摘 要
近些年,由于互联网技术的飞速发展,以及XX对经济发展的扶持,使得民营企业成为了一个新的笑话。由于各种原因,中国的中小企业在不同的市场上进行了大量的信贷业务,但是由于中国目前还没有建立起完善的信贷评估制度。目前,中国中小型企业面临着越来越多的诚信问题。建立健全的信贷评估制度,是建立和保证建立健全的信贷评估制度,在推动中小型企业发展的一个关键的背景下,它具有巨大的使用价值和潜在的潜在的业务信息。该资料可以作为公司借贷、银行信用危机、决策等重大问题的基础。
着重探讨了 CART的分类方法,利用数据挖掘技术对中小板上市公司的财务状况进行了深入的分析,得到了10项金融评价指标,并采用 AHP方法对其进行了评价。在对数据采集后的各指标进行加权后,采用普尔公司的综合评价方法,对一家规模中等规模的电力 A公司进行了信贷评价,并对其进行了分析。
关键词:中小企业;信用评估;CART;层次分析法
绪论
课题研究的背景和意义研究背景
在当今社会在进行信用评级的过程当中,也是对于信用风险的整体工作,我们要对这些机会主义来进行发展,从而能够找出在合同的过程当中所提供的各项性质,能够尽量降低在信用风险过程当中的重要性能。
研究意义
在改革开放之后,很多我们国家中小企业发展起来变得更快,并且在一定程度上也推动了中国整体经济的发展状况提高了一定的就业率,并且也做出了很大的贡献,根据实际调查的结果显示,在国内当中,有很多对于小企业的评估方法和执行过程当中也存在一定的差距,并且中国的很多中小企业在进行信用评价的过程当中,也可以对其进行有效的研究来找出其中所存在的风险问题,能够进行正常的回避和找出对应的解决对策来进行实行,能够找出在实际发展过程当中所存在的意义。
信用评级国内外研究现状国内研究现状
在目前来讲,中国的很多中小企业在信用评估研究方面往往是为了能够给中小企业建立更多的评估体系来进行设立的,而在建立的过程当中,也需要大量的资料来进行显示,我们可以利用模糊数学层次分析法以及回归分析等来进行主要判断,而在西南交通大学的一名学生在研究的过程当中,其中就使用了对于公司整体现在评估的指标选取法,以及采用五种类型进行了整体评估,他分别从评级机构的角度来进行看待能够找出在古代小型企业在现代制度过程当中的发展,南大黄英婷和吉林大学付海龙他们从整体层次分析的角度上来进行展开探讨,来找出了对于如今我们国家很多中小企业在信用评价方面的指标,并且进行了集中分析和诊断,能够从四个能力进行入手,进行全面的衡量和整治工作,从而也能够丰富在中小企业发展过程当中的资金结构方面的问题。
国外研究现状
在1900年的时候约翰-摩迪在X创立了穆迪公司,并且也在1909年对X的各个公司第一次发布了各项风险评估政策,并且这也是在整体发展的过程当中的一个重要开端。这是X股票评级行业的开始,也是外国公司信用等级研究的开始。国外对公司的信誉评估进行了比较长的时间,经过一百多年的发展,评估方法和评估模型的发展也比较完善。目前所有的评分模式都建立在 Fisher 1936年提出的一项具有启发意义的调查结果。
它在实际的商业活动中得到了越来越多的运用。KMV模型、 VAR模型、 creditrisk模型,分别以某一公司的资信水平为依据,来估算公司在财务上的拖欠几率;但是,各领域的侧重点虽各有差异,但其适用的方向和时机也不尽相同,但其先进的经营思想却几乎囊括了信贷风险的全流程。模式是指借款人的信贷评级公司按照团队的不同级别进行转移,也就是模式是分散的,并且同样的资信级别的违约行为发生了完全一致的转移矩阵存在的可能性假定真实违约率与历史的统计平均值相等。在实际情况下,上述假设并不能充分适用,从而制约了模型的应用。
中小企业概念及信用评级方法
中小企业的概念
在世界范围内,中小型企业的分类通常以三种准则为基础。一是公司的员工数量、公司的实际资本量、以及某一段时间的销售量。大部分的成员国都会选择两种,而在一些国家,它们会有三种。中小型企业的界定具有地域性、时间性和业务性,而在各国的历史阶段,其界定也不尽相同。
中小企业信用评级方法
从指标提取和评估方法两大角度入手
指标提取
在此基础上,提出了一种基于数据挖掘技术的指数抽取算法。
(1)统计学分析:层次分析、逻辑回归分析、主成分分析、因素分析, AHP是由X运筹学专家 T· L·萨蒂在七十年代早期所提出来的一种简便、灵活、实效性强的多目标决策法.
(2)在原指数系统中,将多余的属性进行了精简,并从其中抽取出了最优的特征。为以后的模式评价缩短培训的次数。前一种评价模式通常与其它的评价方法(如数据挖掘算法)相联系,而后者的抽取标准与随后使用的评价模式(典型地为数据挖掘)有关,也就是按照评价模式的分级效果来决定最佳的子集。
评估方法
目前国内主要研究的评估方法有三种
数理统计模型
其中,最常用的是判别分析法和逻辑回归法,前者主要是用线性判别法。在前一种方法中,阿尔特曼是最有代表性的。在多元线性判别分析的基础上,通过对5项指标的筛选,构建了一个预测公司是否会出现贷款违约的模型,即五因子Z-score模型,接着在此基础上进行改良,将五因子扩展为七因子,建立ZETA模型。专家分析法(Expert analysis)。
20世纪50年代之前,国外的信贷评估方法多为专家的经验与判断,也就是专家分析法,而企业则多依靠个人的基础资料。公司经营的财务资料、经营能力、经济环境、发展前景等,是公司的重要素质、公司的资信评估等,并在公司决定是否进行投资。
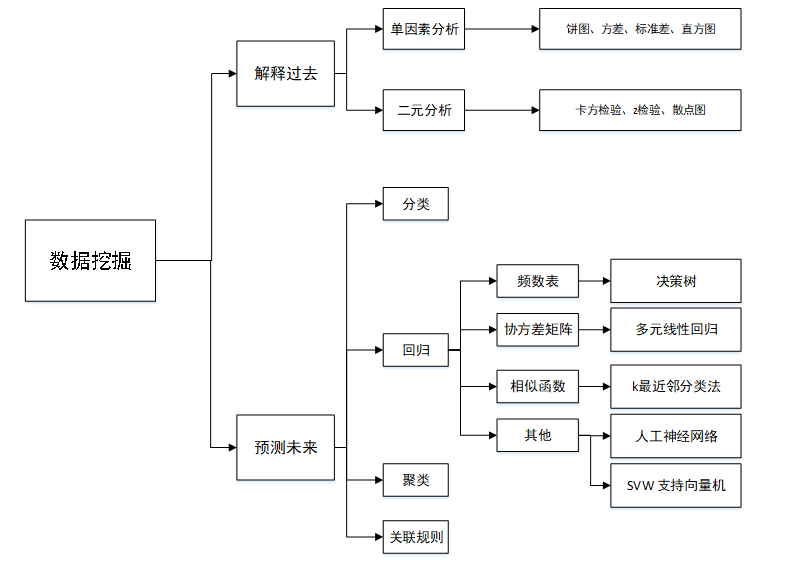
数据挖掘算法。在一定的条件下,中国的中小企业信贷评级将受到多种因素的制约。数据抽取的方式,比如特征选取和属性相关的运算,可以帮助确定重要的或非相关的要素。比如,与付款风险有关的各种要素,如货款率、贷款期限、负债率、偿还和收入比率、信贷历史等等。基于萨亚德博士的研究,将数据挖掘方法分成两大部分,即对以往资料的探究和对将来的模型进行了分析。目前中国中小型企业信贷风险评价的主要方法有:分级、回归分析、SVM、决策树、随机森林、神经网络等。
图2-1 数据挖掘算法

本章小节
着重阐述了中国中小企业信贷评级的基本理论,并给出了相应的计算方法。对中小型企业的基本内涵、技术过程、信贷评估等方面进行了阐述。着重于评价指标的抽取与评价。
数据挖掘理论及中小企业信用指标的挖掘
数据挖掘概述
我们可以从数据的发展过程当中发掘出更多的有用模式来进行使用,比如说我们可以采用知识提取以及信息发现等操作来进行具体的描述。
数据挖掘的具体步骤
在进行数据挖掘的过程当中,我们可以为了满足自身的需求来找出一些数据,选定特殊的模型来进行整体的探讨,我们也可以通过预测和分析的手段来找出模型发展的过程当中稳定性所在。
首先第一点就是能够挖掘出更加适合自己所使用的各项信息,能够构建一个更加具有指导意义的数据采集系统来进行发展,并且对其中的主要模式进行确定,另外,我们也可以采取其他模式来进行关联的方式,这样也可以满足再进行输入对应的变量式,得到具体的步骤。
2、选择适当的资料
在财务部门和商业体系中,需要寻找资料。商业系统资料是一种特殊的工作,例如:网站的运作、索赔的处理、电话的结束或帐单的操作。他们的目标是处理交易的速度和准确,而且可以按任意的方式存储。而在某些没有建立起数据仓库的公司中,这些信息常常被埋藏起来,并且要进行大规模的计划和组织。数据挖掘的方法并非总是等待着完全,但被发掘人员应该有能力利用现有资料,并尽早着手工作。
3、认知数据
在使用数据建立模式以前,人们往往忽略了在研究资料上花更多的时间。事实上,数据采集的技术人员看起来很依靠本能,比如,他们可以在一定的范围内预测出一个可能产生的变数。想要通过对未知的信息进行感知,就必须深入到大量的信息中去,这样才能找到大量的问题,并且在一些特殊的环境下,还可以找到一些难以察觉的问题。
4、建立一套模型
该模式集合包括了在建立模型时所需的全部资料。在模型集合内,使用了部分的资料进行了分析,在某些技术上,利用模型集合的部分资料检验了模型的稳定性。还可以使用该模式来评价该模式的执行情况。
中小企业信用指标体系建立中小企业指标选取的原则
在对分类模型选定之后,好的指标对于后面的结果也至关重要。因此,在选择指标时也要遵守一些原则。选择了中小型企业的财务指标作为研究对象,在建立财务数据指标时,主要遵循以下有关准则:
(1) 全面性。在财务评价中,企业的财务指标要综合反映企业的利润、增长、负债和资金流动情况。这样就可以对各方面进行全面的剖析,尽可能的揭露和评判公司的财政情况。
(2) 重要性。由于金融项目众多,无法将全部的指数纳入到该模式中,反而会导致该模式的有效性与实效性产生负面影响。选择反映其重要程度的主要指数。
(3) 灵敏性。选取的指数对企业的变动很敏感。一旦有任何的改变,都会在第一时间反应过来。
(4) 科学性。公司在对于财政方面的评价过程当中,要根据公司发展的实际情况来进行评判,并且也要利用对应的指标进行整体的分析工作。
中小企业信用指标数据源选取
以 wind Find和 choice Find作为主要的研究对象,我们一共搜集了569个有关于中小企业的各项资料,并且对这些资料进行集中保存和选取工作。
图3-1 部分企业数据
CART分类算法CART分类算法原理
CART是产生一个由 X (不同的特性状态)输出 Y的决策树(这个采样的结果)。
图3-2 CART原理图
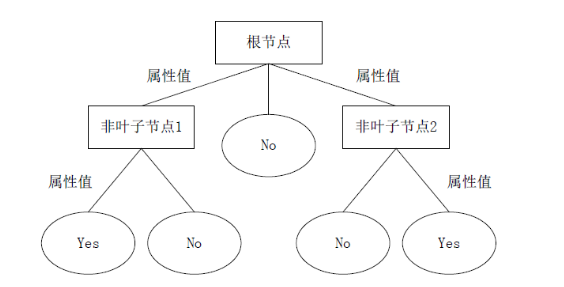
在这棵树中,每一个没有叶子的结点都是一个属性的数值。这个分枝表示了不同的试验成果。树木中的每一个叶子结点都是一种类别。它的顶端是一个根结点。在决策过程中,从根部节点出发,通过对其内部的结点进行检测,并对其进行比较。在此基础上,根据该实例的特征值,进行相应的分枝,最终得出决策树的结果。该流程在一个新的结点上反复进行。
CART方法的基尼不纯净是指一个被随机选取的样品在一个子集上被错误分割的概率。
基尼不纯= signal_(i=1)^ K,样品 i被选择的几率 x被错误分解的机率[10]:
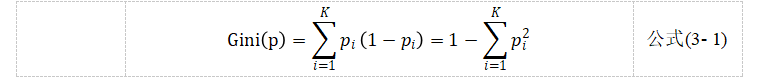
选取最小的 Gini属性作为其分类基础。在训练过程中,尽量获得大量的生成分支,这对于训练集合的分类是有效的,但是在检验集合中存在着较大的错误。为了避免过度拟合和增强决策树的普适性,对某些分支进行了修剪。
修剪:首先把样本分成两组:一组是训练组,另一组是检验组。。
1)预剪枝
预修剪要在分割之前和之后,对检验集合的准确率进行估算,若准确率增加就进行分割。
2)后剪枝
后修剪首先在训练集合中产生一颗完整的决策树,然后在修剪前后依次检验集合的准确性。
Matlab对中小企业数据进行分类挖掘提取指标
Matlab2018b是利用数据挖掘技术的一种实现方法,它不仅能用于信号的分析,,收集资料、研究资料、建立模型、对研究成果进行解析。
首先将一个资料档案输入Matlab2018b,然后将该资料档输入到 matlab工作区(目前记忆体中的一个变量),然后将其作为列矢量, cd可以看到目前的目录。如图3-3
图3-3 导入数据
进行有效的探索和鉴定,对应的模型,并且使用对应的数据挖掘算法来进行主要计算,呈现集中所存在的各项专业知识。
运行结果:
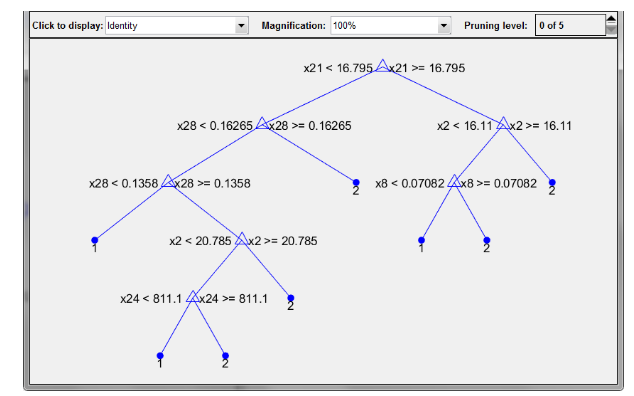
图3-4 分类树截图

图3-5 部分运行截图
在所有的根结点上,对评估公司的信誉进行了统计,得出了以下几个关键的指数,如表3-1:
表3-1
| 重要性代号 | X1 | X2 | X6 | X11 | X14 | X15 | X21 | X22 | X24 | X28 |
| 指标 | 资产负债率C1 | 利息支付倍数C2 | 流动比率C3 | 现金流与流动负债率C4 | 应收款账周转率C5 | 存货周转率C6 | 现金流与流动负债比率C7 | 主营业务增长率C8 | 净利润增长率C9 | 净资产增长率C10 |
本章小节
该章主要阐述了数据挖掘的具体实施流程以及如何选择中小型企业的指数,接着给出了基于Matlab2018b的数据挖掘方法,并给出了10项主要的信贷评价标准。
中小企业信用模型评估
层次分析法概述层次分析法简介
AHP是X匹兹堡大学萨泰教授于1970年代所提的一种系统化的分析方法。AHP是一种能够把定性和定量分析有机地联系起来的分析手段,是分析多目标、多准则的一种有效手段。运用层次分析法求解问题,其基本思想是:将待处理的问题按其特点和所要实现的目的进行序列划分。将问题分为若干要素,根据要素的作用和从属性进行层次聚类,从而构成层次分明的层次结构模式。在此基础上,人们根据对客观事实的评判,量化地描述了各个层次因素之间的关系,并根据人们对于客观事实的评价做出量化的表达。再生资源。
层次分析法的建模流程
人类在对社会、经济、科学等方面进行系统性的研究时,所面对的问题往往是由许多相互联系、制约的要素组成的、且缺乏量化的资料。AHP是一种简单实用的求解此类问题的新的模型。AHP方法的模型过程见图4-1:
图4-1 层次分析法流程图
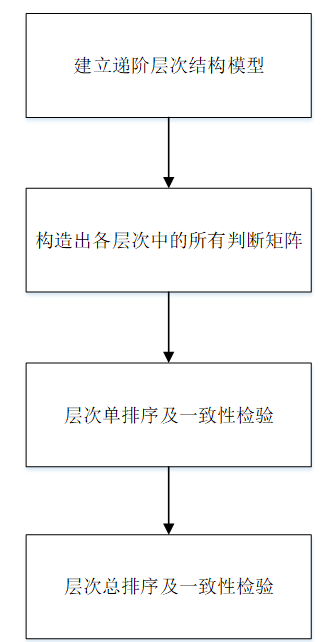
把一个复杂的问题分成几个要素。各要素的性质和相互间的联系,构成了几个层级。前一层的要素是指导方针,它对下一层相关的要素具有主导地位。这几个级别可以分成三个类别:
最高层:这个层级上一共包括一个元素,并且是通过以往预订的结果来进行分析的。
中层:我们可以通过对这个层级进行有效的转换,来将其进行分类。
最低层:这个层次包括各种措施、决策等,以达到目的,所以又叫措施层或方案层。
分层的层数与问题的复杂度及所需分析的细节程度相关,而常规的层数则没有限定。每一层次的成分一般不会多于九个。这是因为,当有太多的优势因素时,很难对它们进行比较。
(2)层次结构体现了各个因素的相互影响,决定一个因素中各个因素所构成的比例时,最大的难点就是这个比例始终很难被定量。此外,若有多种因素,则各个因素会对其产生的影响有直接的影响,而不能全面地加以考量。在这种情形下,决策者们其实是在思考是否有必要时提出的不一致的资料,而提出的资料则意味着冲突。要想弄清楚这个问题,可以这样设想:把一颗一公斤重的石头打碎,分成 n个小片,你就可以把他们的体重,用m_1,m_2,…m_n,用m_1,m_2,…m_n,来估算 n个小方的体重所占的比重(不确定每一种石头的质量),所以很难得出准确的比率,并且由于对这些石头的不同,会产生相互冲突的结果。X的运算学家 Saaty等采用对系数的双对比方法,一次选取2个因子x_i和x_j,其中x_i和x_j是用a_ij来代表x_i和x_j,它们对 Z的作用程度的比率,将所有的对比结果用 A=(a_ij)_(n+ n)来表达,将 A作为Z-X的成对对比判定矩阵(以下简称判定矩阵)【11】。很明显,如果x_i对 Z的作用的比率是a_ij,那么x_j和x_i对 Z的作用的比率应该是:![]()
![]()
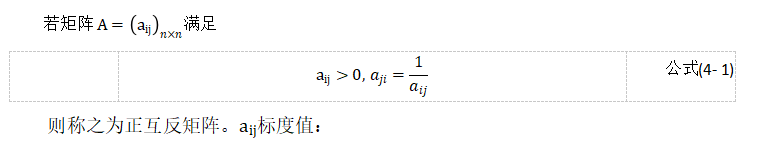
表4-1 判断矩阵标度值
| 标度 | 含义 |
| 1 | 表示两个因素相比,重要性相同 |
| 3 | 表示两个因素相比,前者比后者重要 |
| 5 | 表示两个因素相比,前者比后者明显重要 |
| 7 | 表示两个因素相比,前者比后者强烈重要 |
| 9 | 表示两个因素相比,前者比后者极端重要 |
| 2,4,6,8 | 表示上述相邻判断的中间值 |
| 倒数 | 若因素i与因素j的重要性之比为,那么因素j与因素i重要性之比 |
从心理学的角度来看,等级过高会超出人的判断力,给人带来更大的困难,也给人以错误的信息。Saaty等还对不同尺度下的人的判断进行了对比,并得出了1-9尺度的结论。
(3)层次单排序及一致性检验
将判定矩阵 A与最大本征值λ_ max的本征矢量 W相一致,并将其规格化后,就是同一阶各要素在前一阶中的相关因子的权重,此过程称之为层级单排序。
在此提出的构建、对比评判矩阵方法,虽然可以降低其他因素的影响,更能更好地体现各要素的不同效应。但在对所有的对比分析中,不可避免地存在着一些不相容之处。若对比的结论与前面和后面的情况完全相符,那么 A的要素也应该符合:

(4)层次总排序及一致性检验
给出了一套在其上层的一个单元的加权矢量。最后,我们要确定每个单元,尤其是在底层,各个不同的方案在不同的层次上的优先级,这样才能进行优化。在单一指标下,综合了综合的排序权重。假设上一级(A级)由A_1、A_2、…、A_M组成,其层级的总排序权重为a_1、a_2、…、a_m。然后,将后面的下一层(B层)包括 n个因子B_1、B_2、…、B_N,其中,A_J的层级单排序权重为b_1j,…,b_nj (b_ij=0)。本文对 B级各个因子在总体指标上的权值进行了求解,也就是确定了 B级各个因子的等级总体排序的权重b_1、b_2、…、b_n,即
层次分析法进行评估构建层次结构图
图4-2 层次结构图
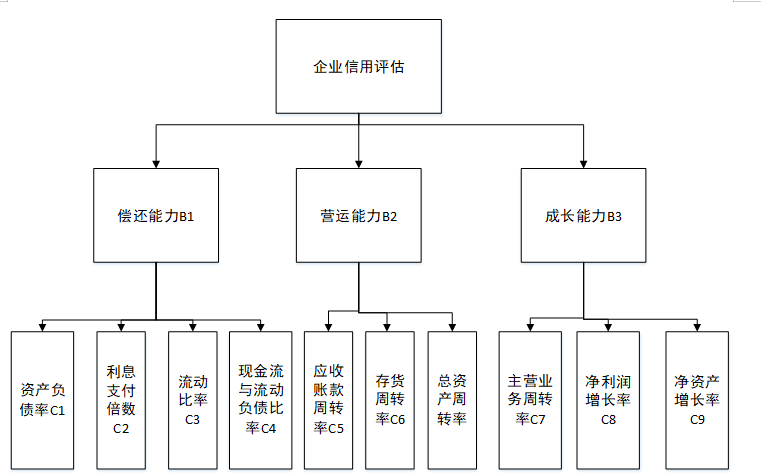
构建第二层,与第一层相对的判断矩阵及权重
构建过程当中,其中主要使用了偿债能力及营运能力等不同的评价模型来进行确定,检验整体的相容性是否存在一定问题。
表4-2 A-B层判断矩阵
| A | 偿还能力B1 | 营运能力B2 | 成长能力B3 |
| 偿还能力B1 | 1 | 2 | 4 |
| 营运能力B2 | 1/2 | 1 | 3 |
| 成长能力B3 | 1/4 | 1/3 | 1 |
利用特征根法的MATLAB程序如下:
| clear;
A=[1 2 4;1/2 1 3;1/4 1/3 1]; RI=[0 0 0.52 0.89 1.12 1.26 1.36 1.41 1.46 1.49 1.52 1.54 1.56 1.58 1.59]; [m,n] =size(A); [V,D] =eig(A) % B= max (max(D)) % [r,s] =find(D==B); % C=V(:,s); % Q=zeros(m,1); for i=1: m Q(i,1) =C(i,1)/sum(C(:,1));% end Q %所求的权重 CI=(B-m)/(m-1) % CR=CI/RI(1,n) %,CR<0.1符合 |
运行结果如下:
图4-3 运行截图1

特征值=3.0183,CR=0.0176<0.1,通过一致性检验。目标层对第二层B的权重为
![]()
![]()
构造第三层相对于第二层各个指标的判断矩阵及权重
我们可以将其分类为以下四个指标来进行运行。
表4-3 B1-C层判断矩阵
| B1 | C1 | C2 | C3 | C4 |
| C1 | 1 | 1 | 2 | 3 |
| C2 | 1 | 1 | 2 | 3 |
| C3 | 1/2 | 1/2 | 1 | 1 |
| C4 | 1/3 | 1/3 | 1 | 1 |
利用特征根法Matlab程序如下:
| clear;
A=[1 1 2 3 1 1 2 3 1/2 1/2 1 1 1/3 1/3 1 1]; RI=[0 0 0.52 0.89 1.12 1.26 1.36 1.41 1.46 1.49 1.52 1.54 1.56 1.58 1.59]; [m,n] =size(A); [V,D] =eig(A) %显示特征值D和特征向量V的矩阵形式 B= max (max(D)) %最大特征值 [r,s] =find(D==B); %最大特征值所在位置 C=V(:,s); %对应特征向量 Q=zeros(m,1); for i=1: m Q(i,1) =C(i,1)/sum(C(:,1));%特征向量标准化 end Q %所求的权重 CI=(B-m)/(m-1) %计算一致性检验指标 CR=CI/RI(1,n) %计算一致性比率指标,CR<0.1符合 |
运行结果:
图4-4 运行截图2

![]()
![]() 通过一致性测试,准则层对第三层子准则层C1的权重,C2的权重,C3的权重,C4的权重为:
通过一致性测试,准则层对第三层子准则层C1的权重,C2的权重,C3的权重,C4的权重为:

准则层能力B2对C5、C6、C7三项指标的判定矩阵如下表4-4
表4-4 B2-C层判断矩阵
| B2 | C5 | C6 | C7 |
| C5 | 1 | 1/2 | 1/4 |
| C6 | 2 | 1 | 1/3 |
| C7 | 4 | 3 | 1 |
利用特征根法的程序如下:
| clear;
A=[1 1/2 1/4 1 1 1/2 4 3 1]; RI=[0 0 0.52 0.89 1.12 1.26 1.36 1.41 1.46 1.49 1.52 1.54 1.56 1.58 1.59]; [m,n] =size(A); [V,D] =eig(A) % B= max (max(D)) % [r,s] =find(D==B); % C=V(:,s); % Q=zeros(m,1); for i=1: m Q(i,1) =C(i,1)/sum(C(:,1));% end Q % CI=(B-m)/(m-1) % CR=CI/RI(1,n) %,CR<0.1符合 |
运行结果为:
图4-5 运行截图3

![]()
![]() 通过一致性检验,准则层对第三层子准则层C4,C5,C6
通过一致性检验,准则层对第三层子准则层C4,C5,C6
![]()
![]()
标准层运营能力B3对C8、C9、C10三项指标的判定矩阵如下表4-5
表4-5 B3-C层判断矩阵
| B3 | C8 | C9 | C10 |
| C8 | 1 | 1 | 1/4 |
| C9 | 2 | 1/4 | 1/2 |
| C10 | 3 | 1/2 | 1 |
将判别矩阵 A的数值替换为:λ_ max=2.7393, CR=-0.2507 《0.1,标准层B_3对第3级标准层C7、C8、C9进行了一致性检验
![]()
![]()
中小企业信用评级实例
按照普尔的等级划分,每个级别的分数都在0.1到10之间。在打分结束之后,对各个指标进行加权,也就是分数与权重之积,最终得出各个指标的加权分数之和。最后的评分还参考了普尔公司的评估,将其划分为10个等级,具体评估表格(12)见下表4-6。
表4-6 评级表
| 总分 | 信用等级 |
| 0.9-1.0 | AAA |
| 0.8-0.9 | AA |
| 0.7-0.8 | A |
| 0.6-0.7 | BBB |
| 0.5-0.6 | BB |
| 0.4-0.5 | B |
| 0.3-0.4 | CCC |
| 0.2-0.3 | CC |
| 0.1-0.2 | C |
| 小于0.1 | D |
下面是一家中等规模的电力公司 A的经营状况:创建于一九九九年,拥有一亿元的注册资金,是一人公司。公司主营输配电项目建设。经过国家建设部批准,具备基础工程专业承包1级专业承包资格,同时具备国家建设厅核准的工程建设资格。下面是一些特定的数字,包括偿还、营运、成长:
表4-7 偿还能力
| 项目 | 2017 | 2018 | 2019 |
| 资产负债率 | 22.3% | 23.5% | 22.5% |
| 利息支付倍数 | 2.3 | 1.4 | 1.5 |
| 流动比率 | 3.5 | 4.1 | 3.7 |
| 现金流与流动负债比率 | 12.6% | 16.3% | 14.2% |
表4-8 营运能力
| 项目 | 2017 | 2018 | 2019 |
| 应收款账周转率 | 12.3 | 10.2 | 11.8 |
| 存货周转率 | 7.2 | 9.2 | 8.9 |
| 总资产周转率 | 1.3 | 1.5 | 1.2 |
表4-9 成长能力
| 项目 | 2017 | 2018 | 2019 |
| 主营业务增长率 | 11.3% | 10.2% | 12.5% |
| 净利润增长率 | 1.3% | 1.7% | 2.4% |
| 净资产增长率 | 1.4% | 2.3% | 1.2% |
在此基础上,采用标准普尔公司的资信等级分析方法,得出了公司的资信评分为4-10:
表4-10 信用得分表
| 指标 | 权重 | 分值(对应表4-1) | 加权后分值 |
| 资产负债率 | 0.3540 | 0.9 | 0.3186 |
| 利息支付倍数 | 0.3540 | 0.8 | 0.2832 |
| 流动比率 | 0.1607 | 0.8 | 0.1286 |
| 现金流与流动负债比率 | 0.1313 | 0.4 | 0.0525 |
| 总计 | 0.7829 | ||
| 指标 | 权重 | 分值 | 加权后分值 |
| 应收款账周转率 | 0.5584 | 0.7 | 0.3909 |
| 存货周转率 | 0.3196 | 0.8 | 0.2557 |
| 总资产周转率 | 0.1220 | 0.5 | 0.061 |
| 总计 | 0.7076 | ||
| 指标 | 权重 | 分值 | 加权后分值 |
| 主营业务增长率 | 0.2328 | 0.8 | 0.1862 |
| 净利润增长率 | 0.2841 | 0.7 | 0.1989 |
| 净资产增长率 | 0.4832 | 0.7 | 0.3382 |
| 总计 | 0.7233 | ||
加权后分数分别为0.7829大于0.7,0.7076大于0.7,0.7233 大于0.7,所以表4-1 A企业的信用评级为A。
本章小节
本文首先阐述了 AHP的基本过程,然后采用普尔公司的指数对一家中小型电力公司进行了加权计算。并对其研究成果进行了分析。
参考文献
[1]袁莉,李宏男,姜韶华. 企业信用评价方法概述[J]. 建筑经济;2007年S2期
[2]李炳南. 基于大数据的中小企业信用评估和风险控制的问题研究[D].天津大学,2018.
[3]邱梅,王哲元.基于数据挖掘的信用评估研究[J].计算机技术与发展,2017,27(08):47-51.
[4]中小企业信用指标体系构建及评估模型的最优化[D]. 奚梦缘.南京大学 . 2018
[5]晨曦. 基于数据挖掘的企业信用评价研究[D].南京大学,2011.
[6]琳,季凌.基于数据挖掘的中小企业客户信用评级模型的设计与实现[J].海峡科技与产业,2019(01):176-178.
[7]华.基于数据挖掘技术的企业信用评估研究[J].科学学与科学技术管理,2007(07):192-194.
[8]晓衡,曾德天.基于AHP和混合Apriori-Genetic算法的交通事故成因分析模型[J].计算机应用研究,2019,36(06):1633-1637+1678.
[9]金红,陈进.我国企业信用评估体系的发展[J].国际商务.对外经济贸易大学学报,2004(04):59-62.
致谢
经过这一段时间的论文设计,终于完成了论文。在这里由衷的感谢指导老师的指导,也感谢同学热情的帮助。是你们在我有困难的时候帮助我解决了困难,使得我成功的完成了论文,感谢。

1、如文档侵犯商业秘密、侵犯著作权、侵犯人身权等,请点击“文章版权申述”(推荐),也可以打举报电话:18735597641(电话支持时间:9:00-18:30)。
2、网站文档一经付费(服务费),不意味着购买了该文档的版权,仅供个人/单位学习、研究之用,不得用于商业用途,未经授权,严禁复制、发行、汇编、翻译或者网络传播等,侵权必究。
3、本站所有内容均由合作方或网友投稿,本站不对文档的完整性、权威性及其观点立场正确性做任何保证或承诺!文档内容仅供研究参考,付费前请自行鉴别。如您付费,意味着您自己接受本站规则且自行承担风险,本站不退款、不进行额外附加服务。
原创文章,作者:打字小能手,如若转载,请注明出处:https://www.447766.cn/chachong/66951.html,