摘 要
糖尿病肾病(Diabetic nephropathy, DN)是糖尿病主要的并发症之一,初期症状不明显,不过在后期将会出现肾脏功能的并发症,致死率较高。我国糖尿病病例存在不断上涨的趋势,糖尿病肾病对于我国国民健康状况的影响已经越来越严重。对于我国病理医生缺口不断扩大的情况,能够针对糖尿病肾病患者病理切片展开高效精准的诊断的辅助手段亟需开发。而肾小球基底膜增厚作为糖尿病肾病的典型病理性特征之一,依靠肾脏病理学理论依据作为辅助诊断手段的切入点。本文针对糖尿病肾病的这一特点展开研究工作。
本文通过与山西省医科大学第二医院合作获取近十年的包括糖尿病肾病患者在内的肾活检数字病理切片,使用Faster-RCNN目标检测网络在数字切片中的肾小球区域进行识别,在此基础上通过目标测试框分割原图像中肾小球,以此作为构建肾小球数据模型的基础。事实上,在以医学病理数据集为代表的重要目标检测场景中,常常仅有图片级标签,而没有对象级标签,而多示例学习正是为了解决由于数据标注成本太高,很难获得全部真值标签这样强监督信息的情况而提出的,故本文采用基于注意力机制的多示例学习(Attention-based Multiple Instance Learning, AMIL)网络模型,构建具有分类标签的多示例包,在糖尿病肾病中基底膜增厚样本数据集上训练多示例分类器,后应用该多示例分类器解决数字病理切片中肾小球基底膜增厚情况未知的标签预测问题,以辅助病理医生进行糖尿病肾病的临床诊断,对糖尿病肾病的诊断和分期具有借鉴意义。
关键词:糖尿病肾病肾小球基于注意力机制的多示例学习基底膜增厚
第一章 绪论
本章主要介绍了糖尿病肾病、肾小球和本文相关技术的研究背景及现状。
1.1 研究背景
1.1.1 糖尿病肾病
糖尿病肾病指的是受到糖尿病的影响,人体的微血管出现病变,比较直观的病变是肾小球出现硬化,学名又称糖尿病肾小球硬化症。从相关数据统计显示,预测在2030年,全球范围内的糖尿病患者将突破3.6亿,其中由于糖尿病引发的肾病患者将超过1亿。糖尿病肾病病理复杂程度较高,大部分情况下表现为慢性病,严重者甚至导致肾衰竭。基于此,在临床诊断中,应当持续强化糖尿病肾病的诊断与预防,确保治疗方案的科学可行性,最大限度降低糖尿病肾病的发生概率,有效减轻患者的病痛,提升糖尿病患者的生活质量。目前关于糖尿病肾病诊断方法研究呈现多元化发展,比较常见的有血清学检查、微量白蛋白、超声检查等。在传统的临床诊断经验中,通常将蛋白尿作为评价糖尿病肾病的重要标志,此外,大部分临床诊断主要根据尿微量白蛋白作为判断糖尿病肾病的关键依据。通常情况下,尿微量白蛋白一旦出现,这预示着糖尿病肾病的出现,不过也有部分二型糖尿病患者出现肾病的情况下,依然无法排除非糖尿病肾病引发的病症。
肾穿刺活检作为二型糖尿病并发症的重要衡量依据,其能够对糖尿病引发的肾脏损伤情况进行科学准确的反映和衡量,但与临床实际情况存在不小差距。糖尿病肾病中具有典型代表性的病症主要是人体内部基膜不断加厚、肾小球基质持续增加等,从实际情况分析,早期肾小球结构在改变过程中并没有呈现显著的特异性,由此也造成临床诊断过程中难以根据该特征作为诊断的依据。
1.1.2研究基底膜增厚的意义
DN导致的肾小球病理改变通常涵盖:肾小球体积持续扩大,肾小球基底膜不断加厚等。
在所有糖尿病的并发症中,DN是其中比较常见的并发症,也是造成慢性肾病居于主导地位的病因。
通常情况下,从首次确诊到临床沉默期,也可以理解为糖尿病患者的白蛋白尿保持正常范围或出现GFR较高的现象,在此过程中虽然没有表现出显著的临床病症,但其实此阶段已经出现肾脏单位的变化,主要表现为系膜扩张、肾小球硬化、GBM变厚等。如果在此阶段临床诊断中发现一定比例的微量白蛋白,一般说明患者已经出现结构性损伤,紧随其后的是GFR将会呈现快速下降趋势,并发展至终末期阶段。从全局角度分析,当DN临床症状比较明显在进行治疗无法对病情造成缓解作用,往往只能拉长步入ESRD的时间。由于肾功能下降和蛋白尿出现下降现象并非反映DN早期病症的标志,笔者在研究中将重点放在早期确诊时就存在的GBM结构病变方面。
GBM作为一种与凝胶状相似的网状结构,通常附着于肾小球上皮细胞和皮肉细胞的区间,同时受到两种细胞的分泌作用形成电子致密层。
DN患者GBM厚度与肾脏病理改变的严重程度密切相关。
1.2研究现状
1.2.1 多示例学习
通常计算机系统中所谓的“经验”主要通过历史数据的形式存在,而合理运用经验就必须涉及针对数据展开研究和分析,深度学习是目前广泛应用的算法,最早诞生于人工智能的开发领域,其主要以相对确定数据规律的形式发展起来,进而得到研究和分析学习的综合能力。
基于此,机器学习依然发展为计算机数据分析领域的重要驱动力。在数据收集和储存能力不断提升的时代背景下,对计算机数据的研究和分析成为大势所趋,受到多个领域的广泛关注,由此反映机器学习的重要性不断加强。机器学习不但成为人工智能核心技术发展的标志,如今也成为计算机领域讨论度最高的课题。
上世纪90年代末,T. G. Dietterich等[6]人围绕药物活性预测问题展开分析和研究过程中,第一次提出关于多示学习这一概念。这一概念主要指的是对多个标签化的数据进行训练,其中也涵盖多个无法显示标签的数据内容。如果其中一个数据包存在一个正示例,可将其标记为正包,如果在数据包中每一项示例都属于负示例,可将其标记为负包。多示例学习可以理解为训练示例包的学习过程,从而确保其能够客观准确预测其他类型的标签。
1.2.1.1 轴平行矩形(APR)算法
T. G. Dietterich等[6]人在研究中认为,轴平行矩形学习算法可划分为三种,分别为Iterated-discrim APR、GFS elim-count APR、GFS elim-kde APR算法。此类算法的共性是利用更新迭代和贪婪进行搜索,通过示例向量的属性值展开有序融合的操作,确保其在属性空间中能够找到与之相吻合的轴平行矩形,最大限度使其涵盖更多正示例,并尽可能降低负示例的出现。
1.2.1.2 基于概率统计类的MIL算法
此种类型的算法底层逻辑是全面深挖示例和包之间的关联性,并根据最终挖掘的结果,对多示例学习问题提出解决方案,目前应用较为广泛的算法有DD[7]、EM-DD[8]等。
(1)多样性密度算法。多样性密度算法诞生于上世纪90年代末,由Maron等[7]人在研究中提出,其应用范围已经拓展至股票预测、人脸识别、分子活性预测等。其底层逻辑是,围绕示例空间范围内探究出个能够产生最大多样性密度的概念,从而保证其中任意一项正包至少有一个示例与该点距离足够近,相反每一项负包都尽量远离该点。不过如果将该目标概念点视为主要参照物,对任意示例与其的距离进行计算,通常由最近的示例的最小范围作为参考阀值,以此作为新包标准的主要判断方法。
(2)EM-DD算法。围绕DD算法存在的缺陷和弊端,Zhang等[8]在2002年将最大方法思想的概念融入其中,创立了EM-DD算法。通常情况下,其由两个步骤构成,在E步,通过期望函数估算其中不同训练包最大可能示例,并以此为基础代表该训练包。在M步,对最大可能示例展开计算和预测,从中获得新型目标概念点,该算法必须持续到两个相邻的概念出现收敛效应之后才能结束。
1.2.1.3 仍待研究的问题
多示例学习概念从诞生之初便受到国内外大量研究人员的高度重视,并针对MIL展开多维度的分析和研究,目前关于MIL理论研究成果较为显著,不过依然存在不少缺陷和不足:
(1)缺乏能够与任意一种多示例学习兼容的算法。通常情况下,需要将多示例学习问题与特定算法紧密相连,才能展现其学习性能。在多示例学习的不断深入发展进程中,多标签多示例学习问题、寻找正包正示例问题等都需要新的算法与之匹配。
(2)针对多示例学习和多种机器学习方法的关联性展开研究和分析,根据现有的无监督、非监督、半监督学习方法解决当前的问题,是目前对多示例学习算法展开研究的关键措施。在此过程中,通常需要建立包特征,确保包特征关键信息储存的稳定性和可靠性,确保其不过分依赖特定示例,是形成有效转化作用的关键之处。
(3)一方面,在此过程中,降维和选择特征往往对算法造成不同程度的影响,这也是目前学术领域的研究重点。但目前关于这两方面的研究凤毛麟角。另一方面,当在各类图片信息进行检索和分类过程中使用多示例学习,往往耗时较长,且需要较大储存空间,多示例学习串行算法无法满足此种类型的数据处理技术要求。
1.2.2医学影像智能识别技术
智能医学影像识别技术在疾病诊断和治疗方面发挥着极为关键的作用,并呈现出广阔的发展空间。从诊断疾病方面考虑,影像诊断发挥极为关键的作用。从全球临床诊断比例来看,智能影像诊断针对不少疾病的诊断准确率远高于医生的临床诊断,可以预见在未来智能影像诊断系统将会在临床诊断领域发挥更大的作用,不仅能有效控制和节省医院现有人力资源,也能够提升临床诊断的准确率和诊断效率。智能影像诊断质量能够在不同医疗环境和诊断条件下发挥作用,和传统医生诊断不同的是,数学模型能有效实现历史数据的分析效果。可以理解为无论何种等级医院,都能够利用机器学习模型得出相同的诊断结果,而这对我国医疗水平的提升起到重要的推动作用。
智能图像处理的底层逻辑指的是对目标进行识别,并细化目标,最后对目标展开分析,在此过程中,无论何种方式的智能图像,首先必须通过图像识别相应的目标。我国当前的目标识别方法主要以人工标注的方式,随着该技术的发展,如今已经出现了将人工标准CT图集作为机器学习的模型,从而形成准确的器官位置和形状辨识能力,在此基础上对目标内容进行细化,该过程旨在细化和精简算法的流程,也是有效提高分割准确性的关键措施。其能够有效提升图像识别系统对器官识别的准确率,不过针对小器官的识别效果依然不理想。
伴随着深度学习技术的持续发展,智能医学影像识别在多个医学细分领域得到广泛应用,其能够有效提升模型识别的可靠性和精确度。不过,器官识别往往受到背景像素、经验知识运用不充分等因素的影响,需要持续优化和改进。
近年来我国计算机视觉和深度学习技术的呈现日新月异的发展,人工智能技术受到医学领域的广泛关注。作为一种新型的综合性技术,医学影像识别技术主要通过X射线、核磁共振、超声波、核医学等方式发挥识别作用,并广泛应用于影像分割、三维立体模型构建、影像配准等领域,深度学习能够提升病灶检测和病理分类的需求,为医生的临床诊断提供有价值的参考依据。
1.3本文研究内容及结构安排
1.3.1研究内容
我国糖尿病患病率逐年攀升已是不争的事实,与此同时,糖尿病引发的肾病患者比例也在持续上涨。我国当前病理医生缺口不断扩大,真正能够根据病理切片准确高效得出诊断结果的措施和技术依然存在不小的发展空间。肾小球基底膜增厚凸显了糖尿病肾病的典型病理性特征,可以作为一种有病理学依据的辅助诊断手段的切入点。本次研究围绕糖尿病肾病展开深入研究和分析。
本文工作的总体流程如下:
获取肾活检染色后的病理切片并进行数字化。获取患者电子病历,将病理切片数据根据诊断报告中患病类型及病灶状况的描述对样本进行分类。使用Faster-RCNN网络对针对肾小球采取切割处理,从中得到单个肾小球的病理图像,为本次研究提供肾小球数据参考依据。训练多示例学习网络模型AMIL对肾小球基底膜增厚的样本进行学习。最后,利用训练出的AMIL模型在测试集上预测样本标签,并进行模型性能评价。
1.3.2结构安排
本文的结构安排如下:
(1) 第一章,绪论。本章节主要对糖尿病肾病的背景、意义、内容进行简要概述,并对目前学术领域的研究历程和研究现状进行梳理和分析,同时梳理和概述本次研究的主要内容和论文结构。
(2) 第二章,数据集的构建。本章节中,首先对肾小球的组织结构进行简要概述,为进一步认识和了解肾小球提供参考依据,在此基础上利用肾小球数据构建模型,其中涵盖图像格式处理、获取患者病历切片原理数据等,也可以理解为对肾小球的主要区域进行分割。
(3) 第三章,基于多示例学习的肾小球基底膜增厚识别。在该章节中,训练基于注意力机制的多示例学习网络模型,以应用在肾小球基底膜增厚检测当中。对该模型的构建原理和构建背景进行简要概述,并深入阐述肾小球研究模型的内部结构和不同模块的具体原理。最后,给出了本文的实验环境,网络参数以及对于AMIL网络的模型评价。
(4) 第四章,总结与展望。最后章节对本次研究内容进行梳理和总结,得出最终的研究结论,同时对本次研究中存在的缺陷和不足进行总结,并在后续的研究和工作中进行展望。
第二章 数据集的构建
本章节首先围绕肾小球结构进行简要概述,以此加深读者对肾小球的认知和了解。
2.1肾小球结构
如图 2-1所示[3],肾小球通常由包绕于外部肾小囊和毛细血管构成,一般肾小球的直径为150~250。毛细血管球通常由入球小动脉的多条分支构成,通过重复交叉汇聚,最终形成出球小动脉。一般小动脉通过某一侧的肾小球血管极出入,并与肾小囊形成连接状态。
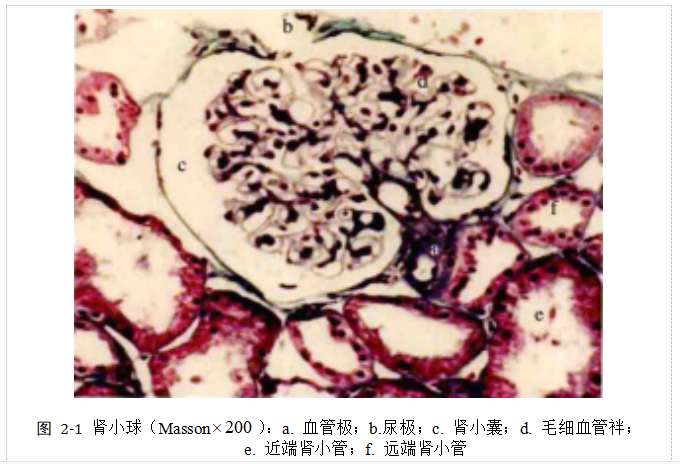

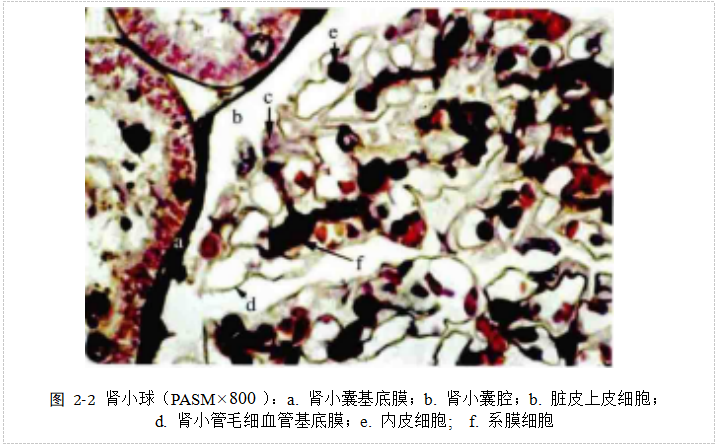
肾小球毛细血管基底膜一般情况下分布于上皮细胞和内皮细胞的间隔处,其呈半透膜状,含有大量糖蛋白,利用PAS以及PASM等方法能够通过光镜清晰查看。
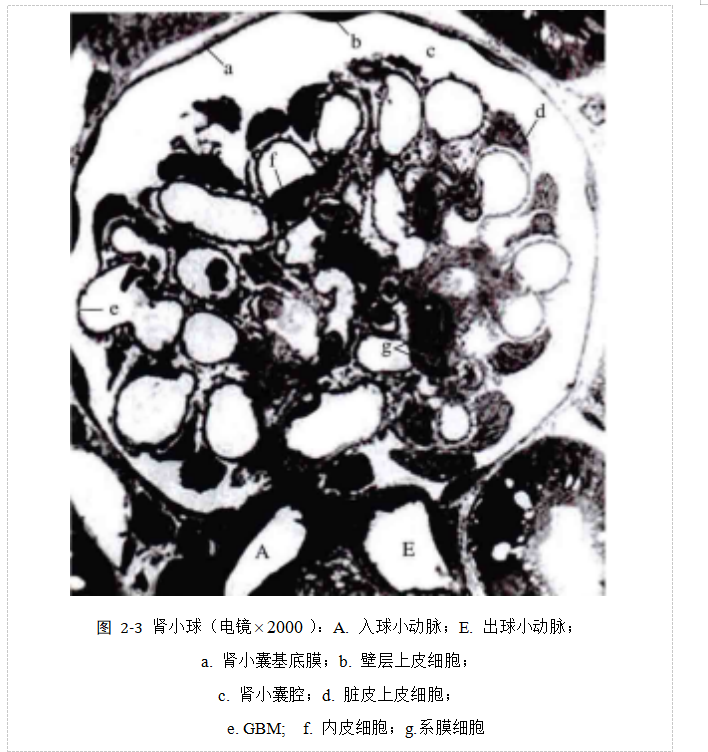
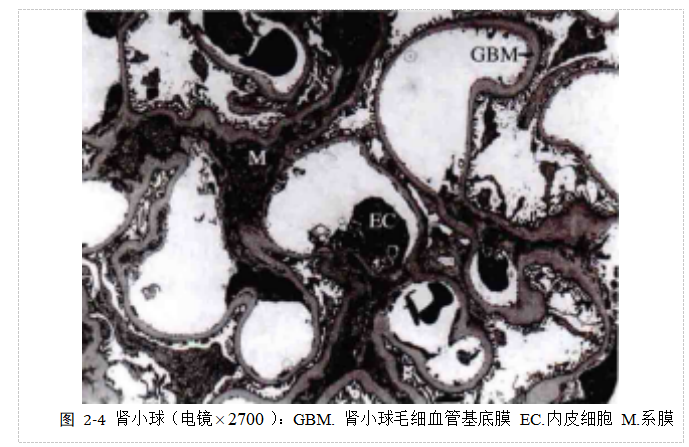
GBM分为三层:内疏松层,厚约80 nm;中间的致密层,厚约120 nm;外疏松层,厚约100 nm。通常情况下,GBM由糖蛋白和IV型胶原构成。
从医学领域而言,可将肾小球毛细血管上皮细胞视为肾小囊中的上皮细胞,在一般情况下,其通常靠近在GBM的外部或周边。通过光镜可观察到上皮细胞核体积较大,具有较为细腻的染色质。通过电镜能够观察其呈现高尔基复合体、溶酶体、微管等,因此业内称其为足细胞。
肾小球系膜(mesangium)由系膜细胞及系膜基质组成,位于肾小球毛细血管之间,通过肾小球血管区域和任意一根毛细血管紧密相连,将毛细血管球悬吊在血管极处。系膜有的可伸入毛细血管腔,起到支撑保护、清除和吞噬的作用。
2.2肾小球图像的获取
本文的实验数据来源为通过与山西省医科大学第二医院合作获取的近十年的包括糖尿病肾病患者在内的肾活检病理切片,后采用数字病理扫描仪的方式处理肾病病理切片。其中涵盖十年时间收集的三千多例肾病患者肾脏活检病理切片,通过多重筛选后最终得到2340张数字切片。任意一个患者都需要采集四种染色肾病图像,在此基础上剔除受污染的图像。这四种染色图像分别为苏木素-伊红(HE)染色;过碘酸-希夫氏染色;过碘酸六胺银染色;马松染色。通常情况下,观察细胞结构和种类需要使用HE染色;通过PAS染色的方式转化糖浆颜色,此时纤维、GBM等大多呈现紫红色,从中能够对系膜基质的数量和位置进行准确判断,如图2-6所示;通过PASM染色的方法将GBM转化为黑色,通常情况下,系膜基质呈黑丝状,一般在观察系膜基质中用到此种方法,如图2-7所示;MASSON染色将肾小球中的细胞核和免疫复合物等特殊蛋白质染成红色,GBM染成浅蓝色,如图2-8所示。
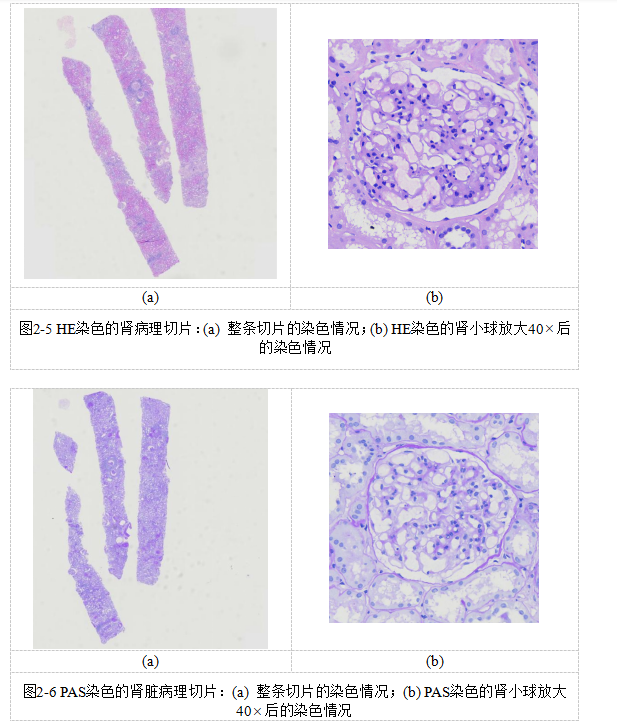
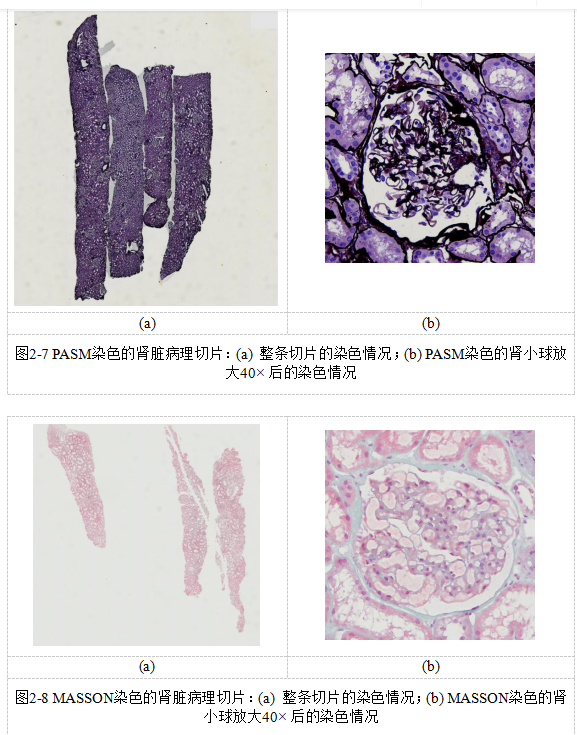
本次研究主要采用麦克奥迪教学切片扫描和相应的系统扫描病理切片,具体步骤为:
(1) 装载切片。待仪器准备就绪后,打开仪器门,从中抽出放置板,使用干布擦拭切片,打开切片夹。必须确保每个放置板有6张切片,插入仪器时要保持平行状态,并全面检查仪器,关闭安全门之后启动扫描。
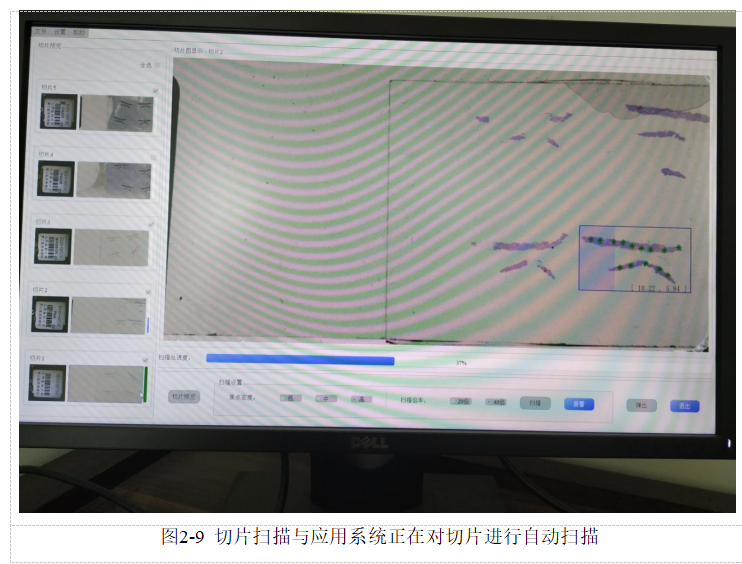
(2) 扫描切片采用“EasyScanner”系统开展扫描操作。首先需要金进行聚焦操作,切片中往往涵盖多条肾穿刺染色界面,必须选取干净且清晰可见的进行扫描。将扫描范围根据实际情况缩小至截面,在此基础上增加扫描焦点,在此过程红扫描宽呈蓝色状态,必须确保肾组织焦点匀称,如图2-10所示。完成上述操作后进行标记工作,选中扫描范围内的所有切片,并设置相应的分辨率,正式启动扫描。在此阶段,标注点呈现不断变绿的状态。
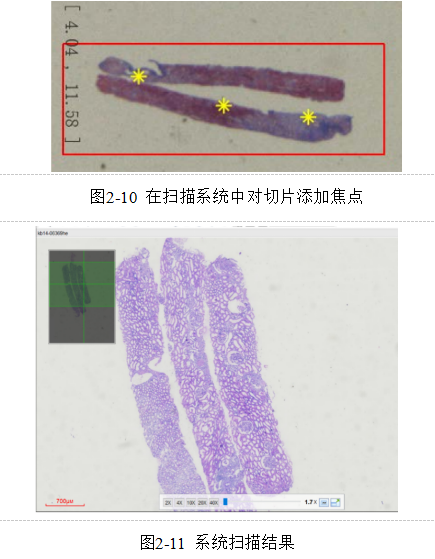
(3) 查看处理扫描结果。当扫描操作结束后,需要检查是否存在没有聚焦的情况,一旦出现这种情况,应当通过扫描软件执行重新选择选项,针对没有聚焦的切片展开扫描操作。
(4)当扫描工作完成后,点击“弹出”按键,待安全门开启后便可取出放置板,同时放入新的待扫描切片
2.3 肾小球数据集的构建
2.3.1数据格式转换
被扫描之后,切片以sszn的格式储存在扫描设备中,此种格式是一种镜像文件,在使用过程中通常需要通过专门的转化软件转换之后才能正常使用。
(1) 使用“SSZN2TIF_Run_QT”软件进行批量处理,导出tif格式文件,并确保所有图片的倍数都是“40x”,无须压缩图像质量,其文件大小在500-1500M之间。它是一种大部分时候应用于细胞图像的研究领域的图像文件格式。通常情况下,此类格式图像不能通过常规的看图软件查看,更不能通过直接输入的方式开展训练,因此必须通过专门的软件转化之后才能进行训练。

(2)当转化操作结束后,需要将图像转化为常规文件格式,同时确保其尺寸符合训练和分割的要求。在此过程中可通过python实现。使用Python的matplotlib包读取png文件,将图像的高度和宽度调整为2000,不足的地方使用黑色边框补齐并将结果保存。
2.3.2肾小球区域切割
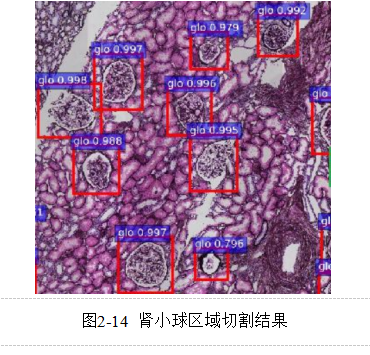
从2.3.1章节中转换之后的肾病理切片图像本身较大的,不能直接使用在训练模式上。因此需要对原图像切割出感兴趣区域(ROI),无须任何操作能够直接得到本次研究所需的肾小球具体位置,基于此,本次研究引入Faster-RCNN算法对肾小球切片进行检测,从而得到肾小球的数据内容。Faster-RCNN作为当今相对较为先进的测算方法,其优势在于能够通过不同尺度对目标展开检测,同时具有较为良好的运行性能,该算法的特征提取网络引入了RPN[21]网络,对目标进行多尺度特征检测,在性能和速度上都有很大提升,Faster-RCNN目标检测网络架构如图2-13所示。

下面介绍肾小球区域切割的流程,具体步骤如下:
(1) 用matplotlib包全部导入图像尺寸,在此基础上进行RGB格式的转换,以作为Faster-RCNN网络的输入。
(2) 使用PyTorch深度学习框架构建Faster-RCNN模型,便于后续图像特征的提取,针对其中的肾小球展开深入分析和检测,通过该模型最终会获得涵盖检测框位置和类别概率的列表。
(3) 并全部过滤调动信度低于0.8的结果,得出检测框的所在位置。
(4) 从检测框位置得出肾小球的具体位置,从而获得符合训练要求格式的图像。查看和读取之后对其中的肾病理切片图像进行全部分割,从而获得肾小球的初级数据集合。
第三章 基于多示例学习的基底膜增厚识别
本章主要介绍如何实现肾小球基底膜增厚的识别。首先对本文使用的基于注意力机制的多示例学习网络[12](Attention-based Deep Multiple Instance Learning, AMIL)和人工作业相比的优势进行简要概述。并对这种模型各个模块的作用和网络结构展开进一步研究和概述,在此基础上简要阐述模型主要的训练方法与结果分析。
3.1多示例学习基本假设
在重要目标检测场景中,仅有图片级标签,而没有对象级标签的情况很常见,这被称为不确切监督问题(inexact supervision),多示例学习正是为了解决由于数据标注过程的成本太高,很多任务很难获得如全部真值标签这样强监督信息的情况[20]而提出的,因而以多示例学习为代表的弱监督学习算法在实际应用场景中具有很强的实用性。
在多示例中包可以理解成多个样本的集合,只有包含有标签,样本不含标签。多示例学习实现首先要学习已经具有分类标签的多示例包,进而构建多示例分类器,最后可以应用该多示例分类器解决未知分类标签的多示例包的标签预测问题。所以构建示例包的标准假设[10]如下所述。由于一个包被标记为正的充要条件是它至少包含一个示例是正的。令![]()
![]() 表示含有
表示含有![]() 个示例,其中满足
个示例,其中满足![]() 的包,包的标号可以表示为:
的包,包的标号可以表示为:

记正包![]()
![]() 其中
其中![]() 分别表示正包中正包目标候选区域和正包的数量。在多示例学习中,如果包中存在至少一个正例,则认为该包为正包;否则,只有包中所有示例均为负样本时这个包才认为是负的。本文遵循文献[12]中的前提假设,认为MIL模型中的示例是具有排列不变性(permutation-invariant)的,即特征之间没有空间位置关系,则认为包标签是
分别表示正包中正包目标候选区域和正包的数量。在多示例学习中,如果包中存在至少一个正例,则认为该包为正包;否则,只有包中所有示例均为负样本时这个包才认为是负的。本文遵循文献[12]中的前提假设,认为MIL模型中的示例是具有排列不变性(permutation-invariant)的,即特征之间没有空间位置关系,则认为包标签是![]() 的二项分布。
的二项分布。
3.2 AMIL网络结构
3.2.1 Multiple Instance Learning原理方法
基于包概率
排列不变性以及包示例相互独立的假设,MIL问题可以转用对称函数基本定理的一个特定形式来考虑,并由以下定理给出:

上述两个定理的区别在于,前者提供了普遍使用的分解形式,而后者给出了任意近似的方法,但它们都总结形成了三步式对示例分包的一般方法:

将单个示例映射为低维embedding形式,利用MIL池化获得bag representation,bag representation最终经过一个闭包分类器进行分类以获取。
3.2.2 基于神经网络的MIL方法
在经典MIL问题中,通常假设示例特征是无需进一步处理的。然而,对于图像或文本任务,进一步的特征提取是必须的。因此,有必要考虑通过添加神经网络![]()
![]() 作为转换,其作用在于将示例
作为转换,其作用在于将示例![]() 转换为低维embedding,即
转换为低维embedding,即

目前,该方法唯一的限制是MIL池化函数必须可微。
3.2.3MIL池化算子
经典MIL问题要求MIL池化算子
具有排列不变的特性,以保证分包概率得分函数为对称函数。而本文采取的最大值算子和均值算子,均满足这一特性,算子具体表示见式(3.6)、(3.7):
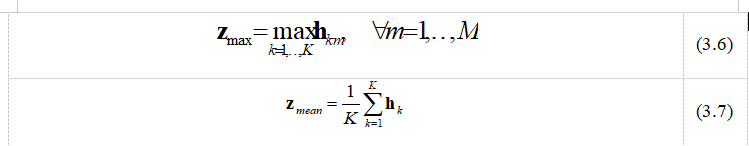
除了最大值算子和均值算子之外,很多其它算子也满足这样的性质,如凸最大值算子[15]、噪声或池化算[16]、噪声和池化算子[17]等。因此,这些算子都可在深度神经网络的MIL池化层中使用。
3.2.4基于注意力机制的MIL池化模块
上文提到的MIL池化算子有一个共同的弊端,它们都是预定义且不可训练的,比如最大值算子在示例级别方法中表现优异,但在embedding级别方法中并不适用;均值算子并不适合在计算示例得分模型的MIL池化层中使用,但用在计算bag presentation中可以获得比较良好的效果。因此,我们期望能引入某种机制,以开发出更具灵活性、自适应性、可解释性、在更多场景下普遍适用的模型,由此提出了基于注意力机制的MIL池化模块(Attention-based MIL pooling)。
下面介绍基于注意力机制的MIL池化模块。
在3.2.2节中已说明要由神经网络确定参数。现以此参数作为权重给示例(或低维embedding)加权,当满足权重和为1时,权重将与包中示例数量无关。所得到加权平均向量满足了定理1的条件,其中取权重以及所得embedding作为函数![]()
![]() 的一部分。
的一部分。
记示例数量为![]()
![]() 的示例包转换得到的embedding为
的示例包转换得到的embedding为![]() 则提出MIL池化算子如下:
则提出MIL池化算子如下:

在经典的注意力机制模型中,示例往往是有序列依赖[18][19]的。在包内的示例样本相互独立的假设下,注意力机制的引入并不能得到契合问题的模型。
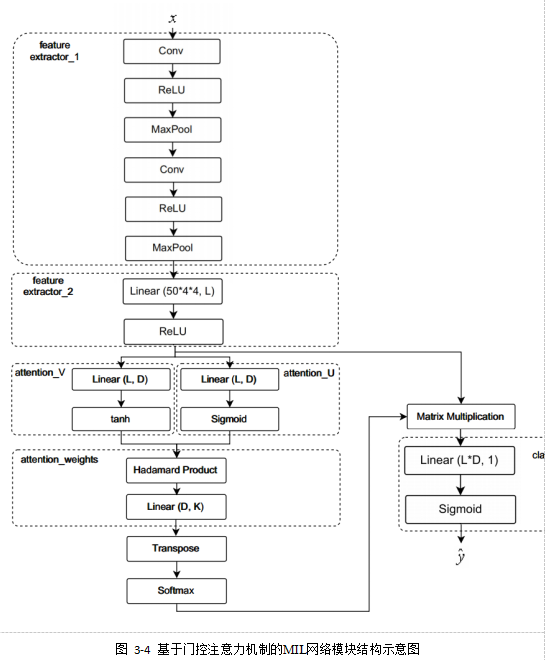
3.2.5门控注意力机制模块
考察式子发现双曲正切函数![]()
![]() 对元素的非线性对一些复杂关系的学习来说是并不充分的。由于
对元素的非线性对一些复杂关系的学习来说是并不充分的。由于![]() 在
在![]() 上是近似线性的,可能会限制对于模型学习到的示例之间关系的最终表达。由此,提出引入门控注意力机制(Gated attention mechanism),结合
上是近似线性的,可能会限制对于模型学习到的示例之间关系的最终表达。由此,提出引入门控注意力机制(Gated attention mechanism),结合![]() 的非线性特性,新的表达式如式(3.10)所示:
的非线性特性,新的表达式如式(3.10)所示:

图3-5所示为基于门控注意力机制的MIL网络模块结构示意图,其中L,D,K为图片尺寸参数。
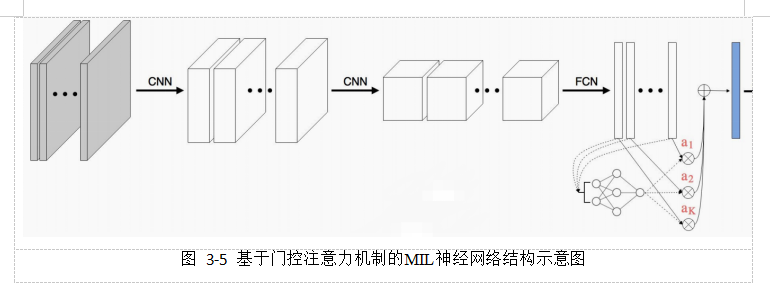
改进后基于门控注意力机制的MIL池化模块允许为包中不同示例分配不同的权重,故最终的bag representation可以为闭包分类器提供更多有效信息,并发现相对更重要的那些示例。同时,改进后基于门控注意力机制的MIL池化模块以及通过神经网络确定参数得到的变换函数![]()
![]() 和
和![]() 使得整个模型完全可微,并更具自适应性。
使得整个模型完全可微,并更具自适应性。
3.2.6损失函数
在本文的多示例学习标签检验中,使用对数损失函数(即负的对数似然函数)作为损失函数来度量生成的预测结果与样本标签之间的关系,函数表达式可用如下公式表示:

极大对数似然函数的思想是从模型得到一个对数似然函数,优化该函数得到合适的参数;利用结果反推出导致结果的参数值。而对数损失函数用到了极大似然估计的思想。![]()
![]() 是指基于现有模型,样本X的预测值为Y的概率,也就是说对于样本X预测正确的概率。而在问题假设的伯努利二项分布中,对数似然函数(log-likelihood function)与对数损失函数(logarithmic loss function)的表达式数值相等,符号相反,损失函数的目标是最小化,似然函数则是最大化,二者仅相差一个符号。
是指基于现有模型,样本X的预测值为Y的概率,也就是说对于样本X预测正确的概率。而在问题假设的伯努利二项分布中,对数似然函数(log-likelihood function)与对数损失函数(logarithmic loss function)的表达式数值相等,符号相反,损失函数的目标是最小化,似然函数则是最大化,二者仅相差一个符号。
对数损失函数具有分类面稳定,严格凸,且二阶导数连续等优点。
3.3结果及精度分析
模型的训练及测试是在NVIDIA GeForce GTX1060 GPU显卡加速下完成。在训练阶段,具体实验环境配置见表3-1,主干深度学习网络参数的设置见表3-2,模型训练1000轮,耗时约6小时。
在测试阶段,测试数据集中共有302张肾小球图像,共耗时20分55秒,一个尺寸为
图像的平均预测时间为4.2秒。
| 表3-1实验环境配置 | |
| 名称 | 配置 |
| 编程语言 | |
| 深度学习框架 | Pytorch |
| 图像处理驱动 | |
| 操作系统 | Windows 10 |
| GPU | NVIDIA GeForce GTX1060 |
| 表3-2自适应矩估计法参数设置 | |
| 参数 | 设定值 |
| Optimizer | Adam |
| Betas | 0.9, 0.999 |
| Learning_rate | 0.0001 |
| Weight_decay | 10e-5 |
对于训练过程本文使用了对数损失函数作为损失函数,并设置了误差函数对网络进行优化。在1000轮的训练中,每50轮会记录一次对数损失函数![]()
![]() 和平均绝对误差函数
和平均绝对误差函数![]() 本文将损失函数的变化情况用曲线图进行了绘制,如图3-6所示
本文将损失函数的变化情况用曲线图进行了绘制,如图3-6所示
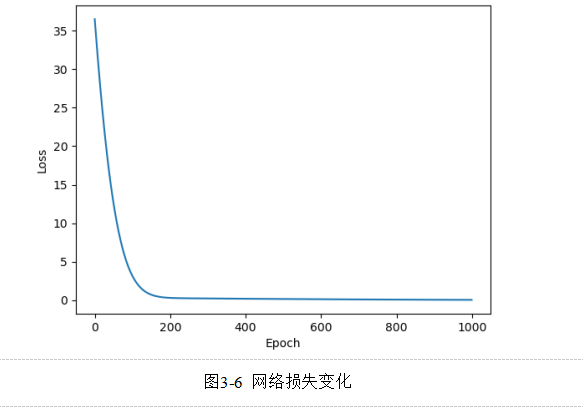
最终,基于门控注意力机制的MIL网络的损失为0.577(损失函数的计算方法见3.2.6节),网络训练的效果较佳。
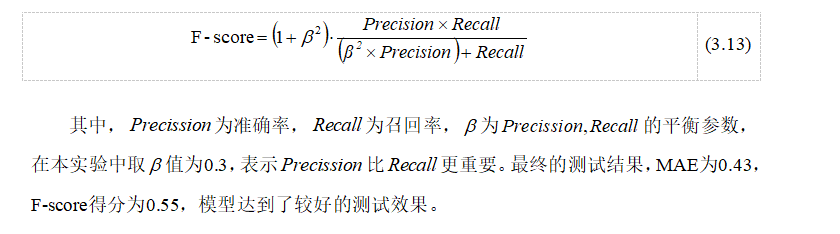
本文在测试过程中使用平均绝对误差和F-score得分来评价模型,F-score得分的计算方式如式(3.13)所示:
第四章 总结与展望
4.1总结
糖尿病肾病是糖尿病主要的并发症之一,初期症状不明显,但在后期将会出现肾脏功能的并发症,致死率较高。我国糖尿病病例存在不断上涨的趋势,对于我国病理医生缺口不断扩大的情况,能够针对糖尿病肾病患者病理切片展开高效精准的诊断的,肾小球基底膜增厚作为糖尿病肾病的典型病理性特征之一,可以作为一种有病理学依据的辅助诊断手段的切入点。本文针对糖尿病肾病的这一特点展开研究工作。现将工作总结如下:
(1) 与山西省医科大学第二医院建立深度合作伙伴关系,获取到近十年的包括糖尿病肾病患者在内的肾活检病理切片,采用数字病理切片扫描系统,对两千余例病患的肾脏病理切片开展采集工作,将其文件格式转换为Python支持读取的格式。
(2) 使用Faster-RCNN目标检测神经网络,在完整的病理切片图像中识别出肾小球,生成肾小球检测框,过滤掉置信度较小的检测框后,将肾小球从原图像中切割出来,从而构建出本实验所需的肾小球数据集。
(3) 使用AMIL神经网络模型,对肾小球示例样本进行检测和训练,来获取肾小球基底膜增厚的图像特征,以提高之后样本预测的准确率。
(4) 基于训练得到的AMIL神经网络参数,对测试集中肾小球基底膜增厚进行检测,分析模型的性能表现以及选取肾小球基底膜增厚作为分类依据的可靠性,为肾小球基底膜增厚对糖尿病肾病的临床诊断提供了指导与辅助。
基于AMIL神经网络训练过程中对样本数据分布的分析,本文得出以下结论:在模型的训练与测试实践中,以肾小球基底膜增厚作为诊断依据,对糖尿病肾病患者与非糖尿病肾病患者区分效果显著,因此肾小球基底膜增厚可作为糖尿病肾病患者的初步诊断标准
4.2展望
本次研究围绕肾小球基底膜厚度增加的糖尿病肾病辅助诊断展开多维度、深层次的分析和研究,通过多示例学习的方法针对糖尿病肾病诊断的提供有价值的参考依据。作为一门严谨的学科,特别针对疾病诊断过程中,诊断准确性是基础条件,然本文工作成果对于人工智能在病理诊断方面的研究还是有借鉴意义的。本次研究依然存在诸多缺陷和不足,需要在后续的研究中加强研究深度和广度,具体总结如下:
(1) 实验数据来源为通过与山西省医科大学第二医院合作获取的近十年的包括糖尿病肾病患者在内的肾活检病理切片,但糖尿病肾病患者的病理切片样本数据量并不充足,数据集规模较小,对训练所得模型在更多样本预测场景下的泛化表现会产生较大影响。
(2) 在本文研究过程中,重点实现了对肾脏病理组织切片中肾小球基底膜部分的检测与识别,并将糖尿病肾病中基底膜增厚的识别应用于糖尿病肾病的临床辅助诊断中,进一步为糖尿病肾病的疾病分期提供有效辅助。但实际在临床实践中,对糖尿病肾病的诊断并不是依据局部病灶的单一症状的。后续可通过糖尿病肾病多种病理特征建立关于肾小球病症识别模型,并将各种病理特征融入其中,有效提升病理诊断的准确性。
(3) 本文所使用的Attention-based Deep Multiple Instance Learning[12]神经网络在糖尿病肾病中肾小球基底膜增厚识别的问题场景下表现良好,可以尝试将门控注意力机制引入多标签和分类机制更复杂的多分类问题中。相应地,对问题建模做出的基本假设也应随着实际问题的需要进行重新分析和讨论。
(4) 本次研究内容仅限于糖尿病肾病领域的诊断,缺乏足够的实证研究和应用,希望在后续的研究中得到专业的指导,来论证方法的可行性与合理性。要想实现更科学、更接近病理医生诊断方法的诊断模式,仍需对糖尿病肾病临床诊断经验的进一步研究总结,并进一步运用深度学习方法训练出泛化能力更强、误差足够小的神经网络,才能使得人工智能辅助诊断技术更进一步。
参考文献
刘莉莉,陈飞,谢希.糖尿病肾病及其治疗研究进展[J].医学综述2020年3月第26卷第6期 Medical Recapitulate,Mar. 2020,Vol. 26,No. 6.张舒媛,王东超,李博,徐暾海,刘铜华.糖尿病肾病研究进展[J].世界中医药 2015年10月第10卷第10期.邹万忠.肾活检病理学(第二版)[M].北京:北京大学医学出版社,2014于天宇.糖尿病肾病肾脏病理改变与预后关系的研究[D].北京协和医学院.中国医学科学院.2023年5月.陈涛,邓辉舫.多示例学习算法及其应用研究[D].华南理工大学.2013年10月.Dietterich T. G., Lathrop R. H., Lozano-Pérez T., Solving the multiple-instance problemwith axis-parallel rectangles [J], Artificial Intelligence, 1997, 89(1-2): 31-71.Maron O., Lozano-Pérez T., A framework for multiple-instance learning [J]. Advances in Neural Information Processing Systems 10, Cambridge, MA: MIT Press, 1998, 570-576.Zhang Q, Goldman S.A., EM-DD: an improved multiple-instance learning technique [J], Advances in Neural Information Processing Systems 14, Cambridge, CA: MIT Press, 2002: 1073-1080.周瑞泉,纪洪辰,刘荣.智能医学影像识别研究现状与展望[J].第二军医大学学报.2018年8月第39卷第8期. DOI:10.16781/j.0258-879x.2018.08.0917.吴雪,李宗民.基于多示例学习的图像分类技术研究[D].中国石油大学.2018年6月.王琦,李刚.基于多示例学习的图像检索与分类[D].燕山大学.2023年5月.Maximilian Ilse,Jakub M. Tomczak, Max Welling.Attention-based Deep Multiple Instance Learning[J].Arxiv:1802.04712v4 [cs:.LG] 28 Jun 2018.Zaheer, Manzil, Kottur, Satwik, Ravanbakhsh, Siamak,Poczos, Barnabas, Salakhutdinov, Ruslan, and Smola,Alexander. Deep Sets. In NIPS. 2017.Qi, Charles R, Su, Hao, Mo, Kaichun, and Guibas,Leonidas J. PointNet: Deep learning on point sets for 3d classification and segmentation. In CVPR, 2017.Ramon, Jan and De Raedt, Luc. Multi instance neural networks. In ICML Workshop on Attribute-value and Relational Learning, pp. 53–60, 2000.Maron, Oded and Lozano-P´erez, Tom´as. A framework for multiple-instance learning. In NIPS, pp. 570–576, 1998.Kraus, Oren Z, Ba, Jimmy Lei, and Frey, Brendan J. Classifying and segmenting microscopy images with deep multiple instance learning. Bioinformatics, 32(12):i52–i59, 2016.Lin, Zhouhan, Feng, Minwei, Santos, Cicero Nogueira dos, Yu, Mo, Xiang, Bing, Zhou, Bowen, and Bengio, Yoshua. A structured self-attentive sentence embedding. 2017.Raffel, Colin and Ellis, Daniel PW. Feed-forward networks with attention can solve some long-term memory problems. 2015.Zhou Z H.A Brief Introduction to Weakly Supervised Learning[J].National Science Review, 2017(1):1.Ren S, He K, Girshick R, et al. Faster R-CNN: towards real-time object detection with region proposal networks[C]//International Conference on Neural Information Processing Systems. MIT Press, 2015:91-99.

1、如文档侵犯商业秘密、侵犯著作权、侵犯人身权等,请点击“文章版权申述”(推荐),也可以打举报电话:18735597641(电话支持时间:9:00-18:30)。
2、网站文档一经付费(服务费),不意味着购买了该文档的版权,仅供个人/单位学习、研究之用,不得用于商业用途,未经授权,严禁复制、发行、汇编、翻译或者网络传播等,侵权必究。
3、本站所有内容均由合作方或网友投稿,本站不对文档的完整性、权威性及其观点立场正确性做任何保证或承诺!文档内容仅供研究参考,付费前请自行鉴别。如您付费,意味着您自己接受本站规则且自行承担风险,本站不退款、不进行额外附加服务。
原创文章,作者:打字小能手,如若转载,请注明出处:https://www.447766.cn/chachong/67275.html,