1.引言
1.1选题意义
人工智能是现今最热门的研究领域之一,其中研究人工智能的核心方法就有机器学习。最初是希望计算机拥有一定的自我学习能力,从而可以自我获取知识、提高智能性。随着机器学习领域的不断探索,将人类的学习能力赋予机器已经不再是机器学习的主要目标了,研究目标转向了可以有效地由计算机实习数据分析技术。然而机器学习需要采集大量的环境反馈,累积奖赏值,从而获得最优决策,这一过程需要大量的数据采集、分配和计算,对于计算机的能耗有着较大的要求。为了节约能耗,我们需要通过强化学习,优化算法结构和效率,从而用更少的能耗找到最优决策,这样可以减少对硬件的要求,将机器学习推广到更多领域中。
强化学习,是机器学习领域中一种重要的学习方法,强化学习的应用烦恼为涵盖了智能控制、机器人及分析预测等众多领域。在无线通信领域中,无线资源的需求日益增加,如何高效有序的将信道频谱资源进行分配,也是节约能耗的一个关键问题。本文通过强化学习的方法来对频谱接入,和信道分配进行动态规划,目的是为了合理运用现有资源,充分改善资源利用率,为实现动态频谱管理,和减少频谱资源需求,提供了一定的实践基础。
1.2国内外发展状况
国内外对于强化学习都有众多的研究成果和应用实例,目前发展应用较多的几个方面有:在调度管理中的应用:调度问题是一种随即优化控制问题的实际例子,解决这种问题将会带来很高的经济价值。比如,Crites和Barto就把强化学习算法应用到楼层电梯系统中。通过强化学习算法,采集记录乘客的位置和目标楼层,动态规划电梯的行径,其效率远远超过了一般的动态规划。另外,强化学习的应用例子还有很多,如,在蜂窝电话系统中动态信道分配及机器调度问题。
在机器人技术中的应用:机器人研究领域是强化学习最适合,也是应用实例最多一个领域。近年来国际上兴起了将强化学习应用到智能机器人领域的研究热潮。Hee RakBeem为了可以让陆上移动机器人导航系统可以完美避开碰撞物和达到目的地两种行为,采用了模糊逻辑和强化学习的方法,使得机器人导航系统得以优化。
国内目前的现状:国内目前处于新兴发展阶段,对于强化学习和人工智能方面逐渐赶上外国发达国家,如今已有不少的关于强化学习的成果,应用于多个行业及领域。如基于时隙CSMA的水声无线传感器网络节能强化学习算法,为了达到以最低能源消耗传送数据包到汇聚节点的目标,出了一种节能的基于时隙CSMA(载波帧听多访问)的强化学习算法。分析了时隙CSMA的强化学习协议的可行性。并研究了每个节点的平均能耗与子信道个数之间的关系,提高了传感器的使用寿命。
1.3展望
在最近的研究发展来看,研究人员越来越重视强化学习理论和应用,可是由于现实问题的复杂度过高,强化学习在实际工程中的应用依旧存在很多问题,如环境的不完全感知;多agent分布式的问题;分层强化学习的问题等,尽管如此,强化学习已开始逐渐应用于人工智能、机器人控制和工业控制等系统,运用强化学习算法来解决客户端的学习节能问题,可以将机器学习推广到更多领域。通过强化学习的方式,还可以动态优化神经网络结构,使得机器学习能够更高效,更有目的地处理指定问题,缩短机器学习的学习周期,减少能耗。如果强化学习能够有效利用在各行各业,在调度、提高速率、合理分配资源等方面都可以得到极大优化,前景广阔。
1.4目前强化学习遇到的问题
在时间信用方面存在着分配问题,智能体所作出动作不仅决定立即奖赏,还可能会影响到下一状态的环境。导致智能体不仅要考虑立即奖赏,还要考虑下一状态所带来的奖赏。奖赏延迟越多,学习算法就需要进行的尝试次数就会越多,导致学习消耗额时间增加,学习时间的增加就会使得智能体运算消耗变大,造成资源浪费。
学习过程中存在着探索和利用两个问题,如何对这两个过程进行一个折衷考量也是强化学习中的一个关键问题,通过利用已知的动作,智能体可以得到一个稳定奖赏,但是相比于利用已知动作获得奖赏,探索新的动作可以获得更高的奖赏,但是过多的探索又会使得系统消耗更多的资源。
强化学习是一项与环境紧密联系在一起的学习算法,外界环境的复杂度与反复无常的变化都会影响智能体的学习过程,动态地规划学习过程中的探索和利用过程也是一个亟待解决的问题。
强化学习算法从优化函数和状态空间中获得有用的策略,一旦系统复杂度变高,则要大量的参数来描述,这样状态到动作的映射组合量会大量增加,学习的时间也会极大变长,那么得到决策优化的过程将会相当漫长,增加了任务的探索负担,最终影响决策优化效率。
强化学习算法是依赖于外界环境状态的,而学习算法最终要完成决策优化,是需要算法具有收敛性的,一旦外界环境和系统变得越发复杂,那么智能体无法精确地得到所有环境状态,由此会使得学习算法无法在实际环境中得到收敛,这么一来不解决算法收敛问题,算法的应用就难以在复杂工程中得到应用。
1.5研究方法的探索
由于信道选择可以看作为一个概率事件,这里可以通过蒙特卡洛方法来对通信模型进行仿真。在通信中有多种指标可以衡量系统对信道的利用率,这里我们主要通过考虑信道容量这一指标来观察Q学习是否可以优化改良信道的选择问题,信道容量还可以侧面衡量出信息的传输速率。
强化学习算法有一个比较关键的问题,就是如何对探索过程和利用过程进行一个折衷,由于本文进行的通信系统模型比较简单,我们通过模拟退火温度的方法,来对Q学习Q值矩阵的权重进行调整,从而一定程度上解决探索和利用的矛盾,使得Q学习最终可以收敛。
2.系统模型及理论支持
2.1马尔科夫决策过程
大部分的强化学习算法都是根据马尔科夫决策过程发展过来的,所以在实用强化学习算法前,需要对马尔科夫决策过程进行了解。
马尔科夫决策过程:是通过马尔科夫过程理论延伸出来的一种决策过程,这是一种从随机动态系统中,获得最优决策的过程。马尔科夫决策过程是指在仿佛的周期循环过程中,决策者不断地观察随机动态系统(这个系统具有马尔科夫性),然后序贯地作出决策。详细说明就是决策者在每一个时刻观察到的状态,从决策者可以作出的所有行动中选择一个行动,以此行动作为决策,系统达到下一个状态是完全随机的,并且这个状态转移的概率是遵循马尔科夫性的。决策者通过观测到的新的状态,作出新的决策,循环反复进行。马尔科夫性指的是一个随机事件,通过未来的发展,具有一定的概率规律,和历史无关的一种性质。总的来说就是一种状态转移概率的无后效性。
2.2强化学习
强化学习是一种机器学习方法,主要是通过智能机与环境交流联系,并通过动作对环境进行反馈,得到的环境反馈作为智能机的输入。强化学习主要是利用智能体不断与环境进行交流和接受反馈的思路,主要利用的方法是一种试错的模式,然后智能体可以在状态空间到动作空间的映射中获得学习,改善决策,并不断累计奖赏值。强化学习算法过程中,一般是由环境来发送信号的,这个信号主要是为了对Agent选择决策出来的动作进行判断,判断环境带来的奖赏是正奖赏还是负奖赏,这个环境所反馈回来的信号是不会对智能体选择动作作出直接影响的。所以Agent就需要靠累计的奖赏总结经验进行学习。通过这种方式,Agent可以通过获得外界环境反馈得到的信号来优化自己的决策过程,进过足够的迭代学习,最终可以得到一个最优的决策,学习过程就如图1所示。


强化学习的处理一般是通过建立马尔科夫决策过程,简称MDP。一个MDP一般被一个五元组{S,A,P(st,at,st+1),r(st,at),Q;st,st+1∈S,at∈A}表示,当中S表示为连续的状态空间,A表示为连续的动作空间,P(st,at,st+1)表示为Agent处于状态st时,执行动作at之后,转移到下一个状态st+1的概率,r(st,at)表示在st时执行动作at之后得到的奖赏,Q表示状态-动作值函数。
从文献[8]中了解到,强化学习算法有多种实现方法,也有多种算法实例,如动态规划(DP)、蒙特卡洛算法、瞬时差分学习算法(TD算法)、Q学习算法、Sarsa算法和Dyna学习算法,本文主要利用Q学习算法来进行信道的选择优化问题。
2.3 Q学习
从文献[7]中了解到了Q学习的主要原理和迭代算法原理,由此可以得到Q学习的一些相关实现方式。
首先要了解Q学习的概念和形式,Q学习是一种由动态规划理论中总结发展得出的,这是一种与模型没有关系的延迟学习方式。Q学习算法的形式为:
(1)
其中是在状态s下,智能机通过执行动作a,所获得的最优的奖赏值的总和。
定义为在状态s下的最优值函数,则
(2)
说明对现有状态值Q进行反复的反应,就可以获得该状态下最优的动作决策,也就是当前的状态即动作的Q值在这个数值中包含了所需信息,就可以说明,在状态s下,智能体选择动作a时,智能体将会获得累计奖赏的最大值。
由此可以得到Q学习的迭代公式为
(3)
该算法的一个交互过程如图2所示:
图2智能体与环境的交互过程
2.4 Q学习的信道选择算法
本文将Q学习算法应用与机会频谱接入系统中的信道选择策略中,在接入体系和信道选择框架下,用户通过接入策略和选择信道方式来侦听频谱,探索环境中的信道是否处于空闲状态,然后进行信道接入决策,以此获得奖赏值,完成与环境的交流和互动。通过建立一个有限的马尔科夫决策过程,设定状态空间S、动作空间A、状态转移函数和回报函数r,具体的体系框架如图3所示。
图3信道选择和接入体系框架
状态空间S:S是由n个状态组成的,每次用户所处的频带在Bi上时,且同一时间上没有其他用户在这个频带上时,就选取Si作为现态。
动作空间A:A是由n个行为动作构成的,当动作ai被选择执行时,总能是状态变为si,如果系统中存在大量频带个数时,动作与状态的组合量就会极大增多,使得内存空间占用过大,不过可以通过神经网络的方式将其解决。
转移状态函数,在当前的状态下执行动作ai,使得系统从现态进入下一状态。
回报函数:通过系统的性能指标,系统在执行动作之后,用户获得了可供使用的信道,如果得到一个较大信道容量,就可以设定这次的回报为正回报,剩下的情况的回报为0。从而得到回报的公式为:
(4)
这里的表示信道是否处于空闲状态,Td表示时隙中的数据传输时间,Ts表示为信道的感知时间。In表示的是接收端是否正确的接受到了信息,这里的和In都为示性函数,都是表示是为1否为0.
信道容量:通过信道容量可以用来描述一个信道的性能,透过信道容量可以反映出信道上所能传输的最大信息量,信道容量的大小与信源是没有关系的。在不同的输入下,他们的概率分布也不一致,交互信息也一定会有最大值,这个最大值就可以被定义成为信道的容量。只要我们知道转移的概率矩阵,我们就可以计算得出该信道的信道容量。
Cn为当前所选择的信道的信道容量,也可以理解为信息在信道上的传输速率,通过香农公式可得:
(5)
由此可以得出系统的平均信道容量为:
(6)
其中,m所代表的是系统的平均数据传输速率。
2.5Boltzmann学习规则
在智能机学习过程中,每进行一次学习时我们并不知道是一哪一种策略动作进行选择的,这种学习算法有一定问题,假设智能体在开始学习的时候,通过迭代学习找到了比较高的Q值,动作就会被这个Q值限制,从而不会去探索更好的策略,并且Q学习最终要收敛到一个稳定的状态,需要每一个动作反复不断的探索。为了可以符合Q学习的收敛特性,必须要做出探索和决策之间的折衷选择。在阅读了文献[1]与文献[2]中关于利用Q学习算法来进行信道预测与接入的问题中,他们采用了Boltzmann学习规则,所以我们在讨论信道接入问题时,也想通过采用了Boltzmann学习型规则结合模拟退火过程来达到Q学习的收敛。我们根据Q值矩阵中元素的大小,对所有可能的动作进行概率赋值,这里有条件概率公式:
(7)
这个公式表示为,在状态s下,通过动作选择到信道an的概率,表示模拟退火温度,当退火温度值很高时,Q值的影响很小,可以近似看为随机选择,没经过一次学习,退火温度值减少,这样Q值的影响逐渐增大,这时Q值中较大的部分就有更高的概率被选择,这样就可以从探索逐渐想利用方向变化,Q学习过程也会逐渐收敛。
2.6模拟退火过程
由于学习过程是一反复迭代,累计奖赏的过程,也可以视为一种试错的算法,所以刚开时进行学习时,R值矩阵和Q值矩阵均不可能达到最优,而且在学习开始时,Q值由于回报函数获得奖赏值过大,导致Q矩阵的数值也较大,这么一来这个过大的Q值就会影响决策,而很多新的环境状态还没有探索到,所以在学习初Q值所占的权重需要一个较小值,这样才能使得在学习开始时不会由于出现过大的Q值而限制智能体的探索。为了处理学习过程中探索与利用的平衡问题,我们通过文献[10]中的模拟退火算法来对参数的权重进行适当的调整。通过设置初始退火温度,以一定的参数为负指数规律递减,一旦达到设置的最终温度,将完成这次学习,在退火温度逐渐减少的过程中,Q值矩阵的权重逐渐增加,从而达到开始过大的Q值不会影响我们的探索过程。
2.7 OFDM的信道接入方式
由于我们需要建立一个通信模型来对所作的优化进行仿真,本文也采用了与文献[1]中一致的通信信道接入方式——OFDM信道接入方式。OFDM全称为正交频分复用技术,OFDM技术常用于实现多载波传输方案的实现,它的调制和解调是基于IFFT和FFt来实现的,OFDM是现阶段通信方面应用最为广泛的多载波传输方案。
由于一个信道一次只传输一路的信号的话,是显得十分奢侈的,通过采用频分复用方式,就可以充分利用每一条信道的带宽资源。
OFDM的主要思想就是,通过把信道划分成为多个正交的子信道,把速度高的数据信号,分为许多的并行的速度低的子数据流,把这些数据流分别调制到每一个正交的子信道上进行输送,通过正交传输的方式可以减少子信道之间的相互干扰,不仅如此,还可以通过子信道上的信号带宽很小,可以把子信道看作平坦性衰落,来消除码间串扰,每一个子信道的信道均衡也会变得容易。
2.8系统模型
在认知无线电系统中,N个不相互干扰的OFDM载波频段构成授权频谱,设定每一个信道的带宽是Bn。S(t)=[S1(t),S2(t)…Sn(t)]表示为信道状态,这里的Sn(t)代表着在t时刻n信道中的信道状态。snr代表者客户端用户之间的信噪比。能量和硬件的限制面导致了用户每一次探索,并且利用频谱的机会都是独立的,不考虑用户之间的相互影响。
每一次用户发出一个信息时,接受端会根据现在所处的信道选择策略,对一个信道进行选择侦听,结合之前锁观察和经验,从而判决信道是否处于空闲状态。
2.9蒙特卡洛方法
由文献[8]中引出的蒙特卡洛方法,我们需要了解该方法的原理,以及它的实现步骤。当我们要解决的问题是一个随机事件出现的概率,通过实验的方法,以这种事件出现的频率来估计这一随机的概率。
蒙特卡洛方法可以分为三分个步骤:
(1)构造或描述概率过程:将本身具有概率性质的问题通过建立正确的描述和模拟概率事件的环境,来对概率进行求解;如果不是具有概率性质的问题,那就建立一个人为的概率事件环境,从中取某些适合的参数来对问题进行描述,从而得出问题的答案。
(2)实现已知的概率分部抽样:在构建创造出一个概率模型后,几乎所有的概率模型都可以被看作是由许多概率分布组成的,所以,构造一个确定的概率分布的随机变量,这就是采用蒙特卡洛方法模拟实验的一般方式。
(3)建立各种估计量:通常来讲,经过创造一个概率模型,并且可在模型中抽样后,就是经过模拟实验后,就可以从中确定一个随机变量,作为所要求的问题的解,我们称它为无偏估计。透过构建各种各样的估计量,就可以看作是对模拟实验结果进行考量和记录,最终可以从这些结果中获得所求问题的解。
3.算法流程及实现过程
3.1实验步骤
首先通过建立一个通信系统模型,将所需参数逐一进行设置,建立一个符合实验要求的客户端之间的通信系统模型。在这个模型的基础上,首先进行随机接入信道的仿真测试,通过matlab的随机数生成函数,随机选择决策动作,达到随机接入信道的效果,在通过香农公式,计算出系统的平均信道容量,并绘制出通信次数和平均信道容量的曲线。
完成随机信道接入后,进行Q学习信道选择算法实验。首先要将Q迭代函数、R的回报函数与接入概率函数进行联系,使得学习结果可以通过回报来影响决策,从而优化决策策略。算法的应用上,首先要对算法的各项参数进行初始话,保证在实验开始时,回报函数和Q值函数均处于初始状态,这样才能保证一开始信道的选择是处于随机选择状态,然后把回报函数与通信模型进行联系,这样就可以把环境反馈与智能体联系起来,通过Q值迭代公式(3),获得新的Q值,从而影响决策。再通过系统的平均信道容量来对结果进行衡量分析,假如学习后系统的平均信道容量得到提升则可说明Q学习信道选择算法可以有效优化信道选择过程,假如学习后系统的平均信道容量和平均接入大致,甚至低于平均接入方法,则说明实验存在问题,需要考虑优化算法或者寻找其他的解决方法。最终得出结论,讨论算法的可行性和可靠性。
3.2算法流程
(1)初始化:设定一个N阶方阵为一个元素全为0的矩阵,设置Q迭代公式中的折现因子(折现因子越大,学习越考虑对未来的奖惩,立即奖赏的影响会比较小),设置学习过程中的初始退火温度和最终的退火温度,通过随机先择一个起始动作来选择一个状态,作为起点。
(2)通过Boltzmann的学习规则,通过条件概率函数来选择一个动作,对信道进行访问,在动作执行时,需要通过侦听信道来判断目标信道是否处于空闲,若是处于空闲状态,则接入信道,若处于忙碌状态,则反馈的回报为0,重新选择接入策略。
(3)当接入信道后,进行信道传输,如果接受端未能收到信号,则回报为零,需要更新选择策略,如果接收端成功接受到信号将会成功获得回报,通过回报函数计算奖赏值。
(4)智能体通过回报函数计算得到的R值记录到值矩阵,再由Q值迭代公式,更新Q矩阵。
(5)完成Q值迭代后,对退火温度进行衰减操作。
(6)将求得的Q值和经过衰减的退火温度回代到概率函数之中,从而达到更新选择策略的目的。
(7)进入下一个状态,返回过程(2),直到迭代完成。
图5 Q学习算法的算法流程
以下再列出Q学习的算法描述:
Initialize arbitrarily;
Repeat(for each episode);
Initialize s;
Repeat(for each step of episode);
Choose a from s using policy derived from Q(e.g.,-greedy);
Take action a,observe r,s’
;
;
Until s is terminal.
3.3仿真过程
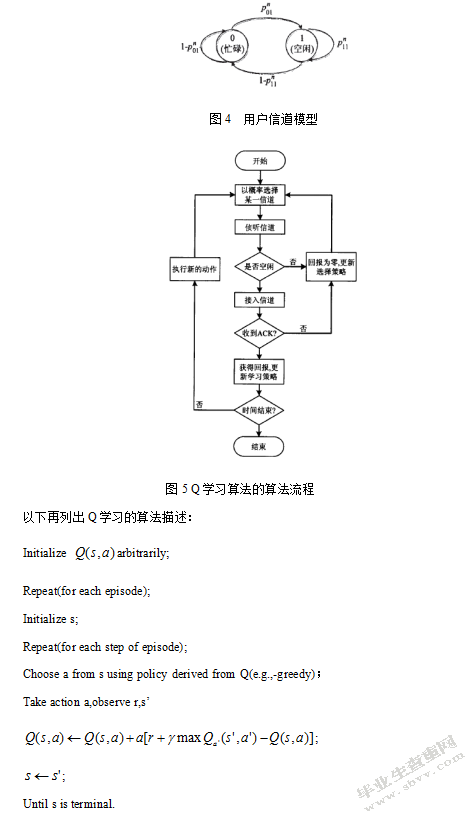
这次实验所做学习机制可以适用于用户间所处的环境不明,信道条件不了解的情况,为了便于探求提出的算法是否有效可行,对于通信环境进行了一些理想化假设。通过设定一组用户,用户间可供选择的信道为7个,这7个信道的负载量和信噪比如表1所示,每一个信道的信噪比通过预设来进行确定。假设每一条信道的信道带宽为B=1,Q迭代公式中的折现因子=0.9,折现因子的设定值较高,主要是为了学习目标着重为未来回报,减少立即回报的影响。起始退火温度设定为,衰减速率则为折现因子的数值,通过指数衰减的形式衰减值最终退火温度。仿真原理利用的是蒙特卡洛方法,首先在未经学习时,用户可以认为是随机接入复合条件的信道之中,这样系统在这1000次通信中的平均信道容量就会趋于各条信道的平均信道容量。在完成了随机的信道选择过程后,进行经过Q学习的信道选择。再开始学习时,由于有初始退火温度较大,动作的决策几乎可以看作是随机选择,随着通信次数的增加,Q值矩阵的不断迭代,还有退火温度的减小,逐渐影响概率函数,学习达到收敛时,我们的系统平均信道容量也收敛到了最大值,这时的平均信道容量值会接近最优信道的信道容量。
由于用户间的信道通信,具有复杂的环境干扰,和其他用户占用信道的可能,我们目标是为了探求Q学习指导信道选择策略的可行性,所以在进行通信环境模拟的时候,将许多复杂变量都做了理想化处理,假设每一次通信只有一组发送和接受端,为了忽略其他用户通信造成的信道占用现象,所以在信道侦听的过程中,信道都是默认处于空闲状态。信道的信噪比也通过理想化处理,每一个信道都对应固定的信噪比,这样相对稳定的环境下,学习效率会得到提高,可以更加直观的观察到学习所带来的影响。
信道1信道2信道3信道4信道5信道6信道7
负载量0.90 0.88 0.45 0.44 0.23 0.43 0.21
信噪比20 12 13 9 18 8 12
表1模拟通信环境的各信道参数
4.结果分析
4.1数据分析
通过matlab的模型建设和算法编写,我们得到了如图所示的结果。在没有通过强化学习进行信道随机选择的过程中,系统经过1000次的模拟通信,得到的平均信道容量与7条信道的平均信道容量大致相等,在前几次的通信过程中,由于样本数目较少,所以呈现出来的是无规律的散乱分部,在进行的次数增多后,随机接入方法的平均信道容量逐渐稳定在了平均值,这么看来通过随机接入方式来进行信道选择,无法充分有效地利用目前最有效的信道来进行信息交流,这样传输速率受到限制,从而增大了通信的能耗。
在经过Q学习机制的信道选择策略后,可以看出,在学习刚开始时,其结果与随机接入一样,主要呈现出来的是一种随机的信道接入,造成这种结果的原因是,在学习开始时我们关注的是一个探索的过程,还不是利用回报函数进行决策优化的过程,由于退火温度值较大,Q学习影响信道接入概率函数的权重很小,所以智能机在作出动作决策时,还是基本可以看作是随机选择,故呈现出来随机选择的效果。在经过一定次数的学习后,Q值矩阵影响越来越大,信道接入策略就会逐渐向优化后的决策方向收敛,如图6所示。在稳定的通信环境下,用户就会最优先选择信噪比最大的信道来进行通信,这么一来,用户的平均信道容量就会得到提高,信息传输速率,吞吐率等方面也会有一定的改进,可以充分利用好的信道资源,通过实践调度,可以更好的节约信道资源。
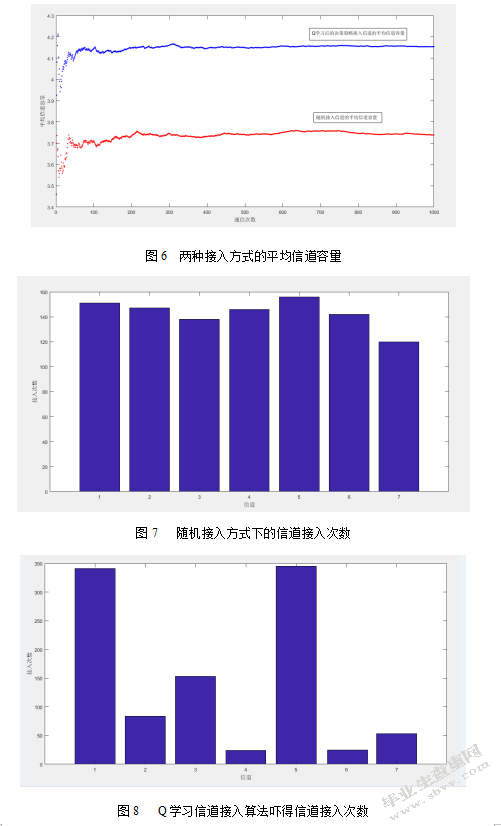
通过信道的接入次数对比也可以发现,在随机接入模式下,每一条被信道被接入的机会大致相同的,如图7所示,系统请求接入信道时,并不会考虑信道的信道容量,只会随机选取信道进行信息传输,这么一来,多次信息传输后,系统通信的平均信道容量自然会趋于所有信道容量的平均值。
相比之下,通过Q学习信道接入算法优化后,信道接入信道容量最大的两条的次数明显增加,而信道容量最低的那一条信道就很少被接入,如图8所示。这里信道1和信道5有着相近的信噪比,且都比其他信道大,所以在经过学习后,这两个信道有了较大的接入概率,充分的表现出了对信道选择策略的优化。这么一来,极大地提高了系统通信的平均信道容量,使得传输效率和传输质量得到提升,降低了能耗。
4.2实验中存在的问题和可行性
由于本实验构建的是一个比较简单的单向单个用户的信息传输过程,所以建立的系统模型也是一个十分稳定的通信系统。在实际的现实工程上应用时,信道的信噪比,信道的带宽、负载量都是影响信息传输的重要因素,这些参数没办法像实验一样是个恒定的参数,所以每次通信的外界环境都可能会有较大的变化,这么一来学习算法中探索和利用的关系就会变得更加复杂,可能通过学习改善决策后,当前的最优策略,由于环境变化,这个动作所带来的选择已经不再是优秀的选择,那么智能机又要重新探索来改善累计奖赏,这么一来构建一个动态规划探索和利用之间的权重就显得尤为重要。
虽然现实环境千变万化,但是通过Q学习的信道接入选择策略,还是可以一定程度上优化决策策略的,就可以通过经验提前判断接入的最优路径,会按照学习后的概率分部函数,对接入信道进行选择,这么一来在环境变化不大的通信条件下,可以极大的提高传输速率,传输速率提高,客户端所需要消耗的资源自然会得到节省。
本次实验的实验结果提升效率十分明显,是由于环境的稳定和信道数目较少所造成的,在信道数目较多,环境变化的条件下,通过增加探索时间和改进回报函数,就可以解决单组用户间的通信节能问题。但在多组用户交叉通信的问题中,由于用户的动作空间与状态空间的映射数量极大增加,学习复杂度过大,对于这次研究无法深入探索,故该方法在多用户间的通信节能问题还有待探究。
5.结束语
本文研究的是客户端基于学习算法的节能问题,主要在通信信道接入方面来作出优化。目前有通过设定玻尔兹曼机利用神经网络的方式来实现信道选择的研究,我们在此方法上进行改进,利用强化学习算法,通过环境反馈的回报值,来优化玻尔兹曼机中的概率函数,最终改变决策策略,使得客户端可以有效提高接入最优的信道的概率,提升通信系统的平均信道容量,加大信息传输速率,合理运用信道资源,达到节能的目的。通过仿真结果可以看出,客户端可以通过与环境的不断交互,从中获得经验,进过学习和优化策略,可以有效提高客户端接入信道的平均信道容量。本文还通过对Q学习算法的探究,在面对Q学习算法的探索和利用的折衷问题时,通过查阅资料,引入了模拟退火模型来一定程度上解决探索和利用的问题,不过这种方式也有一定的局限性,就是需要在相对稳定的环境下,因为在达到最终退火温度后,学习算法就是着重于利用,探索就会有所欠缺,环境的改变是需要重新探索的,所以这个方法也受限于这一点。本文的研究主要针对的是单个客户端通信过程,在面对多对多复杂通信时,这种学习策略的可行性还有待研究。
6.参考文献
[1]赵彪,李鸥,栾红志.Q学习算法在机会频谱接入信道选择中的应用[J].信号处理,2014,
[2]张凯,李鸥,杨白薇.基于Q-learning的机会频谱接入信道选择算法[J].计算机应用研究,2013
[3]张士兵,王惠建,邹丽.基于POMDP模型的分布式机会频谱接入算法[J].南京邮电大学学报(自然科学版)
[4]彭晓东,肖立民,钟晓峰,周世东.基于信道质量信息的机会频谱接入策略[J].清华大学学报(自然科学版)
[5]张兆城,杨震.基于联盟的认知无线电机会频谱接入[J].南京邮电大学学报(自然科学版)
[6]叶芝慧,冯奇,王健.基于学习策略的动态频谱接入信道选择及系统性能[J].东南大学学报(自然科学版)
[7]刘忠,李海红,刘全.强化学习算法研究[J].计算机工程与设计
[8]李瑞.强化学习主要算法的研究[J].渝西学院学报(自然科学版)
[9]王培屹.浅析强化学习算法研究与应用[J].科技信息
[10]陆平静,李宝,张英,易任娇,庞征斌.一种基于改进模拟退火算法的程序性能优化参数搜索算法
[11]KAELBLING L P,LITTMNN M L,MOORE A W.Reinforcement leurning:A survey[J]
[12]张汝波.提高强化学习速度的方法研究[J].计算机工程与应用,2001
[13]张汝波.强化学习理论及应用[M].哈尔滨:哈尔滨工程大学出版社,2001.
[14]童亮,陆际联,龚建伟.一种快速强化学习方法研究[J].北京理工大学学报,2005
[15]杨晓燕,杨震,刘善彬.基于预测机制的认知无线电机会频谱接入[J].重庆邮电大学学报(自然科学版),2009,(1):14-19.
[16]李娜,李鸥,孙乐,孙武剑.基于概率预测的动态频谱接入信道选择方法[J].信息工程大学学报,
[17]CICHOSZ P.Truncating temporal differences:On the efficient implementation of TD(λ)for reinforcement learning[J]
[18]MOOR A W,ATKESON C G.Prioritized sweeping:Reinforcement learning with less data and less real time[J].
[19]AKYILDIZ I F,WON-YEOL L,VURAN M C.A survey on spectrum management in cognitive radio networks[J].
[20]REDDY Y B.Detecting primary signals for efficient utilization of spectrum using Q-learning[A].
7.致谢
进过大学四年的紧张学习时光,我系统地学习了信息工程的各方面知识,十分佩服各位专业老师的学识,从中我不仅学到了工程方面的理论知识,还学到了很多为人处事,研究实践的方法,在这里表示真挚的谢意。在论文即将完成之际,我要感谢我的导师靳若凡老师。在论文撰写的整个过程中,从论文的选题、到任务书、开题报告、实验仿真过程、还有最后的论文撰写,靳老师都给我提出了许多宝贵的经验和指导。靳老师对我实验和方向多提出的问题都是一针见血,每一次指导都使我有醍醐灌顶的感觉。给我感受最深的是靳老师的严谨治学的态度,无论是从格式规范、论文要点还是实验过程,靳老师都不厌其烦,及时的给予我帮助,使我能够顺利得完成论文撰写。
我还要感谢学院的每一位老师,是老师们耐心的教学和不倦的指导,丰富了我的知识体系,打下了良好的基础。是学院老师的细心教导,提供了这次实验的知识基础,也为我提供了良好的实验方法,才能使得这次毕业设计能够顺利完成。
在此还要感谢我的各位同学,多位同学在我论文撰写过程中,给予我了极大的信息支持。最后感谢学院的所有老师,是你们严谨无私的教学态度,让我的知识得到了极大丰富,还教会了我对现实问题的分析和解决,继而提高了自己处理工程问题的能力。
最后感谢深圳大学,为我提供了一个良好的学习氛围,学校对于实践项目提供了大量的实验耗材和实验场地,也极大的提高了学生的实践能力,为我们踏入社会工作奠定了坚实的基础。
【abstract】Now mobile client number increasing,the communication channel resources gradually difficult to meet the demand,this paper adopts a channel selection algorithm based on the Q learning,through the establishment of point to point communication channel between the user model,and to establish a reasonable return function,makes the smartphone can improve behavioral decision through summing up experience,then makes the final can get the choice of the optimal decision.By simulation results that the algorithm can effectively improve the average user access channel channel capacity,by expanding the channel of the average capacity,improve the information transmission rate,to make full use of good channel,the effect of channel resources saving.
【key words】channel selection;Q learning;energy saving problem.
下载提示:
1、如文档侵犯商业秘密、侵犯著作权、侵犯人身权等,请点击“文章版权申述”(推荐),也可以打举报电话:18735597641(电话支持时间:9:00-18:30)。
2、网站文档一经付费(服务费),不意味着购买了该文档的版权,仅供个人/单位学习、研究之用,不得用于商业用途,未经授权,严禁复制、发行、汇编、翻译或者网络传播等,侵权必究。
3、本站所有内容均由合作方或网友投稿,本站不对文档的完整性、权威性及其观点立场正确性做任何保证或承诺!文档内容仅供研究参考,付费前请自行鉴别。如您付费,意味着您自己接受本站规则且自行承担风险,本站不退款、不进行额外附加服务。
原创文章,作者:写文章小能手,如若转载,请注明出处:https://www.447766.cn/chachong/13671.html,