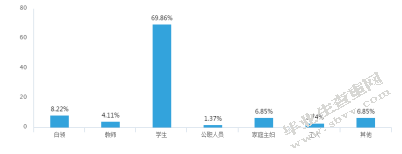
由图2、图3可以得出,天猫的消费人群与淘宝网相比,更偏女性化,即女性消费者占比更高;学生群体消费比重大,可以看出目前网络消费者总体较为年轻;消费人群学历水平整体较高。
图4购买类目柱状图
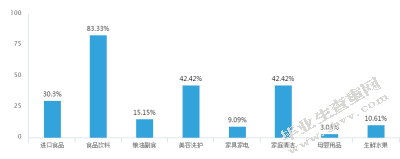
从购买类目上看,购买进口食品的可能性值是30.3%,购买食品饮料的可能性值是83.33%,购买油粮副食的可能性值是15.15%,购买美容洗护的可能性值是42.42%,购买家具家电的可能性值是9.09%,购买家庭清洁的可能性值是42.42%,购买母婴用品的可能性值是3.03%,购买生鲜水果的可能性值是10.61%,食品饮料、美容洗护、家庭清洁排在前三位,这与调查人群中女性占比例大,学生、家庭主妇、白领职业分布比重高有很大的关系。
图5购买原因柱状图
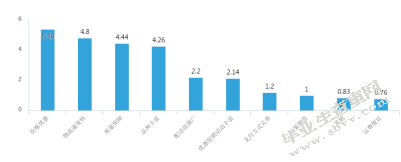
在购买原因中,价格优惠的认可度是5.38,物流速度快的认可度是4.8,质量保障的认可度是4.44,品种丰富的认可度是4.26,配送范围广的认可度是2.2,优惠促销活动丰富的认可度是2.14,支付方式完善的认可度是1.2,包装规范的认可度是1,其他的认可度是0.83,运费便宜的认可度是0.76。由此说明价格、物流、商品质量、品种数量等因素对客户购买决策的影响很大。
图6受吸引的优惠活动柱状图
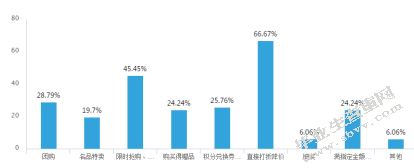
对消费者而已,最受吸引的优惠活动中,直接打折降价吸引度为66.67%,限时抢购、低价秒杀吸引度为45.45%,团购吸引度为28.79%,积分兑换券、抵用券吸引度为25.76%,满指定金额包邮、礼品卡和购买得赠品吸引度为24.24%,名品特卖吸引度为19.7%,抽奖和其他吸引度为6.06%。直接打折降价虽然是比较传统的优惠活动,消费者尤其是女性消费者会对这类活动乐此不疲,所以淘宝商务平台经常会在各种节假日开展优惠活动。
以上是部分展示出来的数据信息,这些数据信息比较单一,为商家的决策提供的价值有限,无法提供更深层次的、隐藏的信息,所以需要通过关联分析将企业面临的业务问题和研究的分析框架相结合,推导出具有实用价值的结论。
(二)数据准备
将原始数据中与客户特征、使用情况等信息保存为用户信息表(tb_user),与购买商品有关的保存为商品购买表(tb_good),以Oracle数据库为载体记录相关表格。两表的部分信息如下:
表1用户信息表
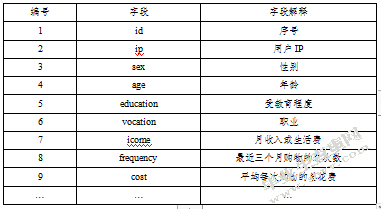
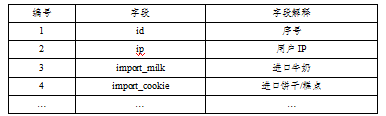
表2商品购买表
(三)数据处理
原始的数据通常由于主、客观原因,会包含异常数据、错误数据或重复数据,是不能直接进行关联分析的,因此必须进行数据预处理。
1.数据选择
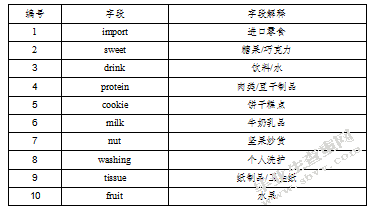
首先是筛选用户信息表,用户的性别、年龄、受教育程度、月收入或生活费、最近三个月购物的总次数、平均每次购物的总花费等属性,这些属性能够预测顾客的购买行为,对推荐产生作用;而次要属性比如序号,用户IP等属性对于统计分析是必要的,但是关联分析可以删除。对于商品购买表,客户购买的产品涉及50种,要从中选取出购买频率高的前10位产品,所以先做一个简单的统计,然后筛选下能够进行关联分析的购买相对较多的产品。选择后两表的字段如下:
表3数据选择后用户信息表
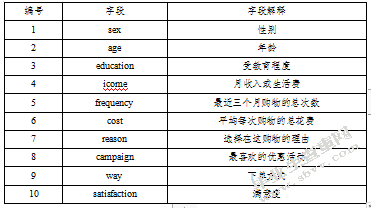
表4数据选择后商品购买表
2.数据清理
数据清理以提高数据质量为目标,将数据质量提高到挖掘技术所要求的水平。去掉不完整的数据和噪声数据,提高数据挖掘结果的质量。例如将一行记录中全是空值的记录,残缺的记录去除,以方便进行数据挖掘。清理后最终留下300条记录。
3.数据转换
主要是对数据进行规格化操作,来适应关联分析工具和相应的算法。常用的开源挖掘工具如WEKA、RapidMiner、NLTK、Orange等,需要将字符集转换为英文,否则可能出现乱码的情况。常见的关联规则算法,如Apriori算法是布尔类型的算法,原始数据表格中所使用的字段,数据类型不一的,需要进行转化成相应的布尔类型:
(1)量化属性离散化:对于数值类型的属性,需要进行离散化处理,先进行最大最小值统计,对于如果最大值是离群点,可以选择相对正常的较高值作为最大值,再划分为几个区间。例如用户信息表中的“月收入或生活费、最近三个月购物的总次数、平均每次购物的总花费”字段就是数值属性。根据取值的分布规律,我们将月收入或生活费其划分为五个组,分别是0-1500(1)、1501-3000(2)、3001-5000(3)、5001-10000(4)和10001-20000(5)。将最近三个月购物的总次数分成三个组,分别是0-2次(1),3-5次(2),5次以上(3),将平均每次购物的总花费分成6个组,分别是50元及以下(1),51-100元(2),101-300元(3),301-500元(4),501-1000元(5),1000元以上(6)。
(2)类别属性转化:用户户信息表中的“性别”字段,需要转化为M(男)和F(女)这样的布尔型;“受教育程度”可分为college(大专及以下)、undergraduate(本科);“选择在这购物的理由”可分为price(价格优惠)、pay(支付方式完善)、logistics(物流速度快)、quality(质量保障)、variety(品种丰富)、promotion(优惠促销活动丰富)。“最喜欢的优惠活动、下单方式、满意度”三个字段按照以上方式依次进行类别布尔转换。
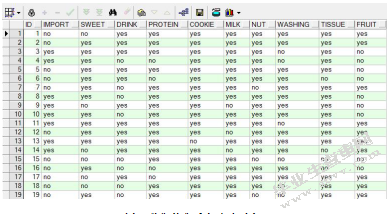
对于商品购买表,需要处理为布尔矩阵格式,即每行表示一条交易记录,列中的yes/no值表示这条记录中顾客是否购买了该商品,并不考虑各个商品自身的价格、购买单位等。最终完成转化的表部分数据如下:
图7数据转化后用户信息表
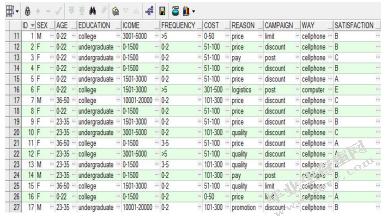
图8数据转化后商品购买表
(四)关联挖掘
本文将使用挖掘工具WEKA来进行关联挖掘。WEKA的全名是怀卡托智能分析环境,是一款开源数据挖掘软件,集合了大量数据挖掘算法和数据处理功能,关联规则是其中典型的一种。
点击启动运行WEKA软件后,发现WEKA存储数据的格式是ARFF文件。除了ARFF格式,WEKA还支持另外一种常见格式,CSV格式。而对于保存在数据库中的数据,WEKA支持JDBC访问数据库。具体的挖掘过程如下:
1.导入数据
环境:
(1)主机:Weka3.8,PL/SQL,ojdbc14.jar
(2)VMwareWorkstation:Oracle11g
连接步骤:
(1)安装weka软件,完成后将oracle的架包ojdbc14.jar放到weka安装目录(D:/ProgramFiles/Weka-3-8/)下;
(2)打开D:/ProgramFiles/Weka-3-8/weka.jar这个文件,修改文件weka.jar-weka-experiment-DatabaseUtils.props.oracle,指定虚拟机中的oracle数据库为连接的jdbc,设置相应的数据库的URL、端口号和数据库名:“jdbcURL=jdbc:oracle:thin:@192.168.163.3:1521:XE”,然后将文件另存为DatabaseUtils.props,删除安装目录下的原文件。
(3)打开D:/ProgramFiles/Weka-3-8/目录下的runweka.ini文件,找到最后一行,设置环境变量:
cp=%CLASSPATH%;D:/ProgramFiles/Weka-3-8/lib/ojdbc14.jar。
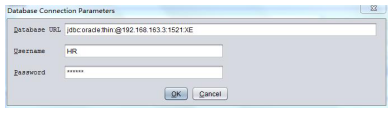
(4)重新启动weka,选择进入Explorer应用,以OpenDB方式载入SQL-Viewer界面,此时Connection-URL文本框中已经自动设置为DatabaseUtils.props中的值“jdbc:oracle:thin:@192.168.163.3:1521:XE”,点击User按钮,设置数据库连接的Username和Password,分别为HR和123456。如图9所示
图9数据库连接配置
点击OK后连接,如果连接成功,Info下会显示提醒信息。
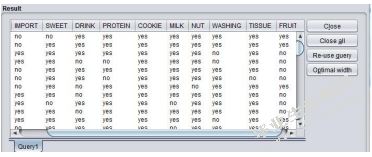
(5)在Query窗口中根据查询需要输入SQL语句“select*fromtb_user”和“select*fromtb_good”,点击“Execute”按钮执行,可在“Result”框下看到对应的表格数据。如图10所示
图10查询的结果集
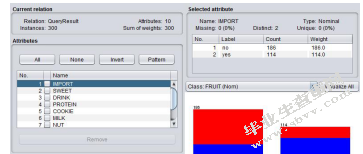
(6)点击“OK”按钮即可导入。如图11所示
图11数据导入完成
2.关联规则分析
作关联规则的分析,将WEKA切换到“Associate”选项卡。可选择的算法有Apriori、FilteredAssociator、FPGrowth,默认使用Apriori算法。如果发现该算法呈现灰色不能点击,可能是数据不符合类型,需要重新调整数据。
关联规则是形如L->R的规则,它的重要指标支持度(Support)和置信度(Confidence),描述了其有用性和确定性。对于客户购物关联分析来说,支持度s(L->R)就是购买了一些商品中同时观察到商品L和R的概率,而置信度就是所有购买了L商品的记录中时L和R的同时存在的概率。支持度和置信度都较高的规则实用价值比较高。
Apriori算法的基本思想是先设置最小支持度和最小置信度,通过对n条记录产生候选频繁项集进行支持度和置信度进行计算,将满足最小支持度和最小置信度的项集保留下来,作为新的记录,再次产生候选频繁项集。通过迭代,最后记录中所有满足要求的频繁项集就是关联规则。
点击“Choose”右边的文本框修改默认的参数,计划挖掘出最小支持度(lowerBoundMinSupport)为20%,并且最小置信度(minMetric)为90%的关联规则。将“metricType”设为confidence,其他参数不变。如图12所示
图12支持度、置信度设置

点击“start”得到结果如下:
图13用户信息关联结果
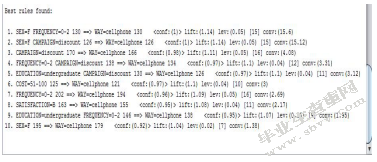
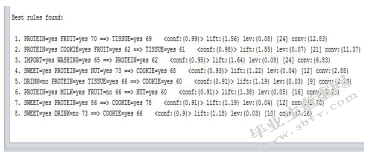
图14商品购买关联结果
(五)关联结果分析
Apriori算法的参数,设置最小支持度为20%,最小项集大小为0,这两项值可根据实际情况进行设置。通过关联规则算法找到了那些频繁项目集,每一条对应的可得到的结论为:
1.用户信息表
(1)性别为女,购买频率在0-2次的人,下单方式为手机的概率为100%;
(2)性别为女,喜爱的优惠活动为直接打折降价的人,下单方式为手机的概率为100%;
(3)喜爱的优惠活动为直接打折降价的人,下单方式为手机的概率为98%;
(4)购买频率在0-2次,喜爱的优惠活动为直接打折降价的人,下单方式为手机的概率为97%;
(5)受教育程度为本科,喜爱的优惠活动为直接打折降价的人,下单方式为手机的概率为97%;
(6)平均每次在天猫超市购物的总花费为51-100元的人,下单方式为手机的概率为97%;
(7)购买频率在0-2次的人,下单方式为手机的概率为96%;
(8)满意度为“基本能满足”的人,下单方式为手机的概率为95%;
(9)受教育程度为本科,购买频率在0-2次的人,下单方式为手机的概率为95%;
(10)性别为女,下单方式为手机的概率为92%;
2.商品购买表
(1)购买了肉类/豆干制品并且购买了水果的人,会购买纸制品/卫生纸的概率为99%;
(2)购买了肉类/豆干制品、饼干糕点和水果的人,会购买纸制品/卫生纸的概率为98%;
(3)购买了进口零食并且购买了个人洗护的人,会购买肉类/豆干制品的概率为95%;
(4)购买了糖果/巧克力、肉类/豆干制品和坚果炒货的人,会购买饼干糕点的概率为93%;
(5)不购买饮料/水但购买肉类/豆干制品和纸制品/卫生纸的人,会购买饼干糕点的概率为91%;
(6)购买了肉类/豆干制品、牛奶乳品但没有购买水果的人,会购买坚果炒货的概率为91%;
(7)购买了糖果/巧克力和肉类/豆干制品的人,会购买饼干糕点的概率为91%;
(8)购买了糖果/巧克力但没有饮料/水的人,会购买饼干糕点的概率为91%。
这些结论和目前已经得到日常客户购买的情况是一致的,可以作为重要参考,这证明了关联规则算法在淘宝商务平台客户购物中的有效性。
四、淘宝商务平台中的关联规则应用
(一)客户分析
根据关联结果,找出顾客群体的特征,依据特征,进行客户细分,实现精准营销。
表5客户特征组合表

根据以上特征可以对营销策略做出几点改进:
(1)提高顾客的购买兴趣。由关联结果可知购买频率在0-2次,每次花费在51-100元的女性顾客通过手机下单的概率高,为了提高购买频率和刺激顾客的购买兴趣,可以对这些购买频率低的顾客推送一些快速浏览、即兴需求的并且有优惠活动的商品,以适应移动端购物的特点。“直接打折降价”能直接的利用顾客对价格的敏感心理,促使顾客做出购买的决定。像"特价只剩24小时!"这样的限期供应,能够帮助激发消费者的购买欲。但是要真实,否则最终失去消费者信任。
(2)让顾客能较长时间的停留浏览商品。客户群体中女性占比大,学生、家庭主妇较多,这就不仅仅是标题的是否吸引人的问题。在这里针对她们的购买习惯,对商品详情的描述非常关键,要尽量采用实地拍摄的商品图片,少用官方图片,以提高顾客对商家的信任度;还要有详细的文字说明,不能几个字草草了事;对于商品属性和规格的描述要尽可能的详细;使用相关模板并利用Photoshop对图片进行编辑等,以提高其美观度来吸引顾客的眼球。
(3)让新顾客变成老顾客。事实证明,网店留住老顾客比开发新顾客要重要的多,前者的成本也要远低于后者。这里要充分利用顾客的情感,让顾客感觉到一丝温馨。比如在发货时,根据商品搭配一个小礼品,给顾客一个惊喜;在节假日,通过短信、邮件等工具送去温馨的祝福,同时可以根据顾客的消费频率和每次消费金额分组,“VIP客户、黄金客户、普通客户”等,给予不同的优惠待遇,以此来加深与顾客的关系,增加顾客对网店的认可度和忠诚度。
(二)商品营销
由以上对商品购买的关联规则分析结果,对商品营销做出改进,可以从以下几个方面入手:
1.商品目录
商品目录包括全面的导航条和相关产品展示。对于淘宝商务平台中的天猫超市,它将进口食品和食品饮料放在导航区的上端、访问频率高的位置是合理的。收集的数据中购买前10名的多为食品类,并且进口食品和食品饮料一起购买的概率在90%以上。对于相关产品展示区,一般的食品类店铺可以将牛奶、饼干、肉类/豆干制品等顾客愿意购买的组合放在典型商品展示区。
2.商品广告
有效的广告投入可以增加网站的浏览量,从而帮助提高销售额。在淘宝网首页钻展展示区可以投放店铺活动、品牌宣传,例如强调主打的肉类/豆干制品、饼干糕点、糖果/巧克力等热卖商品正在搞活动;而类似小图、旺旺弹窗小图等站位,可以做单品、新品宣传,建议是热卖种类里面的具体商品,例如糖果/巧克力种类里面具体的热卖的费列罗巧克力在打折,可以单独为其投放广告,带来可靠回报的概率大。
3.交叉销售
商品的低位定价策略在电子商务低成本的环境下并不一定一直有效,需要配合其他的销售策略一起实施。交叉销售就是在客户购买了一种商品,向其推荐他具有潜在购买欲望的商品。关联规则发现了客户隐藏的购买需求,这些交叉销售的组合有:
表6商品销售组合表

在促销时将类似“肉类/豆干制品+饼干糕点”的组合放在一起,一起打折,或者买一赠一。即使本来客户打算只买肉类/豆干制品这一种商品,但看见饼干糕点同时在促销时,也会超出预想清单,实施购买。在这些关联规则中,也会发现一些有趣的组合,如“肉类/豆干制品、水果、纸制品/卫生纸”,分析可知,纸制品与食品同时购买,一方面是消费者享用食物时会需要纸巾清理垃圾,另一方面为了凑满88元包邮,消费者会选择使用期限较长,不会变质的商品来凑单,所以在零食类商品打折促销时,将纸制品类商品以一个小于零食类商品打折幅度的折扣进行优惠,就会满足消费者凑单的需求。这些生动化的商品组合,不仅减轻了顾客的选择顾虑,同时提升了客单量,增强了用户粘性。
五、结论
本文基于关联规则,根据客户购物关联分析的一般过程对采集的数据进行有针对性的分析,并将提取到的规则运用到电子商务的应用中。由此可知,有效的电子商务数据关联分析,能够发现交易数据库中不同商品之间的联系强度,挖掘用户潜在的购买模式,并将这些模式所对应的服务或产品展示给用户,为其提供参考,从而提高用户的购买率和满意度,增加了企业的竞争优势。
本文的研究成果存在不足之处,还可以进一步完善,具体的体现在以下几个方面:
(1)由于电商数据的封装性和自身条件的限制,本文的购物记录为问卷调查所得,缺乏普遍性和时效性。在后期进一步研究中,将搜集更多实体数据,并扩大数据量。
(2)电子商务平台可以收集到大量用户相关的数据,包括交易数据、注册数据、评分数据、咨询数据等。企业的决策目标和约束往往是多因素的,如市场占有率、利润、品牌、平台等。本次实验的算法只侧重于交易数据和以增加销售量为目标,比较片面。可以进一步的进行多维度、多粒度的整合关联分析,得到的结果会比较全面,对企业和客户的实用价值更高。
(3)目前,WEKA的关联分析功能仅能用来作为示范,不适合用来挖掘大型数据集,进一步的研究可以是通过云平台等大型专业分析工具,对数据实施更深度、更广度的挖掘操作。
参考文献
[1]王茁,顾洁.三位一体的商务智能[M].北京:电子工业出版社,2002.
[2]箭牌中国:精准预测尝“甜”头[EB/OL].http://www-935.ibm.com/services/cn/bcs/solutions/bao/case.html.
[3]Dien D Phan, Douglas R Vogel. A model of customer relationship management and business intelligence systems for catalogue and online retailers[J]. Information & Management, 2010,47:69-77.
[4]陈畅伟.基于关联规则的数据挖掘可视化系统的实现[D].武汉:武汉理工大学,2004.
[5]李国辉,张军,汤义.挖掘技术直面多媒体–信息爆炸带来新挑战[R].计算机世界报,2012(27):B1-B3.
[6]黄晓涛.电子商务导论[M].北京:清华大学出版社,2005.
[7]赵艳霞,梁昌勇.基于关联规则的推荐系统在电子商务中的应用[J].价值工程.2006,(5):6-7.
[8]钱雪忠,孔芳.关联规则挖掘中对Apriori算法的研究[J].计算机工程与应用.2008,(44):56-78.
[9]毛国君,段立娟.数据挖掘原理与算法[M].北京:清华大学出版社,2005.
[10]MichaelJ.A.Berry,GordonS.Linoff.数据挖掘[M].北京:中国财政经济出版社,2004.
[11]高宏宾,潘谷,黄义明.基于频繁项集特性的Apriori算法的改进[J].计算机工程与设计,2007,28(l0):2273-2275.
[12]刘德喜,何炎祥,邢显黎.一种新的频繁项集挖掘算法[J].计算机应用研究,2007,(2):17-19.
[13]王安,仇德成,安云峰,王继伟.一种双进的基于关系矩阵的关联规则快速挖掘算法[J].现代电子技术,2007,(3):114-116.
[14]刘景春,王永利.适合在线式增量更新的关联规则挖掘算法[J].计算机工程与应用,2004,(12):188-192.
[15]王玮,陈思红.关联规则的相关性研究[J].计算机工程,2012,26(7):33-36.
[16]王旭,刘明刚.关联规则研究[J].经济研究导刊,2010,(8):04-15.
[17]CHAUM,CHENGR,KAOB.Uncertaindatamining:anewresearchdirection[C].ProceedingsofWorkshopontheSciencesoftheArtificial.WashingtonDC:IEEEComputerSociety,2005.199-204.
[18]赵卫东.客户智能[M].北京:清华大学出版社,2013.
[19]BenJS,JosephAK,JohnR.E-commercerecommendationapplication[R].GroupLensResearchProject,2002.
附录
附录:原始数据
注:表格数据量过多,无法将所有字段和记录都列举出来,这里的原始数据仅展示部分数据。表头字段依次为:序号、提交问卷时间、所用时间、来自IP、来源、您的性别、您的年龄、您的受教育程度、您的职业、您的收入或生活费、您最近三个月在天猫超市购物的总次数、您平均每次在天猫超市购物的总花费、进口食品、食品饮料、粮油副食、美容洗护、家具家电、家庭清洁、母婴用品、生鲜水果、价格优惠、品种丰富、质量保障、配送范围广。表格记录中的数字为问卷题目的选项序号,如您的性别这列中的1和2,分别表示男和女两个选项,其他列以此类推。
下载提示:
1、如文档侵犯商业秘密、侵犯著作权、侵犯人身权等,请点击“文章版权申述”(推荐),也可以打举报电话:18735597641(电话支持时间:9:00-18:30)。
2、网站文档一经付费(服务费),不意味着购买了该文档的版权,仅供个人/单位学习、研究之用,不得用于商业用途,未经授权,严禁复制、发行、汇编、翻译或者网络传播等,侵权必究。
3、本站所有内容均由合作方或网友投稿,本站不对文档的完整性、权威性及其观点立场正确性做任何保证或承诺!文档内容仅供研究参考,付费前请自行鉴别。如您付费,意味着您自己接受本站规则且自行承担风险,本站不退款、不进行额外附加服务。
原创文章,作者:写文章小能手,如若转载,请注明出处:https://www.447766.cn/chachong/7179.html,