摘 要
数字人体模型(DHMs)领域内的研究,对于在工作中防止可能的危险,优化工作内容等是至关重要的,同时,在计算机视觉与图形学交叉领域的研究中,人体运动建模也是一个经典问题,其应用领域包括人机交互、运动同步、虚拟和增强再现的运动预测等。虽然在该领域内,有很多的技术正在不断成熟,但是发展空间还是非常大的,尤其是近些年来发展很快的运动预测问题。近年来,计算机视觉领域研究中将深度学习算法引入,越来越多的研究开始来使用循环神经网络(RNNs)来模拟人的运动,其目标是学习具有时间依赖性的表征,执行短期运动预测和长期人体运动合成等任务。本文通过查阅相关资料、论文,了解了目前最先进的算法中所使用的架构、损失函数和训练过程,研究了并分析了最新的RNN算法在运动预测方面的应用。本文采用了一种经优化的RNN算法,该算法对通常用于人体运动的标准RNN模型进行三处修改,从而得到一个简单的、可伸缩的RNN架构,该架构可以获得极其优秀的人体运动预测性能。总的来说,本文研究的内容是循环神经网络(RNN)在数字人运动预测的计算方面的应用。具体来说,本文采用的是RNN循环神经网络的优化算法,LSTM长短期记忆网络,并且是基于MXNet深度学习框架搭建的,通过使用公用人体运动捕捉数据集来训练算法模型。同时采用诺亦腾(Noitom)公司的PerceptionNeuron动作捕捉设备采集自己的人体运动数据,输入预测算法模型,得到预测数据,从而验证算法的准确性。并且通过使用Unity软件,将运动数据可视化,即使用运动数据在Unity中驱动数字人运动。
关键词: 数字人,深度学习,循环神经网络,长短期记忆网络,动作捕捉
绪 论
引言
人体仿真领域的研究已为诸多领域带来了质量、时间和成本管理方面的巨大进步,例如军事、体育设备以及汽车领域。但是,领域内迫切需要能够实时运行的人体仿真模型,特别是那些大规模数据问题,如运动预测(单个运动问题就包含了500-700个预测输出)[1]。
课题背景及意义
人体运动预测问题非常重要, 主要内容是预测一个人在未来一段时间内最有可能的动作,已知这个人在过去和当前的动作,这是一项重要且具有挑战性的任务。由于它是基于计算模拟,避免了困难、昂贵、不安全和潜在的侵入性测量的需要,以及物理实验中可能发生的相应伤害[2],导致了许多领域中研究人员的重视,如基于手部运动特征的驾驶员疲劳检测[3]、通过手指运动训练对老年人握力提高的干预研究[4]、研究通过感知手指运动创建数字语义[5],基于视觉的人手信息采集与建模[6]、心理学中的生物运动建模、工业工程中的人机工程学等,具有十分重要的意义。
研究人体运动预测,更多的是将其应用到人机交互中,改善人机交互的安全性,增强整体人机效能。此外,研究人体运动预测技术,在其他很多领域都具有十分重要的意义。在医学康复领域,患者在康复过程中经常会有不恰当的动作,对患者康复过程中的动作趋势进行预测,与正确的康复动作进行对比分析,可以及时调整康复治疗过程,制定更加准确和有效的理疗方案;在专业体育运动领域,对运动员的动作趋势进行分析预测,可以发现动作中的错误并及时纠正分析制定合适的训练计划。
在未来社会,人类同机器人的交流与协作将日益频繁,作为连接人与机器人交流渠道的人机交互技术必将会承担起至关重要的任务。社会需求和机器人技术、智能控制和机器学习的发展推动着机器人走进我们的日常生活。依靠人的感知能力和机器人执行能力的互补优势,人与机器人协同完成各种任务。物理人机交互发生在人类机器人协作任务中,如神经康复、物体运输等。随着服务机器人被期望在人类生活环境中执行任务,工业机器人被期望与人类共同协作完成任务,越来越多的研究者对于人是如何移动的表示出越来越多的关注。为了让机器人更有效地与人协作,常常需要近距离的物理交互,因此,需要开发技术和方法来支持安全、有效的物理人机交互。只有深入了解人的运动机制并预测人的运动,才能设计出安全有效的人机交互技术。
国内外研究现况
人类有一种非凡的能力,可以基于之前的事件对周围的世界做出精确的短期预测,预测其他人类的运动是这些预测的一个重要方面。神经科学研究人员通过人脑神经网络结构分析人类的运动和行为[7]。人脑是一个高度灵活的计算系统,因为一个人的能量和资源是有限的,所以在做出动作之前,大脑总是会分析未来可能的动作。它可以预测未来的结果,并在不可能达到预期结果的情况下改变运动。科学家证明,人类的运动是可以预测的。这些研究工作为人体运动预测在其他领域的应用奠定了理论基础。
机器人如何探测人类试图,从而了解人类正在做的事情,是一个非常大的挑战。如果机器人不知道人类的运动意图,它们在工作中,就又可能会成为人类的额外负荷。相反,如果机器人知道人类的运动意图,机器人可以主动主动地移动,人类引导机器人的花费精力就会减少,从而提高工作效率。[8]因此,如何估计人类的运动意图,即人体运动预测,一直是研究人员关注的问题。
由B. Corteville等人发现[9],对人的运动意图进行估计,使机器人能够跟随人完成快速的点对点任务。M.S. Erden等人在没有力传感器的情况下,通过控制力的变化来获得对人体运动意图的估计[10]。J. Huang等人定义了意图到达方向,用于在外骨骼中实时描述人的上肢运动意图[11]。
在[12]中,提出了一种全向行走机器人的行走意图估计方法。人类运动意图在文献中有不同的定义。在[13]中,人体运动意图被定义为人体的当前位置,通过多模态界面提供反馈。在[14]中,人体运动意图被定义为目标位置或时变期望轨迹,由在线神经网络(NNs)基于可获得的感知信息进行估计。
如何使机器人根据环境的阻抗[15]或人的阻抗[16]来调整其所需的阻抗也是中的一个关键问题。在[17]中,作者提出了一种阻抗学习方法,使机器人能够与未知环境进行交互,以避免较大的交互力。
一种名为GAN-Poser的基于generator–discriminator框架的方法被用于在输入三维人体骨架序列后预测人体运动。具体地说,与传统的Euclidean loss相比,frame-wise geodesic loss被用于几何意义上更精确的距离测量。在···这篇论文中,使用了一个双向GAN框架和一个递归预测策略来避免模式崩溃和进一步规范化训练。为了能够在给定起始序列的条件下生成多个可能的人体姿态序列,还引入了一个随机外部因子H。对鉴别器进行训练,使其回归到外部因子H,并与内部因子(编码的起始位姿序列)一起生成特定的位姿序列。尽管在概率框架中,改进的鉴别器结构允许预测位姿序列的中间部分,作为预测序列的后半部分的条件。这种基于对抗性学习的模型考虑了随机性,双向建立的模型为评价给定测试序列的预测质量提供了一个新的方向。由此得到的新方法,GAN-Poser,在标准NTU-RGB-D和Human3.6 M数据集上进行评估时,取得了非常优秀的性能。
论文主要研究内容与安排
主要研究内容
人工神经网络(Artificial Neural Network)已经成功应用于各种实际问题。虽然各种不同类型的人工神经网络为了提高性能已经进行了广泛的改进,但是每个人工神经网络设计仍然会有其自身的局限性。现有的数字人体模型已经足够成熟,可以为不同条件下的不同任务和方案提供精确与有用的结果。但是,目前非常需要使这些模型实时运行,尤其是那些有较大运算量的大规模问题,如运动预测。然而,即使是非常小的条件的改变,运动仿真就需要运行相对较长的时间(几分钟到几十分钟)。因此,由于运算时间以及收集训练数据所耗费的成本,训练案例的数量十分有限。另外,运动问题就输出数量而言相对较大,仅仅是预测单个问题就有数百个输出(在500-700个输出之间)。因此,在运动问题中使用了诸如人工神经网络之类的工具。
本文组织安排
本文采取了诺亦腾(Noitom)公司研发Perception Neuron动作捕捉设备来采集人体运动数据。然后基于MXNet深度学习框架下搭建了RNN(Recurrent Neural Networks)循环神经网络的优化算法,LSTM(Long Short Term Memory)长短期记忆网络,并通过公用人体动作捕捉数据集来训练模型,最终达到了较为理想的结果。然后用自己通过Perception Neuron动作捕捉设备采集的运动数据测试验证预测的准确性。最终,采用Unity软件,使用源运动数据与预测生成运动数据分别驱动两个数字人运动,即将结果可视化。
人体运动数据捕捉与处理
在进行人体运动预测模型搭建之前,一项重要的工作就是相关数据的采集与处理。一组正确的优质的数据是完成预测网络有效训练的前提和基础。本章分别对比了不同的动捕技术的优缺点,确定了捕捉人体运动的设备,论述了采集数据的原理与流程。
相关理论基础与工具平台
随着世界科学技术的发展,来自世界各地的研究人员的运动越来越重视动作捕捉技术。世界各地的实验室在其广泛的应用领域投入了大量资源,加快这个行业的发展。之后经过几十年的不断发展,在灵敏度和精密度方面都取得了很大的进步实现。
动作捕捉技术的种类
目前有很多种不同的动作捕获系统,一般而言,根据技术原则,可以区分五大类:机械、声学、电磁、惯性传感器和根据不同类型的目标特性可以分为两大类:标记点和无标记点式的光学式。近年来,在市场上出现了所谓的热运动捕获系统,这基本上是无标记光学运动捕获的一部分。光学成像传感器主要在近红外或红外波段中工作。
机械式
一般情况下,该类运动捕捉系统系统由几个关节和刚性连接杆组成,其中角度传感器存在于可以旋转的关节中,用于测量关节角度的变化,总的来说,是基于机械装置来跟踪运动和测量运动的路径的。如果设备移动,目标对象必须每个身体部位都有一系列的刚性支撑固定。如果目标移动,身上的刚性支架一起移动,目标各部位的角度变化会由支架上的传感器测得,刚性杆的位置和运动路径可以由角度变化和杆的长度得出。
该类产品在成本、精度和采样频率方面具有很高的优势。但是,最大的缺点是缺乏操作方便和灵活性。连杆结构和检测电缆对艺术家的行动施加了很大的限制和限制,特别是在连贯性运动被阻断的情况下,这使得真正的动态运动不做变得难以完成。代表产品有 Gypsy 6 Motion Capture System。


图2-1Gypsy 6 Motion Capture System
声学式
一个传统的声学式动捕设备是由多个部分组成的。第一个部分为发射器,就是所谓的超声波发射器。第二个部分为接收装置,它是由很多个超声探头阵列组成。装置之间的距离,可以通过测量从发送设备到传感器的声波的时间或相位差确定。成本低是它的主要优点,但也有很多缺点,如缺乏精确性,实时性差,噪声、多次反射等因素能够严重影响设备。
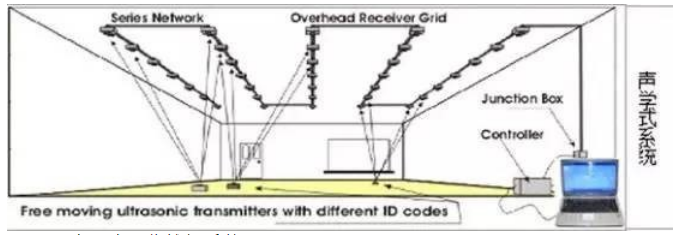
图2-2声学式动作捕捉系统
电磁式
电磁动作捕捉系统也是由多个部分组成。第一个部分为发射源,它的主要作用是在给定的空间中产生具有规律性的电磁场。第二个部分为接收传感器,它被佩戴在实验人员身上的主要躯干部位,随着实验人员在电磁场中运动,将收到的数据通过有线或蓝牙等其他办法传给数据处理装置。第三个部分就是处理装置,它的作用是根据传感器装置传送过来的数据,通过一系列的运算,最终得出所有传感器的位置与方向。
使用起来非常简单、鲁棒性和能够及时反馈结果等诸多特性,是这类产品的最大优点。但是也有很多缺点,其中最大的缺点就是对金属类非常敏感。金属在磁场内,会导致电磁场发生畸变,从而严重降低数据的准确性。同时,也会导致设备的采样率降低,从而导致捕捉比较快速的动作十分困难。此外,还有一个缺点,就是设备是有一些线缆的,他们的存在制约了实验者做各种姿势的灵活性,很多动作也无法进行。
图2-3电磁式动作捕捉系统
惯性式
惯性传感器运动捕捉设备有以下几个部分组成。第一,姿态传感器,他会被佩戴在实验者身上的主要部位,如四肢、背部等。通过传感器采集数据,通过有线或者WIFI,BlueTooth等其他方法,将数据发给数据处理装置,进行运动解算。为了获得关节点的位置的信息,将骨长度信息与骨架结构信息相结合,加上人体各部分得姿势数据就可以计算出。剩下两个部分是信号接收装置和信息处理系统。
此种动捕设备主要的优势可移植性强,操作简单,几乎可以在任何空间进行实验,适合户外使用,但由于技术的限制原则,也有明显的缺点。一方面,传感器本身不能绝对定位,主要原因是不同程度的积分漂移现象。这个现象的产生是因为此处的空间定位数据,是由实验人员的某些姿势数据通过计算而出的。因为以上原因,就会导致定位数据的误差。另一方面,这种设备的原理本身是存在缺陷的。主要是,设备难以处理身体不接触地面的动作定位问题,就是因为地面约束假设原理是有问题的。除了这些,传感器的重量和电缆的连接也会对运动性能形成一定的约束,设备成本会随着被捕获对象数量的增加呈指数增长。一些传感器也会受到周围铁磁体精度的影响。代表产品有NoitomPerception Neuron。
光学式
在光学系统中,小的反射标记被附加到演员身上,一组特殊的相机简单地放置在空间周围,以很短的间隔拍摄场景。每个视图都被提供给一些特殊的软件,这些软件使用已知的观察空间的尺寸来计算每个标记的三维坐标。标记的数量和大小,以及它们的位置,可以有很大的不同,这取决于所需的运动数据的类型和使用它的目的。光学系统对演员来说几乎没有这样的抑制作用,通常可以在更大的空间内使用,而且受到环境干扰的危险要小得多。然而,当原始数据输入时,标记坐标不会自动与任何特定的标记相关联。每个路径都必须通过手动或软件进行识别,以生成一个连续的路径。此外,当参与者移动时,一些标记可能会被阻塞,因此数据中经常存在很大的令人不安的“空白”。这些不太“干净”的数据不太容易立即用于实时动画,但通常必须首先处理。此外,由于原始数据(一旦识别)只给出标记的位置,必须使用软件来计算它所连接的对象的方向。Motion Analysis Corporation和Vicon是两家著名的光学运动捕捉系统制造商。
无标记式光学式动作系统采集传感器通常都是光学相机,主要区别在于目标传感器类型,主要分为无标记点式光学动作捕捉系统和标记点式光学动作捕捉系统两种。第一种不用在实验者身上佩戴标记装置,是根据分析平面图或立体图,从中可以得出所需要的骨骼关节等信息。另一种需要在实验者身上佩戴标记装置,配合摄像头采集所需要的数据。
无标式的设备存在采集到的数据精确度很低的缺点。同时此类设备的原理本身具有的缺点让动作自由度运算出现问题。可能会丢失骨骼的自旋信息等,从而造成运动变形。
该类动捕设备以Optitrack为代表,他们有非常可靠的技术支持,并且采集到的数据精确度很高。同时,因为装置对身体影响很小,因此实验人员很方便做各种动作。还有一点,标记装置很便宜,因此能够大量使用,能够应用的领域十分宽阔。且因其使用不可见反射光进行识别,即便是在户外环境下也可以很好的使用,适用场景并不局限在室内稳定光照环境。

图2-5OptiTrack标记式光学动作捕捉系统
人体运动数据的采集
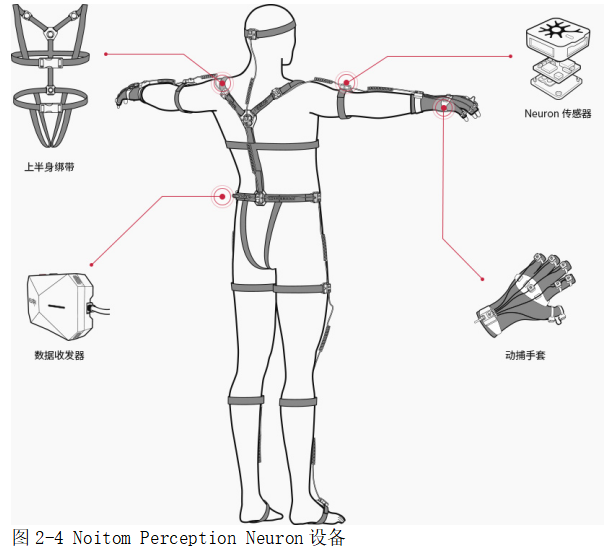
人体骨骼是生命活动的基础,为人体提供支撑。然而,全身有200多块骨头,有着极其复杂的运动结构。为了简化对人体运动的分析,目前大多数的运动捕捉设备都集中在具有关键信息的运动部分,而对于非关键部分,皮肤则通过动画技术进行补充。其中之一就是诺亦腾公司的PERCEPTION NEURON运动捕捉系统。PERCEPTIONNEURON运动捕捉设备其实就是多个穿戴在身体上的传感器组成的,优势非常的多,例如容易携带、使用简单、耗能特别低等。系统由18个由一系列绑带定在穿戴者身体主要运动关节的传感器组成,设备穿戴效果见图2-4。传感器节点是系统的核心,其构成比较负责,包括了以下几个部分。加速度计用来测量各种加速度。陀螺仪负责感知方向、平衡以及位置。磁强计是用来测量磁场强度的。以上各部分,与惯性测量装置一起配合,共同测量所需要的数据。感知神经元运动捕捉系统通过导线将所有传感器节点连接在一起,最后将运动捕捉数据采集到集线器中,通过集线器实现有线或无线输出。
通过运动捕捉系统,我们能够得到BVH文件。其包含了人体运动相关的数据,如关节旋转、平移。BVH文件是由两部分组成的。前一部分是文件的数据结构形式,包括主要节点的名称、数据维度和节点的初始偏移量。在本文使用的运动捕捉系统中,可以根据传感器绑定的位置调整关键节点的初始偏移量,以减少个体差异带来的影响,从而使采集到的数据更加有效。其中,实验人员的每个动作,都会在三维坐标系中产生与上一节点的一定的旋转角度和偏移量。这个文件看作将人体骨骼关节拓展至人体各个部位的跟关节,同时,通过一次次遍历可以得到整个骨骼信息,从而得到了所需要的运动数据。需要说明一点,方向和偏移量是通过矩阵运算得到的。第二部分就是运动数据,是以欧拉角的格式进行存储的,记录了每一帧的姿势数据。
BVH文件
运动捕捉数据是采用二维的方式来表示发生在三维世界的运动,Biovision Hierarchy(简称BVH)是一种常用的存储此类运动数据的文件格式,用以表示人体运动。这种格式非常广泛地得到了使用,在几乎所有相关软件中都能够使用这种格式。
BVH文件主要由两部分组成。第一块是数字人的骨骼信息,阐释了人骨架的树状结构关系和零时刻的姿势。另一块则是数据块,即为所采集的运动数据,以欧拉角格式存储。骨架信息根据层次关系定义位置和旋转组件,如根髋腿,从而形成一个完整的骨架,如图2-6所示。
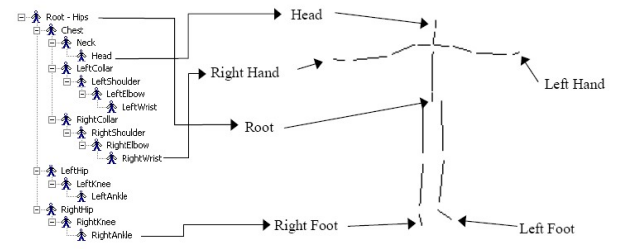
图2-6BVH文件中骨架结构
诺亦腾设备
本课题采用的是基于惯性传感器的诺亦腾Perception Neuron动捕设备。Perception Neuron动捕设备是世界上功能最广泛、适应性最强、价格最合理的运动捕捉系统之一,它为各种应用提供了用户友好的技术。Perception Neuron动捕设备在视觉特效、VR\AR、Motion Analysis、Medical Analysis、实时舞台表演等领域提供了灵活的动作捕捉解决方案。
Perception Neuron动捕设备是第一个提供小的、自适应的、通用的和可负担得起的运动捕捉技术的工具。该设备其实就是由若干个IMU(惯性测量单元)组成的,IMU也有很复杂的结构,其组成如下。神经元,其实就是传感器,用来测量、采集处理数据。一个三轴陀螺仪,用于测量方向。一个三轴加速度计,用于测量加速度。三轴磁强计,用于测量磁场强度。该系统的优势在于感知神经元专有的嵌入式数据融合,人体动力学和物理引擎算法,以最小的延迟提供平滑和真实的运动。
动作捕捉设备介绍
Perception Neuron是一种基于惯性传感器的运动捕捉系统,这意味着每个传感器,即神经元,可以通过陀螺仪、磁力仪和加速计测量自身的方向和加速度。在每个神经元上也做它自己的漂移校正,然后将测量数据发送到集线器,集线器从每个连接的神经元收集所有的数据,然后集线器通过USB或Wi-Fi连接将数据发送到一台运行Axis Neuron软件的计算机,该计算机已经与集线器建立了连接。Axis Neuron软件通过一些复杂的算法、数据优化和漂移校正,从神经元接收到的传感器数据中,重建出一个有59块骨头的人体骨架。
Perception Neuron设备主要分为三个部分,Neuron Sensor即传感器,一种由陀螺仪、加速计和磁强计组成的惯性测量装置;Hub,从神经元传感器收集运动数据,然后通过USB或无线连接将数据发送到计算机;绑带,绑带将神经元传感器固定在身体上,背面的标签指定了背带的位置。
Axis Neron软件
Perception Neuron与AXIS Neuron软件一起配套使用的,AXIS Neuron软件被设计来管理和校准你的系统,以及执行基本的动作捕捉。AXIS Neuron最重要的特性之一是能够传输BVH数据流,以便在最流行的3D软件程序中使用。
对于专业需求,AXIS NEURON提供了一组最先进的工具来扩展您的感知神经元MOCAP系统的功能,并将其完全集成到您的工作流中,无论您是在VFX、游戏开发还是任何3D应用程序中工作。
图2-7AXIS Neuron软件界面
动作捕捉
按规定穿戴好Perception Neuron设备后,启动AXIS Neuron软件,就可以开始记录运动数据了。

图2-8Perception Neuron设备穿戴
首先用USB数据线(黑色)将Hub连接到计算机。USB线的一端连接到Hub的数据端口,另一端连接到计算机上的一个USB端口。当Hub被成功识别时,Hub的ID将显示在欢迎窗口的左侧面板上。单击“连接”按钮将集线器与计算机连接。在成功地建立与Hub的连接之后,单击zero按钮将模型居中到原点。请在这个步骤中保持稳定。模型尺寸可以在身体尺寸列表里选择,以确保更准确的使用。点击Calibrate按钮来进行姿势校准。校准有助于定位传感器,帮助准确捕捉运动数据。检查姿势(需要校准,然后点击Next按钮开始。完成位姿校准后即可开始记录。点击录制按钮。在接下来弹窗中更改文件存储路径与名称。(运动数据将会在录制按钮闪烁时被记录下来)。您可以再次单击Record按钮来停止录制。记录的文件将自动出现在工作目录窗口中。要播放录制,请选择工作目录窗口中生成的录制文件并单击播放按钮。通过点击File->Export->Export Settings设置来导出您的数据,然后点击Export按钮将您的数据导出到默认值<bvh>格式。需要注意的是,Perception Neuron设备系统应该在几乎没有磁场的环境中使用,否则传感器将受到不利影响,并可能使运动捕捉数据非常不精确。使用感知神经元时,避免使用电动装置、扬声器、变压器和铁制家具。为了提高精度:精确的骨骼测量和尺寸可以提高运动数据的精度;要这样做,请测量参与者的指定身体部分,并在记录之前将此数据输入到身体大小管理器中。
基于神经网络的人体运动预测算法
本文在Linux系统中完成了环境的配置,采用了MXNet深度学习框架来进行本次的研究。搭建的是LSTM网络。
RNN循环神经网络
人类并不总是在大脑一片空白的时候开始思考。当你读到此处的时,你已经根据你之前看到的的知识推断出了现在部分真正含义。我们不会把所有的东西都扔掉,然后头脑一片空白地思考。我们的思想是永恒的。但是对于一般的神经网络,是无法实现这个过程的。比如,您如果正在对某个电影的发发展方向进行预判,就需要根据已经发生过的情节进行推测,这是一个比较复杂的过程。像这种根据已经发生的若干事件,来预测未来的进展方向,对于一般的神经网络来说,就无法进行预测。
但是RNN可以对这种情况进行预测,它有一个非常显著的优点,就是可以实现信息的持久化,可以处理序列数据。设输入层为I,隐含层为H,输出层为O。在一般ANN中,信息流的流动是从I到H,再到O。其中层与层之间的节点是不连通的,但是层之间全连接。但是这种普通的神经网络在很多问题上是无用的。比如,你正在阅读一篇文章,想要预测下一句话是什么,这就是典型的这类的预测问题。这种预测问题的实现必须用到之前的文章,即已经读过的句子,整篇文章的各个句子之间是相互有关联的。RNN就是用来处理这种问题的,即需要进行预测的问题和已经进行过的预测是有联系的。具体表现是,网络会记得以前的信息并把它应用到当前输出计算,也就是说,不再隐藏层之间的节点连接能够连接,和隐藏层的输入不仅包括输入层的输出也在最后一刻隐层的输出。对于RNN来说,如果仅仅在原理层面分析,它是能够解决随便长度的序列信息的。图3-1为一个典型的RNN。
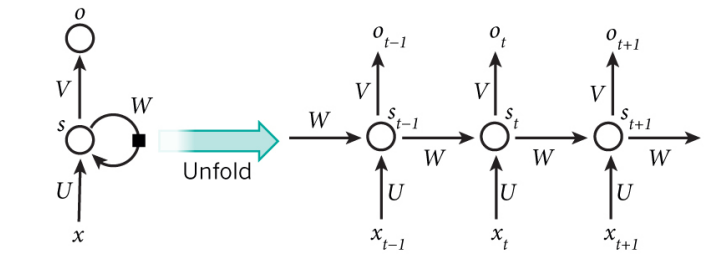
图3-1一种典型的RNNs
在图3-1中,有一个从I到H的一个方向的数据流动。另外,还有一个从H到O的一个方向的数据流动。一些时候,RNNs会发生一种被称作“反向投影的”过程,就是它将数据从O返到H。同时,H的输入还包括前一个H的信息,并且在这里面的节点能够自己与自己或自己和他人接通。
经过实验验证,RNN在自然语言处理领域内应用效果十分优越。如对句子意思的理解、句子语法的检查、词性的判断等。RNN有一种经过优化的算法,名字叫做LSTM。它一经推出,就迅速得到了业内人士的青睐,得到了大规模传播和使用。主要是因为它的优化十分有效,使它能够处理之前所不能够的长期和短期依赖关系。与一般的RNNs相比,该模型只对隐含层进行了操作。稍后将详细介绍LSTMs。
对于RNNs来说,在训练数据的长度较大或者时刻较小的条件下,关于时刻隐藏层变量,损失函数的梯度比较容易出现消失或爆炸。这种问题也被称作长期依赖问题。梯度爆炸的问题一般可以通过梯度裁剪来解决,领域内的研究人员进行了很多研究,由此诞生了LSTM。
LSTM长短期记忆网络与GRU
LSTM经过RNN优化而得,性能方面有了很多提升。其中比较显著的一点就是,它可以学习长期依赖信息。非常广泛的领域中,LSTM已经取得了相当大的成功并得到了广泛的应用。LSTM的设计是为了避免长期依赖问题。
RNN结构之所以出现梯度爆炸或者梯度消失,最本质的原因是因为梯度在传递过程中存在极大数量的连乘,为此有人提出了LSTM模型,它可以对有价值的信息进行记忆,放弃冗余记忆,从而减小学习难度。与RNN相比,LSTM的神经元还是基于输入X和上一级的隐藏层输出h来计算,只不过内部结构变了,也就是神经元的运算公式变了,而外部结构并没有任何变化。
和RNN进行比较的话,LSTM引入了门的概念,在Neuron中加入了很多的门。输入门用来控制输入。遗忘门用来控制是否遗忘信息,从而达到记住要点的目的,即核心功能。输出门用来控制输出。内部记忆单元是用来存储数据信息的。简单来说,门就可以理解为现实的门的意思,因为它输出的是0-1的实数向量,和想要控制的那个量相乘,就改变了输出值,从而控制了数据的流动。因为门的输出是0到1之间的实数向量,那么,当门输出为0时,任何向量与之相乘都会得到0向量,这就相当于啥都不能通过;输出为1时,任何向量与之相乘都不会有任何改变,这就是全开门。
主要来说,LSTM使用了两个门来实现了目标效果。一个是遗忘门,它控制着遗忘掉多少数据,也就是有多少状态数据能够得到留存。另一个是输入门,它控制着现在的单元状态中,能够输入多少。
基于MXNet深度学习框架的人体运动预测算法
Apache MXNet深度学习框架
Apache MXNe是一个深度学习框架,它将多种编程命令相互使用,构建一个高效率、高生产力的环境。它的核心是一个调度器,能够自动结合符号编程与命令式编程并运行,在动态调配过程中执行速度更快,使用效率更高。MXNet是学习项目同时也是一个算法语言库。在深度神经网络中,它使编译算法趋于简化,还能自动工作,让命令的表达和使用更快捷。MXNet是紧凑和内存高效的,可以在各种异构系统上运行,从移动设备到分布式GPU集群[18]。
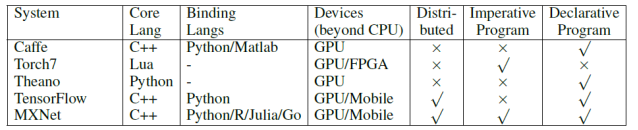
机器学习(ML)算法的规模和复杂性越来越大。几乎所有最近的ImageNet挑战[19]的获胜者都使用非常深层的神经网络,需要数十亿的浮点运算来处理一个样本。结构和计算复杂性的增加对ML系统的设计和实现提出了有趣的挑战。大多数ML系统将领域特定的语言(DSL)嵌入到宿主语言(如Python、Lua、C)中。可能的编程范例包括命令式(用户确切地指定“如何”执行计算)和声明式(用户规范集中于“做什么”)。命令式编程的例子包括numpy和Matlab,这里有像Caffe这样的包,CXXNet程序的层定义,它抽象并隐藏了实际实现的内部工作。两者之间的分界线有时很模糊。像Theano和最近的Tensorflow这样的框架也可以被看作是两者的混合体,它们声明了一个计算图,但是图中的计算是命令式指定的。
比较其他开源ML系统,MXNet提供了一种超集编程接口接入Torch7 [20], Theano[21],Chainer和Caffe[22],并支持更多的系统,如GPU clusters。除了支持声明式程序的优化TensorFlow,另外MXNet嵌入命令张量操作提供更大的灵活性。MXNet是轻量级的,例如,一个单个的预测代码仅有50K行C++代码,并没有其他依赖关系,而且,MXNet并且有更多的语言支持,更详细的比较如表2所示。
LSTM模型的搭建
在本次研究中,所搭建的LSTM神经网络的结构主要包括了以下内容:LSTM隐层的层数为1,隐含层中隐含节点总共为1000个,其他参数为:
num_layer=1
cell=’lstm’
hidden_unit=1000
time_step=90
seed_timestep=30#0.9secondmotionseed/2secondmotionprediction
batch_Frame=1
frame_time=24
save_period=100000
parameter_shared=True
BVH格式的运动数据文件的读取与创建写入,实现的代码见附录。
神经网络执行的参数为:
epoch=100000,batch_size=68,
save_period=save_period,
cost_limit=0.01,
optimizer=’adam’,
learning_rate=0.0001,
use_gpu=True,
num_layer=num_layer,cell=cell,
hidden_unit=hidden_unit,time_step=time_step,
seed_timestep=seed_timestep,
batch_Frame=batch_Frame,frame_time=frame_time,
graphviz=True,
parameter_shared=parameter_shared
其中各个参数的具体含义为:
epoch的意思是:1个epoch表示过了1遍训练集中的所有样本;
batch-size为神经网络模型1次迭代所使用的样本量;
save_period表示每隔n迭代计算神经网络模型将会保存中间结果;
cost_limit为设置的一个可视为训练完成的目标参数;
Adam(Adaptive Moment Estimation,适应性距估计)是指神经网络模型在训练过程中的优化器类型,通过数据迭代不断更新神经网络的信息,可以快速收敛数据达到更快处理数据的效果。这是一种优化算法,和其他算法相比,这是目的最实用的算法之一;
learning_rate是一个超参数(hyperparameter),它控制每次更新模型权值时,根据估计的误差改变模型的程度,选择学习率是有挑战性的,因为值太小可能会导致一个很长的训练过程,而值太大可能会导致学习一组次优的权重值太快,或者是一个不稳定的训练过程;
use_gpu表示GPU是不是启动加速训练过程;
num_layer LSTM隐层的层数;
cell=cell;hidden_unit为隐含层中隐含节;
time_step就是统计每隔多少时间确认上一次输入数据与下一次输出数据所需时间的间隔;
Graphviz在这里专门用于绘制标图,在进行可视化输出。它是一款可视化软件,将抽象的数据信息转换为图像或者图表,用于统计数据库、机器学习或者其他方面的视觉表达;
parameter_shared是决定编码器解码器是否共享参数的参数。
训练集与测试集
运动捕捉数据今天以许多不同的形式被使用。最明显的是娱乐领域。大多数动画电影和几乎所有的视频游戏都使用并改编了动作捕捉信息,为人类或类人角色提供似是而非的动作。因为有太多的现实细节是很难与手动程序化定义的运动路径相协调的,所以这个运动对观察者来说更真实。大多数动画广告也使用动作捕捉数据来提供真实的动作。运动、舞蹈、物理治疗、生物力学和矫形外科等领域的研究关注的是运动的细节,这些细节是通过动作捕捉技术最巧妙地掌握的。
但是用于神经网络模型训练与测试的需要大量数据,而且需要非常专业的动作捕捉设备,捕捉到非常精准的数据,才能使算法最终效果得到保证。但是现在,即使没有14个摄像头的Vicon8系统的预算,向学生介绍运动捕捉的优势仍然触手可及。首先,大型的大学院系,例如生物医疗、计算机绘图、艺术创作等,可能会有一个动作捕捉系统,并且可能会愿意让学生参观并捕捉一些动作。亲自参观实验室并为特定项目计划和创建自己的数据是最有教育意义的,就像我们的图形课在俄亥俄州立大学艺术与设计高级计算中心(ACCAD)的运动捕捉实验室所做的那样。[23] 当附近没有可用的设备时,也可以购买数据集。许多公司,如Biovision(专门从事体育数据)可以提供通用或“捕捉到的命令”数据,但也有运动捕捉数据集,在网上出售和免费下载。有mocap实验室的大学可能有一个通用数据仓库,任何人都可以使用。最后,可以在自己的神经网络模型中使用以上的数据。
本次研究中使用的是Advanced Computing Center for the Arts and Design的动作捕捉数据。训练数据为4名女性的训练运动数据,每人68个运动数据,测试数据为1名女性的测试运动数据,每人68个运动数据。
算法有效性的验证
定义误差值cost,其值为: cal=mod.predict(eval_data=train_iter,merge_batches=True,reset=True,always_output_list=False).asnumpy()/Normalization_factor
cost=cal-train_label_motion
cost=(cost**2)/2
cost=np.mean(cost)
结果为:
图3-9预测误差
使用graphviz绘制图表:
style.use(‘seaborn’)
plt.figure(figsize=(9,4))
bbox=dict(boxstyle=’round’,fc=’w’,ec=’b’,lw=2)
#plt.plot(TimeStep,TimeStepError_Array,”r.”,lw=3,label=”Error”)
plt.bar(TimeStep,TimeStepError_Array,width=0.7,label=’error’,color=’r’)
plt.annotate(“ErrorPrevention”,fontsize=14,xy=(60,1000),xytext=(0,1000),textcoords=’data’,arrowprops={‘color’:’blue’,’alpha’:0.3,’arrowstyle’:”simple”},bbox=bbox)
plt.grid()
plt.xlabel(“Time”,fontsize=14)
plt.ylabel(“JointAngleError”,fontsize=14)
plt.ylim(0,4400)
plt.legend(fontsize=15,loc=’upperleft’)
plt.title(“PredictionErrorGraph”,fontdict={‘fontsize’:15,’fontweight’:5})
print(“costgraphsaved”)
plt.savefig(“CostGraph.png”)
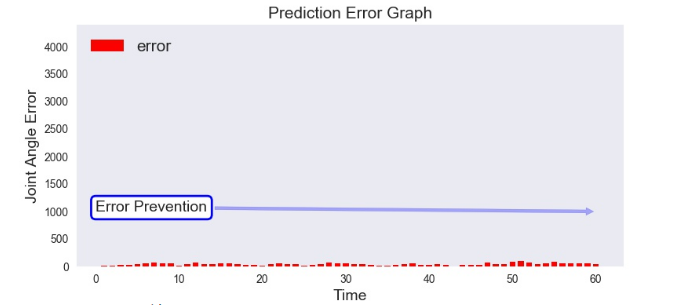
图3-10预测误差
Unity
Unity介绍
Unity3D是是一款游戏引擎,它有十分强大的功能,能与大半部分的3d软件资源交换格式,专业性和综合性十分完善。在功能方面,在软件内部除了基础的音频、图像等功能,还有着Shuriken系统专门用于渲染,可以创作出美丽绝伦的粒子效果。在外部有着多平台使用,无论是Windows还是MacOS系统,具有多元化的平台应用。
打开Unity软件,就能看到如图4-1的主界面,主要有Menubar、Toolsbar、Inspector、Scene、Game、Hierarchy、Project等区域,我们大多数操作都是在Scene场景内进行的。
图4-1Unity3D操作界面
Unity软件具有跨平台、超强通用性、自身资源商店、成本低廉、强大的物理引擎、LightMap烘焙工具、Mecanim动画系统、地形编辑器、ShaderLab(着色器),以及支持脚本语言等特点,具体如下:
跨平台关于Unity引擎的跨平台特性,前面已作了讨论。游戏可以在不同的平台上开发,开发的应用可以在多个平台上发布,从而大大提高了开发商的发展效率。
超强通用性大多数的三维动画制作软件均可以在Unity软件上使用。
Unity资源商店资源商店是Unity软件内部的交易平台,使用该软件用户可以在该平台上下载和购买相关的开发软件,包括模型、代码等等,相应的用户也自己上传出售自己的作品。
成本低廉Unity软件使用并不一定付费,开发者和学习者皆可以在官网上找到免费下载使用的版本。虽然是免费的版本,但是其中包含的基础应用可以进行绝大多数的操作。同时在同行业比较,Unity软件的授权费用也是十分低的。
强大的物理引擎Unity软件具有强大的物理模型系统,它可以模拟现实中各种物理效果,例如碰撞、压缩、重力等等,营造一个生动真实的模型世界。
LightMap烘焙工具LightMap烘焙工具的主要作用是渲染环境,通过Beast烘焙系统,可以让使用者模拟现实中真实的光影效果,包括自然光、色彩反弹阴影等,还可以制造动态的的光照贴图,包括高动态范围光照和移动光源等。。
Mecanim动画系统Mecanim动画系统特点众多,主要是它可以定向操作也能融合其他,简洁方便又功能实用,常常经过技术配合视觉设计,在编辑器中直接更改和设置参数。
ShaderLab(着色器)ShaderLab是的使用接近Cg的一种编程语言,它内置在Unity软件中,可以对其调用编写。使用者可以独立使用编写,创作的Shader往往可以有这出乎意料的画面效果。
MotionBuilder软件
因为Unity软件无法是不支持直接读取bvh格式的文件,而我们算法中用于训练、测试以及生成的都是bvh格式的文件,所以在这里采用Autodesk MotionBuilder软件将bvh格式文件转换为fbx格式文件。
MotionBuilder的软件是用于电影,视频游戏和广播制作的业界领先的实时三维动画解决方案。AutodeskMotionBuilder专注于交互式实时工作流程,使创新的3D艺术家和技术艺术家能够承担最苛刻的动画密集型项目。MotionBuilder是专为三维数据采集,处理和可视化而设计的专业级解决方案,它不仅是一个动画效率工具,也是一个驱动创造性迭代过程的工具。

图4-2MotionBuilder软件界面
打开软件后,点击File/Motion File Import导入bvh运动数据文件

图4-3导入文件
然后点击File/MotionFileExport导出为fbx格式运动数据文件
图4-4导出文件
数字人建模
数字人体建模(Digital human modeling, DHM)是一种在虚拟环境中模拟人类与产品或工作场所的交互的技术,它越来越受欢迎。这个虚拟评估过程在开发以用户为中心的产品时非常有用,它在早期设计阶段结合了人为因素的原则,从而减少了设计时间并提高了质量。DHM的应用在制造业、农业、医疗保健、交通和航空等行业的设计过程中得到了广泛的关注。然而,使用DHM设计符合人体工程学的产品和工作环境,为特别有能力和老年人是相当有限的。否则,这是更重要的,因为他们在现实生活中参与有关任何产品、工作场所或公共设施的人体工程学评价的实验,可能会给他们带来不适。此外,改进的产品或工作场所减少了他们对他人的依赖,使他们能够积极参与工作、交流和社会生活。因此,本文试图探索基于DHM的虚拟工效学方法在改善特殊残疾/老年人产品和工作场所设计方面的应用现状文献综述。本研究亦提出未来的研究及发展方向,透过积极及包容的设计策略,改善长者及有特殊能力人士的生活质素。
三维几何建模利用计算机处理三维空间的数据,同时利用多媒体领域的理论构建虚拟模型。三维几何建模是其重要的分支[24],处理的对象是三维几何建模,达到的目标是构建有实际意义的模型。
构建数字人模型能够更直观的展现运动预测的的情况,能够使人眼观察到流畅完整的人体运动,是本文评估预测模型的辅助验证方法。骨骼在人体结构中起到了支撑和主导作用,因此构建人体骨骼模型作为人体运动模型可以很好的反映出人体做动作时个特征变化。
目前主要的建模方法有:
(1)3D激光扫描建模:建模的基本操作是使用激光反射表面的反射扫描光束,来感知被测物体的形状和尺寸,进而建立模型。该方法成本高,操作难度大,但是精度却可以保证。通常适用于高端制造业,比如说零件的精加工。所以这个方法不适应与本文的骨骼建模。
(2)二维图像建模与绘制:通过数据的预先收集,再把一系列的图像综合运用到场景,通过拼接组合实现新图像的生成,这是二维图像建模与绘制的主要手段。但是这种方法局限性很大,与环境的交互能力差,只能用于场景的浏览,不适合结构复杂观察面较多的虚拟手建模[17]。
(3)仿真软件三维建模:仿真建模软件应用领域十分广泛,针对不同领域,目前有3ds.Max.、AutoCAD.、Maya等。软件建模可以控制模型精度,效率较高,成本却很低;最重要的是,在具体的人手模型中,模型中关节的表示和角度参数的控制是可以一次到位的,这是选择它进行建模的主要原因,这为虚拟手的运动与交互提供支持[25]。
根据实验目的以及对目前流行建模方法的分析,采用仿真软件三维建模方式来构建数字人模型。根据人体测量学及人体骨骼结构,基于Maya软件构建的数字人模型如图4-5所示。

图4-5数字人模型
Fbx文件在Unity中驱动数字人运动
由Autodesk公司出品Autodesk FBX是一款非常实用的软件,不仅可以跨平台免费使用,还能再上门进行三维创作和创作作品的格式更改,所以使用FBX的用户能进行大部分的三维文件格式交换。FBX的数据交换功能强大,现有的所有数据元素包括三维、二维、音频及视频都能使用,这也为其提供了新的技术,即专用的数据迁移定位。当然,可以针对不同软件的特性,单独或同时强化它们的某一部分,可以做到Autodesk公司旗下3ds Max、Softimage、Mudbox和MotionBuilder这些软件的相互操作、数据共享,可以多个应用的工作分别该工作。使用新兴的矢量置换贴图技术,结合Ptex文件的应用,可以让FBX发挥出更大在作用,在短时间内发挥出更高的效果。
打开Unity软件,创建工程。然后导入创建好的数字人模型(FBX格式)以及运动动画(FBX格式),并将数字人以及运动动画Rig/AnimationType设置为Humanoid即拟人式,这样,Unity才能识别数字人以及运动动画中包含的人体骨骼信息,从而才能够正确驱动数字人运动。
Unity中AnimationType分为三种种类型,Legacy作用很小,只能在Mecanim动画缺失的去情况下才能适用。基本上,不需要使用它,除非有一个不想更新的旧项目;Humanoid用于人体类型动画,这可以指人类,机器人,直立的动物,或者任何你能想到的看起来像人类的东西,在任何情况下,对于这种类型的动画,最好是在一个单独的建模程序中创建动画,然后导入到Unity中,如果正确地配置了模型,那么导入应该非常顺利;Generic非常简单,它用于任何类型的动画,而不是人形。你可以用它来开门、开枪等等,对于这种类型的动画,使用Unity提供的动画编辑器制作动画可能更容易。
需要注意的是,设置为Humanoid之后需要对数字人的骨骼信息与Unity进行绑定匹配,这样才能使Unity正确识别数字人。在绑定的界面中,用颜色区分映射关系。其中绿色白色均是代表Unity内置骨骼,但是白色是错误的映射。作为要映射的部分,用实线和虚线加以区分,实线是必须映射的部分,虚线反之。可以通过Model选项更改虚线的映射条件,并在Hierarchy里匹配正确的骨骼节点。也可以使用自动匹配,让Unity根据数字人结构自动进行匹配。
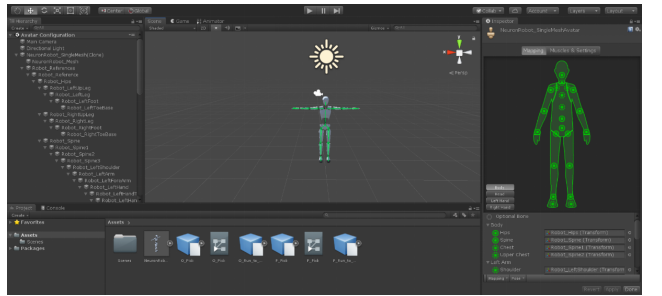
Unity骨骼匹配界面
匹配好骨骼后,在Unity中创建并打开场景,并导入两个之前已经创建好的的数字人。
图4-6Unity创建场景
创建AnimationController,将运动动画导入,并添加到数字人Animator组件中。Animator Controller允许您为角色或对象安排和维护一组动画剪辑和相关的动画转换。在大多数情况下,当某些游戏条件发生时,可以使不同的动画在当前环境下实现来回的切换,就像当空格键既可以用于步行动画剪辑,也可以用于跳跃动画剪辑,它们之间的切换所需条件仅仅是按一下空格键。但是,即使你只有一个动画剪辑,你仍然需要将它放入Animator Controller中,以便在GameObject(游戏对象)中使用它。Animator Controller有对其中使用的动画剪辑的引用,可以通过多种途径,例如是一个流程图,也可以是一段程序,最终的目标是将游戏对象和动画剪辑流畅的切换。
运行场景,两个数字人分别被源数据和预测生成数据驱动,查看两个数字人的运动,观察预测效果。
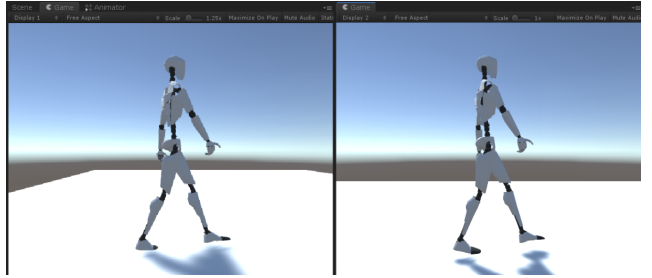
图4-7场景运行效果
总结
本文采用了在MXNet深度学习框架下搭建的LSTM长短期记忆网络
人工神经网络已成功地应用于各种实际问题。虽然对不同类型的人工神经网络进行了大量的改进以提高其性能,但是无论何种人工神经网络都不是百分之百完美的,设计和适用时都是有限制的。通俗上来说,典型的人工神经网络模型在大规模应用时性能有限,可用的训练数据有限,或者两者兼而有之。现有的DHMs已经足够成熟,可以为不同条件下的不同任务和场景提供准确和有用的结果。
这项工作已经证明了人工神经网络在基于物理模拟库的实时模拟动态人体运动方面的成功应用。神经网络的使用显示了提供实时运动预测的一个完整的身体DHM,使用各种任务。特别地,RNN被成功地应用为一个强大的工具,可以快速地训练,并且没有任何记忆问题,无论问题的大小。这为基于物理的人类模拟提供了一种新的变体,提高了计算速度,从而使人们能够更有效地进行权衡分析,以从人类系统集成的角度评估产品和过程。
与任何回归分析或元模型一样,预计近似解至少会偏离源模型的最小值。我们证明,当客观地和主观地评价时,这种偏差是可以接受的。与数字人类建模的情况一样,虽然主观结果在比较时可能看起来相同,但定量结果可能略有不同。
尽管如此,与预测-动态源模型相比,ANN模型表现良好。利用人工神经网络进行运动预测,成功解决的主要问题是产生PD输出的计算时间。时间从几分钟减少到几分之一秒。即使是需要非常精确的结果的任务,比如,在盒子上跳,模拟的准确性,正如所展示的,被保留了下来。在这样的任务中,准确性是至关重要的,特别是当手和脚在执行任务的某个时刻应该与盒子接触时,网络结果显示这种约束的视觉满意度。
从概念上讲,深度学习的过程反映了人们实际学习和执行任务的方式。一个人对特定情景的反应,在一定程度上是先前经历的情景的集合。可以肯定的是,理性思维和认知外推法发挥了作用。然而,所提出的方法展示了一个将学习历史融入任务模拟的模型。事实上,它提供了一个平台,在这个平台上,人们可以研究各种各样的经验如何影响性能,以及学习集合的变化如何改变模拟。这对训练团和教育的研究和设计具有实际应用价值。
初步研究了RNN在人体建模中的应用,为今后的工作提供了一些机会。首先,与大多数ANN应用程序的情况一样,需要进行工作来确定任务的最优训练用例数量。为了确保满足接触约束,未来的工作应该包括在网络建设中增加约束。此外,我们建议训练网络来预测关节中心位置,而不是关节角度,以产生更准确的结果。对于误差较小的关节角进行预测,有时会产生不准确的结果,而对于误差较小的关节中心进行预测,仍然可以得到可接受的结果。虽然网络训练使用的模拟(预测动态)是假定有效的,虽然这项工作提出了基于主观验证的方法的可行性,来自实际的人工神经网络的预测应该直接和客观地进行验证。最后,如关于关节扭矩的建议,需要进一步研究训练过程中正常化输出的益处。
参考文献
[1]Bataineh M H. New neural network for real-time human dynamic motion prediction[J]. 2015.
[2]Gundogdu O, Anderson K, Parnianpour M. Simulation of manual materials handling:Biomechanial assessment under different lifting conditions [J].Technology and Health Care, 2005, 13(1):57-66.
[3]刘明周,蒋倩男,扈静.基于面部几何特征及手部运动特征的驾驶员疲劳检测[J].机械工程学报,2019,55(02):18-26.
[4]Xue-Ping Chen,You-Mei Lu,Ju Zhang. Intervention study of finger-movement exercises and finger weight-lift training for improvement of handgrip strength among the very elderly[J]. International Journal of Nursing Sciences,2014,1(2).
[5]Arnaud Badets,Mauro Pesenti. Creating number semantics through finger movement perception[J]. Cognition,2009,115(1).
[6]陈解元. 基于视觉的人手信息采集与建模[D].中北大学,2016.

1、如文档侵犯商业秘密、侵犯著作权、侵犯人身权等,请点击“文章版权申述”(推荐),也可以打举报电话:18735597641(电话支持时间:9:00-18:30)。
2、网站文档一经付费(服务费),不意味着购买了该文档的版权,仅供个人/单位学习、研究之用,不得用于商业用途,未经授权,严禁复制、发行、汇编、翻译或者网络传播等,侵权必究。
3、本站所有内容均由合作方或网友投稿,本站不对文档的完整性、权威性及其观点立场正确性做任何保证或承诺!文档内容仅供研究参考,付费前请自行鉴别。如您付费,意味着您自己接受本站规则且自行承担风险,本站不退款、不进行额外附加服务。
原创文章,作者:1158,如若转载,请注明出处:https://www.447766.cn/chachong/133057.html,