摘 要
随着互联网的发展,人类可以获得的数据信息量呈指数型增长,我们能够从数据中获得的知识也大大增多,人工智能的研究和应用再一次焕发活力。随着人工智能应用的不断发展,近年来,产生了有关视觉问答(Visual Question answering,VQA)的研究,并发展成为人工智能应用的一大热门问题。视觉问答任务是一个多领域、跨学科的任务,以一张图片和一个关于图片形式自由、开放式的自然语言问题作为输入,以生成一条自然语言答案作为输出[1]。简单来说,VQA就是对给定的图片进行问答。本设计结合当前VQA的研究现状,基于深度学习理论,研究了VGG+LSTM网络的视觉问答系统,即用VGG网络对图片进行特征提取,用LSTM网络对问题进行特征提取和系统输出答案的特征生成。最终将这一复杂的人工智能系统,转化为一个多分类问题,实现了对一张图片用自然语言句子进行提问,然后用自然语言的一个单词来回答。本设计的主要创新点是将深度学习领域内的计算机视觉和自然语言处理两个方向进行多模态融合[2],将系统的输出转化为一个分类问题,达到了对图片进行一问一答的效果。
关键词:VQA;视觉问答;VGG网络;LSTM网络;深度学习;人工智能
1.绪论
1956年夏,在X达特茅斯学院,麦卡锡、明斯基等科学家开会研讨“如何用机器模拟人的智能”,首次提出“人工智能(Artificial Intelligence,简称AI)”的概念,标志着人工智能学科的诞生。在过去的六十多年内,人工智能的发展历程跌宕起伏。从上世纪的九十年起,计算机领域进入高速发展阶段,人工智能同样在算法(机器学习、深度学习)、算力(云计算)和算料(大数据)等“三算”方面取得了重要突破,使得人工智能在技术层面从“不能用”到“可以用”出现拐点。
随着人工智能的不断发展,近年来,产生了视觉问答系统(visual question answering,VQA)这一课题,并且成为人工智能研究的一大热门问题。通俗的讲,一个合格的VQA系统是将图片和关于图片的内容信息的问题共同作为系统的输入,然后系统结合图片和问题的的信息特征,产生一条符合人类逻辑思维的自然语言作为输出。针对一张特定的图片,如果想要机器以一条自然语言句子来回答关于该图片的某一个特定问题,则需要让机器对图片的内容、问题的含义和意图以及日常的逻辑思维和常识都有一定的理解能力。故就其任务本身而言,这是一个多学科,跨领域的研究问题。
1.1 视觉问答系统
视觉问答系统的定义:一个VQA系统以一张图片和一个关于这张图片形式自由、开放式的自然语言问题作为输入,以生成一条自然语言答案作为输出。简单来说,VQA就是对给定的图片进行问答[1]。
近来,开发出一个可以回答任意自然语言提问的计算机视觉系统可以说是一个充满挑战的目标,VQA的前身就是问答系统(Question Answering System, QA),问答系统同样也是人工智能和自然语言处理领域的热门研究问题。人工智能的研究过程就是将一个强AI的问题划分为若干个弱AI的问题,对于VQA这样一个复杂困难、涉及多学科的问题,我们可以将这个复杂问题划分为图像识别和文本语义分析两个弱AI问题,于是本设计的VQA系统就是将深度学习(Deep Learning)领域内计算机视觉(CV)和自然语言处理两大研究方向进行了融合。
一个成功的VQA系统应当是什么样子?接下来我们通过一张图片,来进一步理解VQA系统,以及VQA系统的主要解决问题。如图1-1
上图是理解VQA问题描述的经典例图,图中有一个人物主体和两条与图片相关的自然语言问问题,首先分析第一个问题,问图中女性的眼睛是什么颜色?对于这条问题,我们首先在NLP层面理解问题,可以提取到两个关键的单词eyes和color;然后在CV层面提取图片的特征,针对图像的像素值,纹理特征或者卷积特征(convolution feature)等够准确找到眼睛的位置信息,并且能够提取到该区域一系列特征,包括颜色、纹理、形状等特征和空间关系等;最后根据NLP提问的颜色提问,给出对应的特征,然后由系统生成对应的自然语言词句作为回答。对于第二个问题,胡子的是由什么组成的?这个问题对于系统就要有更高的逻辑思维能力和常识意识。很明显,通过人为逻辑思维理解判断,问题并不是要问胡子的正常构成成分,而是希望得到的回答是香蕉,即在胡子的位置是什么物体?因为女性一般情况下是没有胡子的。所以,系统要有一定的常识判断能力,再根据图像特征提取到图像的空间关系,文本语义信息处理,最后回答出正确的答案。
1.2 VQA背景和研究现状
1.2.1 VQA发展背景和研究意义
随着自然语言处理技术的发展,许多研究逐渐转向了复杂、更智能化的问题。2015年,Aishwarya Agrawal和Devi Parikh等人发表文章,首次提出了VQA问题,并且给定了关于图像的图像和自然语言问题,任务是提供准确的自然语言答案。他们提供了一个包含0.25M大小的图像包,0.76M大小的问题包和10M大小的答案包的数据集,以及许多VQA的基线和方法,并与人类表现进行了比较。
作为一种区别于传统卷积神经网络对图片的处理(目标检测、图像分割、场景识别等),VQA更侧重与一种对图像的描述,即通过自然语言处理技术,将系统加入了更高层次的逻辑思维能力和常识思考能力。所以,VQA也进一步的促进了人机交互能力和强AI问题的发展。对于计算机多媒体领域的发展同样起到促进作用,对于海量图像文本信息检索和人工智能基础测试和图灵测试的发展也有帮助。在商业上,该系统的实现直接能够让视觉受损的用户受益,同样也可能改变传统的儿童智能早教行业。
1.2.2 VQA的发展历程和研究现状
(1)联合嵌入法:Joint embedding approaches
来源于深度学习的NLP的发展。相较于看图说话,VQA则多了一步在两个模态间的进一步推理过程。一般的,图像表示(image representations)用预训练的CNN模型,文本表示(Text representations)用预训练的词嵌入。词嵌入就是将单词映射到空间中,距离来度量语义相似度,然后将嵌入送到RNN中来处理语法和句子。
具体的实现方法为:Malinowski et al等人提出了“Neural-Image-QA”模型[3],文本特征提取用加入了LSTM网络的RNN来处理,图像特征用预训练的CNN来处理,然后将两个特征同时输入到第一个编码器LSTM中,再将生成的向量输入到第二个解码器LSTM中,最后会生成一个变化长度的答案,每次迭代产生一个单词,知道产生<end>分词为止。结构如图1-2:
联合嵌入法非常直接,是目前大多数VQA的基础,除了上边介绍的框架之外,还有许多使用联合嵌入法的框架,基本都是基于预训练CNN来提取图片特征和RNN来提取文本特征,只是在多模融合和答案生成时有所不同。目前该方法还有很大的提升空间。
(2)注意力机制:Attention mechanisms
上面提出联合嵌入法的模型,在视觉特征输入这里,都是提取的全局特征作为输入,会产生一些无关或者噪声信息来影响输出,而注意力机制就是利用局部特征来解决这个问题。
注意力机制能够改善提取全局特征的模型性能[4]。最近的研究表明,注意力机制尽管能够提高VQA的总体精度,但是对于二值类问题却没有任何提升,一种假说是二值类问题需要更长的推理,这类问题的解决还需要进一步研究。
(3)合成模型:Compositional Models
这种方法是对不同模块的连接组合,优点是可以更好的进行监督。一方面,能够方便转换学习,另一方面能够使用深度监督“deep supervision”。这里主要讨论的合成模型有两个,一个是Neural Module Networks (NMN),另一个是Dynamic Memory Networks (DMN)。
Andreas et al等人提出了Neural Module Networks (NMN)[5],NMN的贡献在于对连续视觉特征使用了逻辑推理,而替代了离散或逻辑预测。模型的结构框架如图1-3:
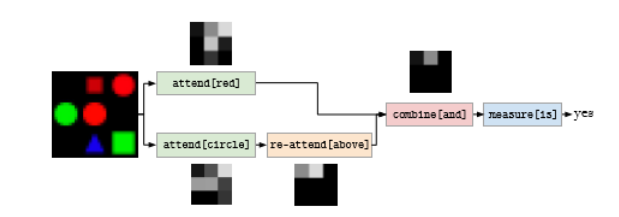

图1-3 合成模型
模型的输入和输出一共有三类:图像,图像注意力区域,标签。该方法比传统方法能更好的进行推理,处理更长的问题。但是局限性在于问题解析这里出现了瓶颈,此外,模块结合采用问题简化的方式,这就忽略了一些语法线索。
(4)使用外部知识的模型:Models using external knowledge bases
VQA在理解图像内容时,经常需要一些非视觉的先验信息,涉及范围可以从常识到专题,目前已有的外部知识库包括:DBpedia、Freebase、YAGO、OpenIE、NELL、WebChild、ConceptNet。
Wang et al等人提出了基于DBpedia[6]的VQA网络命名为“Ahab”,,首先用CNN提取视觉概念,然后结合DBpedia中相似的概念,再学习image-question到查询的过程,通过总结查询结果来获得最终答案。还有一种基于该方法的改进模型,叫FVQA。是Wu et al等人提出了一种利用外部知识的联合嵌入法,首先用CNN提取图像的语义属性,然后从DBpedia检索相关属性的外部知识,将检索到的知识用Doc2Vec嵌入到词向量中,最后将词向量传入到LSTM网络,对问题进行解释并生成答案。但这种方法同样存在性能和缺陷,一个问题就是这些模型的问题类型都有限。
1.3 论文结构安排
第一章,主要介绍视觉问答系统的定义和发展背景,以及VQA目前的发展前景和在未来商业上的潜在应用价值。最后总结了一下当前VQA的研究过程中,目前常用的四种研究方法。
第二章,主要介绍本论文系统需要使用的相关技术,包括图像和问题的特征提取,以及最后系统生成回答的方法。其中重点讲解VGG和LSTM两个神经网络的原理和运用。
第三章,介绍当前的VQA研究过程中主要使用的数据集,并且详细介绍本文中使用的数据集。
第四章,主要介绍本论文中VQA系统的框架结构和训练验证结果。主要采用VGG+LSTM作为特征提取网络,最后使用softmax分类器作为系统的输出。在训练过程中数据的预处理,参数的选择和调节以及最后的系统性能的评价方案。
第五章,总结本论文的主要工作,以及对未来VQA发展进行展望。
2. 相关工作准备
本文采取VQA的研究方法是基于上边所介绍的联合嵌入法,同样是用预训练的CNN网络来提取图像的特征,使用RNN网络来进行文本的特征提取,然而当前并没有一个科学准确地评价自然语言句子精准度的标准,因此我们只能在有技术方法中,用一个单词作为VQA的输出答案,这样就可以把视觉问答任务转换成一个多分类问题,从而可以利用现有的准确度评价标准来度量系统性能。我们在开始构建模型框架之前,我们首先介绍用来进行图像特征提取的VGG网络和进行文本特征提取的LSTM网络,以及最后用来产生答案的分类[7]。
2.1 图像特征提取
卷积神经网络(CNN)最初设计被用来做图片分类工作,近来也被用来做图像分割,图像风格迁移以及其他计算机视觉的工作;当然,也有被用来做NLP的例子。卷积神经网络是最能解释深度学习的模型之一,因为我们可以将它的表达特征可视化来理解它可能学习到的东西。
VGG是Oxford的Visual Geometry Group的组提出的。该网络是在ILSVRC 2014上的首次被提出,主要工作是为了证明在保证模型具有相同大小的感受野的情况下,增加网络的深度能够在一定程度上提高网络最终的性能。常用到的VGG网络有两种,分别是VGG-16和VGG-19,两个网络并没有本质上的区别,只是网络深度不一样,VGG-16网络结构如图2-1。
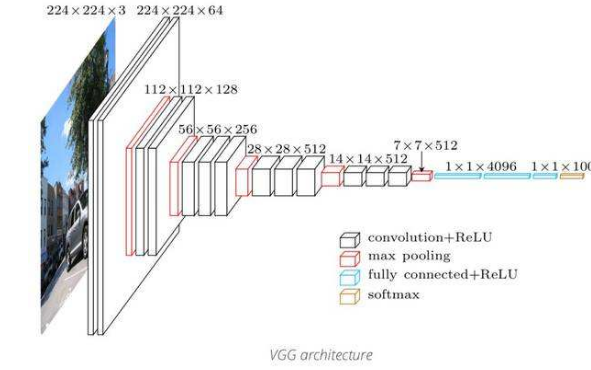
图2-1 VGG-16模型结构
在用来处理图像的卷积神经网络中,VGG网络是我最喜欢使用的网络,并且是我认为最好用的网络。VGG网络的结构非常清晰简明,整个网络都使用了大小尺寸相同的卷积核(3×3)和最大池化尺寸(2×2)。同AlexNet网络相比,这样做的目的就是在相同感受野和步长的情况下,VGG网络使用几个小滤波器(3×3)卷积层的组合比AlexNet网络使用一个大滤波器(5×5或7×7)卷积层效果更好,并且验证了通过不断加深神经网络结构的深度,这样可以同时提升网络的整体性能。但是,更换了小的卷积核尺寸,网络的性能得到了提高,但却耗费更多计算资源,在相同的计算性能下,VGG网络花费了更多的计算时间,提取图像的卷积特征变得更慢,主要的原因是在网络层使用了更多的参数,其中大部分的权重参数都是来自于第一个全连接层,并且,VGG网络有3个全连接层。这样使得模型参数权重达到500M左右。
2.2 文本特征提取
循环神经网络(Recurrent Neural Network, RNN)[8]是一类以序列(sequence)数据(相互依赖的数据流,比如时间序列数据、信息性的字符串、对话等)为输入。在序列的演进方向进行递归(recursion),且所有节点(循环单元)按链式连接的递归神经网络(recursive neural network)。RNN可以用到很多领域中去,除了本设计中用来文本分析和文本生成之外,RNN还用在机器翻译,语音识别,生成图像描述,视频标记等领域。引入了卷积神经网络构筑的循环神经网络可以处理包含序列输入的计算机视觉问题。
在二十世纪80-90年代,开始了对循环神经网络的研究,并在二十一世纪初发展为深度学习优秀算法之一,其中双向循环神经网络(Bidirectional RNN, Bi-RNN)和长短期记忆网络(Long Short-Term Memory networks,LSTM)是常见的循环神经网络,接下来主要阐述LSTM网络的工作原理。
LSTM是一种特殊的RNN模型,是由Hochreiter&Schmidhuber在1997年首先提出,最初是为了解决RNN模型梯度弥散的问题,但是在后来的工作中被许多人精炼和推广,现在被广泛的使用。在传统的RNN中,训练过程使用的是基于时间的反向传播算法(back-propagation through time,BPTT),当时间比较长时,需要回传的误差会指数下降,导致网络权重更新缓慢,无法体现出RNN的长期记忆的效果,因此需要一个存储单元来存储记忆,因此LSTM模型顺势而生。从图2-2和2-3我们可以看出传统RNN网络和LSTM网络两种模块链的区别。
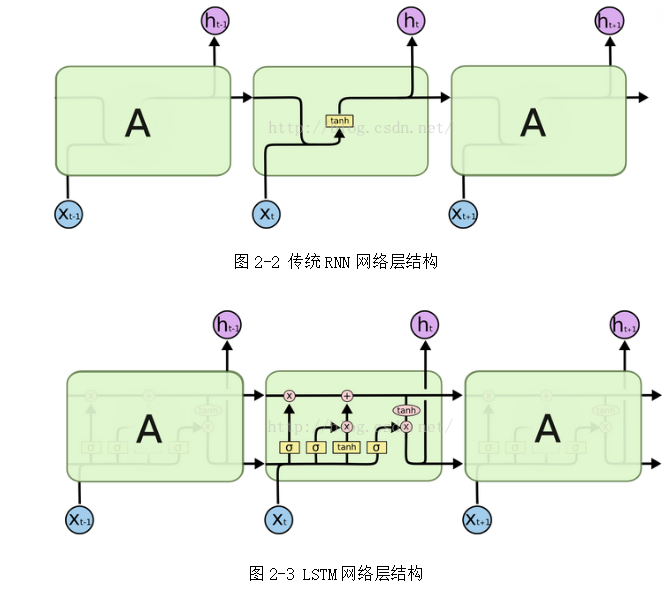
与RNN网络的结构不同之处是LSTM网络最顶层多了一条名为“cell state”的信息传播带,cell state就是信息记忆的地方,如图2-4。
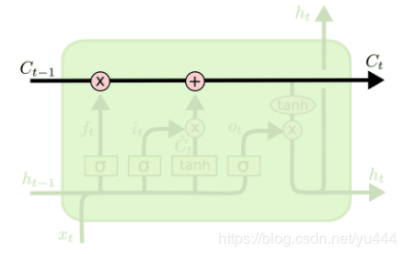
图2-4 cell state
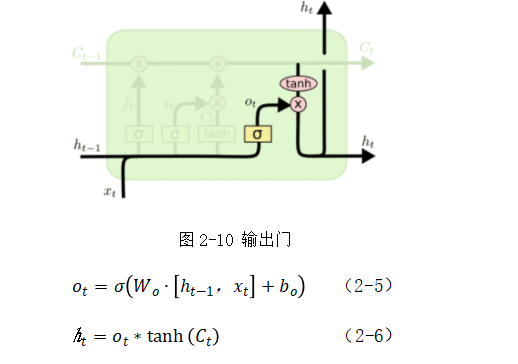
其实就是整个模型中的记忆空间,随着时间而变化的,当然,cell state本身是无法控制哪些信息是否被记忆,而真正其控制作用的是控制门(gate);控制门的结构如图2-5:主要由一个sigmoid函数跟点乘操作组成;sigmoid函数的值域在0-1之间,点乘操作决定多少信息可以传送过去,当sigmoid函数值为0时,则cell state不传送存储的信息,当sigmoid函数值为1时,则cell state将所有存储的信息进行传送。LSTM中有3个控制门:输入门、输出门、记忆门,三个控制门作用各不相同,具体功能如下:
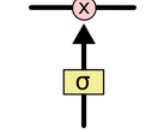
图2-5 控制门结构图
(1)记忆门:如图2-6,选择忘记或者存储过去某些记忆信息,即公式(2-1):
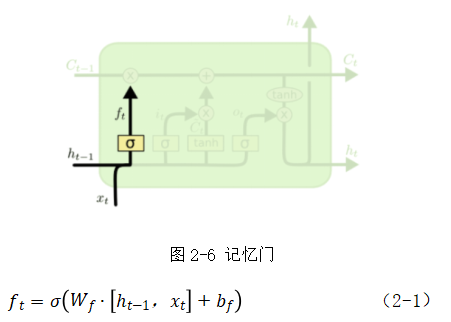
图2-6 记忆门
(2-1)
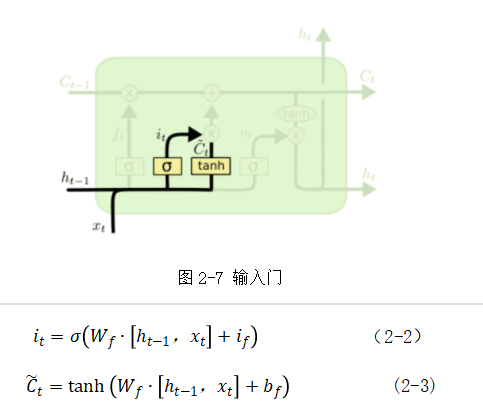
(2)输入门:如图2-7,存储当前输入的某些信息,即公式(2-2)、(2-3):
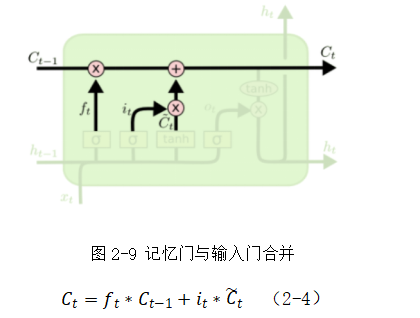
(3)如图2-8,将记忆门与输入门的存储信息进行合并,即公式(2-4):
(4)输出门:如图2-10,存储传递到下一个模块链记忆门的信息,即公式(2-5)、(2-6):
2.3 输出分类器
分类是数据挖掘的一种非常重要的方法。分类的概念是在已有数据的基础上学会一个分类函数或构造出一个分类模型(即我们通常所说的分类器(Classifier))。分类器是数据挖掘中对样本进行分类的方法的统称,常用的分类方法包含决策树、逻辑回归、朴素贝叶斯、支持向量机(SVM)等算法。
对于本文的VQA系统,我的期待的输出答案,本应该是将图像特征和文本特征进行多模态融合,然后在传入LSTM网络进行训练,然后生成一条自然语言的特征向量,最后经过一个文本解码器输出。但是鉴于现在没有一个好的评价生成自然语言准确率的标准,我们用一个关键单词来替换自然语言句子作为系统的最后输出,具体做法如下文。
本文对所有训练数据的回答进行处理,将所有的回答出现按次数统计,然后排序,选择前1000个经常出现的答案,这些答案中包括yes、no、1、2、red、green等在现实生活中经常用的回答,而且这个回答样本基本上已经涵盖了整个回答数据集的82.67%以上的回答。于是我们就将系统转换成一个1000类的多分类问题。
softmax分类器是神经网络中最常用的分类器。它简单有效,所以十分流行。Softmax的原理就是,对于一个输入x,我们想知道它是 N 个类别中的哪一类。现有一个模型,能对输入x 输出 N 个类别的评分,评分越高代表 x 是这个类别的可能性越大,评分最高的被认为是 x 正确的类别。然而评分范围很广,我们希望把它变成一个概率,而 softmax 就是一个能将![]()
![]() 的评分转化为一组概率,并让它们的和为1的归一化函数(squashing function)如公式(2-7)。
的评分转化为一组概率,并让它们的和为1的归一化函数(squashing function)如公式(2-7)。
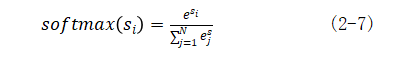
(2-7)
其中![]()
![]() 表示模型对输入x 在第 i个类别上的评分值。
表示模型对输入x 在第 i个类别上的评分值。
3. VQA数据集
与自然语言处理或计算机视觉中的许多问题一样,例如机器翻译、图像标注(Image Captioning)或图像识别,数据集的可用性是一个关键问题。VQA领域非常复杂,一个好的数据集体积应该足够大,大到能够在真实的场景中捕捉问题和图像内容的各种可能性。如今许多数据集中的图像都来自微软的MS-COCO数据集,这个数据集包含了32.8万张图像,91个对象类型,250万个标记的实例,涵盖了现实生活各个场景。
目前,在学者和企业的研究过程中,已经出现许多VQA的数据集[9],主要包括四类:第一类是自然场景的数据集,有DAQUAR、COCO-QA、FM-IQA、VQA-real、Visual Genome、Visual7W、VQA-v1和VQA-v2等;第二类是合成场景的数据集,有VQA abstract scenes、Balanced dataset和CLEVR等;第三类是外部知识数据集,主要有KB-VQA和FVQA;最后一类就是其他的数据集,主要有Diagrams和Shapes。本文研究过程中所使用的是第一类的自然场景数据集。接下来主要介绍DAQUAR、COCO-QA、VQA-v1和VQA-v2这几个数据集:
(1)DAQUAR(DAtaset for QUestion Answering on Real-world images)
DAQUAR数据集是最早的,也是最小的VQA数据集包含了6795张训练数据和5673张测试数据,所有图像来自于数据集NYU-DepthV2 Dataset。该数据集质量较差,一些图像杂乱无章,分辨率低,并且问题和回答有明显的语法错误。虽然这个数据集是一项伟大的创举,但NYU的数据集只包含室内场景。关于在室外的问题就很难回答出来。对人类的评估,NYU数据集显示了50.2%的准确率。DAQUAR数据集的另一个缺点是它的大小使它不适合用于训练和评估复杂模型。
(2)COCO-QA
COCO-QA数据集比DAQUAR大得多。它包含123,287张来自COCO数据集的图片,78,736个训练和38,948个测试question-answer pairs。为了创建如此大量的question-answer pairs,Ren M , Kiros R , Zemel R等人[10]使用了自然语言处理算法来自动从COCO图像标注(image caption)中生成它们。例如,对于一个给定的标注,比如“房间里的两把椅子”,它们会产生一个如“有多少椅子?”的问题,必须注意的是,所有的答案都是一个单一的词。
虽然这种做法很聪明,但这里存在的问题是,这些问题都具有自然语言处理的限制,所以它们有时会被奇怪地表述出来,或者有语法错误。在某些情况下,它们的表达是难以理解的。另一个不便之处是,数据集只有四种问题,问题分布也不均匀:对象(69.84%)、颜色(16.59%)、计数(7.47%)和位置(6.10%)。
(3)VQA-v1和VQA-v2
与其他数据集相比,VQA数据集比较大。除了来自COCO数据集的204,721张图片外,它还包含5万个抽象的卡通图片。每个图像对应三个问题,每个问题有十个答案。由此可以得出VQA数据集有超过76万个问题,大约有1000万个答案。
VQA-v1发布于2015年,VQA-v2发布于2017年,两个版本都是基于微软的COCO数据集。v2是在v1的基础上,两个数据集都是人工标注的问答数据集,v2相较于v1尽量减少了语言偏见。对于问题的类型:v1是多项选择得问题(Multiple-Choice),v2是开放式问答(Open-Ended)。
每个版本的数据集内,除了图片都相同之外,分别还有训练数据、验证数据和测试数据的问题和答案,都是以josn文件存储。具体的文件格式如下表3-1:
表3-1 VQA数据集字段类型
| Name | Type类型 | Description描述 |
| image_id | int | 图片ID |
| question_id | int | 图片对应的问题ID |
| question | str | 图片对应的问题 |
| answer_id | int | 问题对应的回答ID |
| answer | str | 问题对应的回答 |
本文的系统使用的数据集,受计算机性能的限制,采用是对VQA-v2的部分数据,其中包括训练图像82,738张,大约12.7G,验证图像40,504张,大约6.25G。
4. VGG+LSTM网络的视觉问答系统
4.1 数据预处理
第三章我们已经介绍了VQA的数据集,这里我们选择VQA-v1版本的数据集,它分为两部分: 一部分是由 MS-COCO 数据集提供的,包含现实世界照片的数据集,以及另一个包含了抽象图画场景的数据集。后者通常只包括人物等内容,移除了图像噪声,主要用于进行高阶的推理用途。问题和答案由众包源的标注员提供。每个问题有十个答案,答案分别来自不同的标注员。答案通常都是一个单词或是短句。大约 40%的问题答案为是或否。为了评估需要,同时提供开放性答案和多选答案两种格式。多选答案的问题一共有 18 个备选答案。本实验将开放性 VQA 视为 N 分类问题,即选择出现频率最高的 N 个答案,然后对于每一组问题和图像输入,输出一个分类。作为答案。本实验选择的 N=1000,大约覆盖了整个数据集中答案的 82.67%。
4.1.1 图像数据归约
对于tensorflow深度学习的框架,需要的数据是一个张量(tensor)。在本系统中,用scipy这个科学计算工具包来加载图片,然后用numpy将加载的图片转换为一个224*223*3的三维数组向量,并且将数组内的每个像素值除以225,归约到0-1之间,因为VGG-16网络接受的是像素在0-1的RGB三通道图像。并且载数据规约之后,图像像素值虽然变小,但仍大致保持原数据的完整性。这样,在归约后的数据集上挖掘将更有效,并产生相同(或几乎相同)的分析结果,同时更加利于模型训练过程的损失函数下降和网络权重参数的优化。
4.1.2 文本数据处理
数据集内的训练和验证question-answer都是以josn文件存储,文件比较大,而且存在不同图片相同问题的情况。在训练过程中,如果每次都用IO来读取文件,过程会比较慢,同时占用计算资源,这里我们将所有的question-answer和对应ID从json文件中抽取,然后一一对应整合到同一个文件,并且以pkl文件的形式存储。
同样在最后softmax分类器最后输出结果的时候,需要一个解码过程,这时候我们需要一个参照的数据字典(vocab),就是将前1000个最常出现的回答,与他们的向量特征做一个一一对应的参照,同样我们以pkl文件存储,每次我们的系统回答结果只需要在这个vocab文件内进行转换之后输出就可以了。
4.2 VQA系统结构
本文的VQA系统采用VGG+LSTM网络来设计[11],系统的框架如图4-1:
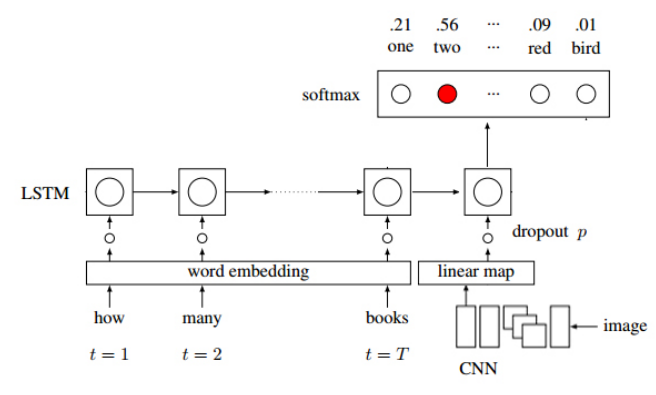
图4-1 VQA系统结构
系统整体可分为三部分:图像特征提取、问题特征提取、答案生成分类器[11]。
图像的特征提取使用VGG-16网络,这里将第二个全连接层的输出作为图片的特征向量,最终得到一个一维的4096长度大小的向量。然后将这个向量进行一个线性映射,以便于和后边的文本特征进行模态融合[11]。
问题特征提取使用一个两层的LSTM网络,每一层LSTM都有512大小的模块链。对于每一个问题进行编码的时候,都将其转换为一个长度为512的向量然后传入LSTM网络中。每一个问题经过LSTM网络特征提取后,和图片的特征进行模态融合,将图像的特征添加到问题特征后边然后再次进入LSTM进行特征提取,然后生成一个长度为1000的特征向量,传入答案生成分类器中。
答案生成分类器选择的是softmax分类器,将神经网络输出的长度为1000的向量映射到对应分类的概率,然后选择概率值最大的类别就是正确的分类结果,经过解码器输出即可。同样的方法,我们选择概率为前五的向量,将其解码输出,就是系统得到的最可能回答结果。
4.3 系统实现过程与验证结果
4.3.1 系统运行环境
本实验在Windows PC端运行,具体硬件设备性能:Inter(R)Core(TM)i5-8200U CPU @1.6GHZ 1.80GHZ 8核,16GB运行内存;软件配置:windows 10操作系统,Python3.7 tensorflow 1.14.0。
4.3.2 系统参数选择
在上文的我们已经介绍了VQA的部分参数,VGG网络为预训练的网络,图片的特征向量为大小4096的一维特征向量,问题特征提取网络为一个两层的LSTM,每层LSTM网络有512个隐藏模块链,输出的文本特征向量大小为512的一维特征向量,softmax分类器输出长度为1000的一维特征向量。
但是为了防止系统的过拟合,我们的VGG和LSTM网络后边都加上一个大小为0.5的Dropout,就是随即丢弃50%的神经单元,强迫网络去学习更多特征,以此来提高模型的泛化能力。系统的学习率(learn-rate),初始设定为0.0001,在tensorflow中,AdamOptimizer函数可以自动调节网络的学习率,该函数是基于Adam算法,AdamOptimizer可控制学习速度调节,经过偏置校正后,每一次迭代学习率都有个确定范围,使得参数比较平稳。 Adam 这个名字来源于自适应矩估计(Adaptive Moment Estimation),也是梯度下降算法的一种变形,但是每次迭代参数的学习率都有一定的范围,不会因为梯度很大而导致学习率(步长)也变得很大,参数的值相对比较稳定。概率论中矩的含义是:如果一个随机变量 X 服从某个分布,X 的一阶矩是 E(X),也就是样本平均值,X 的二阶矩就是 E(X^2),也就是样本平方的平均值。Adam 算法利用梯度的一阶矩估计和二阶矩估计动态调整每个参数的学习率。
训练过程BATCH_SIZE设定为200,迭代次数(epochs)为12次,关于BATCH_SIZE的设置我要根据实际情况来定,BATCH_SIZE的定义为一次训练所选取的样本数,在卷积神经网络中,如果是小样本的数据集训练,也可以不设置BATCH_SIZE,一次将样本全部传入网络中去,但是大型的数据集,一次的样本全部传入网络中去,势必将引起内存爆炸,于是就提出BATCH_SIZE的概念。通过训练过程,发现在迭代12次之后,系统的损失函数不在下降,准确率在52%左右,不再有明显提高。
4.3.3 系统评价标准和验证结果
本系统最后将VQA问题转换为一个多分类问题,所以,用准确率来衡量系统的性能。VQA数据集也给出了一种评估方法[7]: 。意思就是说,如果有三个或者以上人为标注的答案与系统给出的答案一致,那么此问题回答的1分,否则的0分。
。意思就是说,如果有三个或者以上人为标注的答案与系统给出的答案一致,那么此问题回答的1分,否则的0分。
我们根据这个评价标准,用验证数据集来评价系统,最终得到经过12个epochs之后,系统的准确率为50.3%。
4.4 系统测试结果
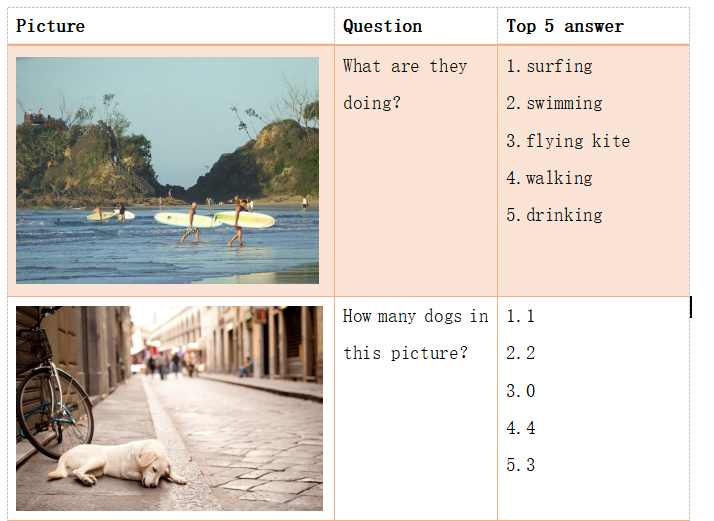
系统正确回答测试如表(4-1):
表4-1 系统正确回答问题展示

系统错误回答测试如表(4-2):
表4-2 系统错误回答问题展示表
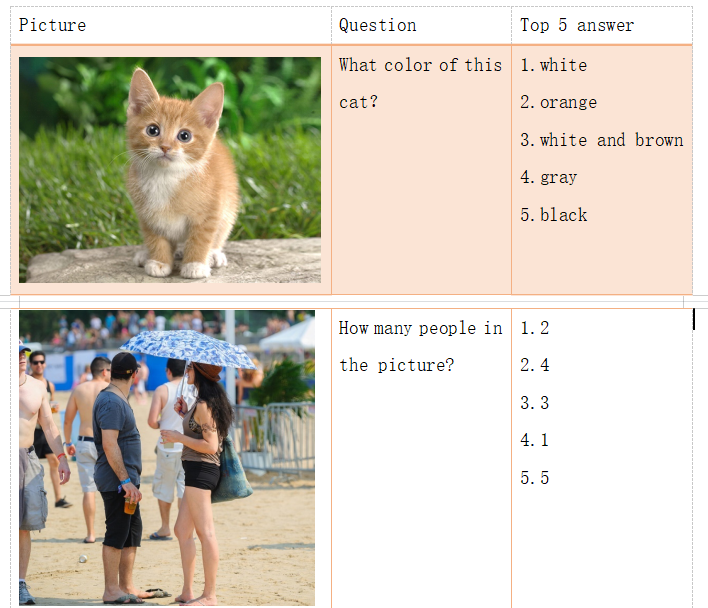

通过上边几组测试结果,我们就可以发现,目前我们训练出来的VQA系统,对于较为简单的问题的图像,系统的成功率比较高;但是针对需要计数、推理、相对复杂的、具有一定逻辑思维能力或者常识性的问题,或者图片的内容比较复杂,问题相关主体在图像中相对尺寸比较小、像素值模糊,这样系统的出错几率就会增加[13]。
5. 总结和展望
本章主要对本论文的主要内容进行总结,以及对未来VQA的发展研究方向进行展望[14]。
5.1 论文总结
本文的主要工作是利用VGG和LSTM模型,将计算机视觉(CV)和自然语言处理(NLP)两大领域相结合,完成了视觉问答任务。论文的具体工作讨论了VQA的研究意义和现如今的发展现状;并且介绍了目前VQA研究过程中常用到的数据集,并且对本文中用到的数据集惊醒了详细介绍;在VQA系统的实现过程中,详细阐述了图像和问题的特征提取方法,以及最后的答案产生过程;载系统模型训练完成后,通过制定评价方法,使用验证数据集,验证了系统的准确性。
5.2 VQA的未来发展展望
在本文的验证和测试结果中,发现本文的VQA系统准确性并不是太高,而且对于一些复杂图像和有一定逻辑思维问题处理效果不是太好,说明未来的VQA系统还有很大的提升发展空间。究其原因,VGG对图像信息进行特征提取是基于全图进行,LSTM网络在学习过程中的知识来源只有训练集中的问答对,知识结构比较简单且信息量匮乏。所以未来,VQA的问答数据集应该得到扩充,而且问题和回答的质量需要更高,当然,这是一个非常耗时、耗资的巨大任务量。对于图像的特征提取,未来的趋势是加入注意力机制,可以让神经网络在进行特征提取时,更加聚焦在问题对图像提问的关键部分。同时,随着多媒体视频的发展,未来视频存储会和图片、文本一样在我们生活中使用越来越多,同样,对于VQA的发展必将应用在视频技术处理中[15]。
随着深度学习的发展,计算机视觉和自然语言处理领域的技术越来越成熟,未来的VQA系统肯定会越来越精准。
参考文献
[1] Qi Wu,Damien Teney,Peng Wang,Chunhua Shen,Anthony Dick,Anton van den Hengel. Visual question answering: A survey of methods and datasets[J]. Computer Vision and Image Understanding,2017.
[2]李健,姚亮.融合多特征深度学习的地面激光点云语义分割[J/OL].测绘科学:1-11[2020-05-18].
[3] M. Malinowski, M. Rohrbach, and M. Fritz. Ask Your Neurons: A Neural-based Approach to Answering Questions about Images. In Proc. IEEE Int. Conf. Comp. Vis., 2015
[4] K. Chen, J. Wang, L.-C. Chen, H. Gao, W. Xu, and R. Nevatia. ABC-CNN: An Attention Based Convolutional Neural Network for Visual Question Answering. arXiv preprint arXiv:1511.05960, 2015
[5] J. Andreas, M. Rohrbach, T. Darrell, and D. Klein. Neural Module Networks. In Proc. IEEE Conf. Comp. Vis. Patt. Recogn., 2016
[6] Q. Wu, P. Wang, C. Shen, A. Dick, and A. v. d. Hengel. Ask Me Anything: Free-form Visual Question Answering Based on Knowledge from External Sources. In Proc. IEEE Conf. Comp. Vis. Patt. Recogn., 2016
[7] 张昊伟. 基于多渠道卷积神经网络-LSTM的可视化问答系统研究[D].云南大学,2018.
[8] 陈凯. 深度学习模型的高效训练算法研究[D].中国科学技术大学,2016.
[9] K. Kafle, C. Kanan. “Visual Question Answering: Datasets, Algorithms, and Future Challenges.”Computer Vision and Image Understanding, 2017
[10] Ren M , Kiros R , Zemel R . Exploring Models and Data for Image Question Answering[J]. 2015.
[11] M. Ren, R. Kiros, and R. Zemel. Image Question Answering: A Visual Semantic Embedding Model and a New Dataset. In Proc. Advances in Neural Inf. Process. Syst., 2015.
[12] 白亚龙. 面向图像与文本的多模态关联学习的研究与应用[D].哈尔滨工业大学,2018.
[13] 葛梦颖,孙宝山.基于深度学习的视觉问答系统[J].现代信息科技,2019,3(11):11-13+16.
[14] 王旭. 基于深度学习的视觉问答系统研究[D].吉林大学,2018.
[15]Yunseok Jang,Yale Song,Chris Dongjoo Kim,Youngjae Yu,Youngjin Kim,Gunhee Kim. International Journal of Computer Vision, 2019, Vol.127 (10), pp.1385-1412

1、如文档侵犯商业秘密、侵犯著作权、侵犯人身权等,请点击“文章版权申述”(推荐),也可以打举报电话:18735597641(电话支持时间:9:00-18:30)。
2、网站文档一经付费(服务费),不意味着购买了该文档的版权,仅供个人/单位学习、研究之用,不得用于商业用途,未经授权,严禁复制、发行、汇编、翻译或者网络传播等,侵权必究。
3、本站所有内容均由合作方或网友投稿,本站不对文档的完整性、权威性及其观点立场正确性做任何保证或承诺!文档内容仅供研究参考,付费前请自行鉴别。如您付费,意味着您自己接受本站规则且自行承担风险,本站不退款、不进行额外附加服务。
原创文章,作者:1158,如若转载,请注明出处:https://www.447766.cn/chachong/135248.html,