1.背景介绍
“最后一公里”是阻碍公共交通普及与发展的痛点,人们在“最后一公里”中出行成本较高同时也存在一定的社会不安全因素,例如刺激了不安全的摩的或者三轮车等非正规运营手段的发展,并且这部分运营车辆时长出现闯红灯、乱停放等妨害交通秩序的行为,大大影响了交通管理和乘客的人生安全。另外,部分市民因为车站与家的距离稍远,也在一定程度上打击了这部分市民选择乘坐公共交通的积极性,共享单车的出现以及市场化,为解决“最后一公里”难题提供了全新的解决方案,降低了市民在最后一公里的出行成本,打击了黑车市场,填补了住宅到车站的公共交通空隙,有利于推行绿色环保的出行理念[2]。2014年起,共享单车逐步投放到中国的各个大学,由于共享单车十分适合大学生以及部分高校教职工的需要,共享单车在高校市场慢慢站稳脚跟,并在这次成功的尝试后把市场拓展到城市中,逐渐成为具有竞争优势的新兴出行交通工具。
新事物的诞生必然伴随着许多问题,第一是没车,在很多人流量特别少的并且地理位置相对比较偏僻的地方,车辆流动速度比较缓慢,当一辆车被骑走时,很难预测下一辆车什么时候会骑回来,这个问题到最后会演变为无车可骑的窘境;第二对于人流量大的地方,无论共享单车的数量多么充足,这批共享单车只能满足第一批“抢到”共享单车的用户,后来者也很有可能面临无车可骑的问题,在上下班高峰期,类似情况并不少见[3]。
总结以上提出的问题,是共享单车管理效率的问题,如何提高共享单车的利用率,在什么地方投放共享单车,如何设置投放的频率,是提升共享单车服务水平的一大关键。本文将围绕纽约城市共享单车的使用数据进行数据可视化,体现每个位置共享单车的使用情况,并根据天气、工作日与非工作日、假期等建立适当的模型来预测共享单车的使用量。
2.数据获取、处理与可视化
2.1获取城市自行车使用数据
Citi Bike是一家位于纽约的私有盈利的公共自行车公司,自2013年5月开始运营,目前也是X最大的公共自行车,因此我们选用该公司的数据进行研究。
从纽约Citi Bike官方网站(https://www.citibikenyc.com/system-data)直下载自行车使用数据。Citi bike官网记录数据自2013年6月至今,选用其中一年,即从2017年4月1日至2018年3月31日的数据作为研究对象。数据总量约为1200万骑行数据。
Table 1使用数据样例
名词注释单位
Trip duration骑行时长秒
Start time开始时间日期,时间
Stop time停止时间日期,时间
start station ID起始站标记数字
start station name起始站点名字
start station latitude起始站点纬度
start station longitude起始站点经度
end station ID终点站标记数字
end station name终点站名字
end station latitude终点纬度
end station longitude终点站点经度
bikeid自行车唯一识别码
usertype用户类型
birthyear出生年份
gender性别0=未知;1=男性;2=女性
Table 2相关变量注释
为了更好的分析citi bike的使用情况,我们还需考虑天气因素。利用R里的Rcurl包对专业天气网站(www.wunderground.com)爬取天气数据。其中对两种不同类型的天气数据进行读取,第一种是读取2017年4月1日至2018年3月31日每日的天气数据,总共365个观测值,包含当日的降雨量,最高气温,最低气温,平均气温,最大能见度,最小能见度,平均能见度以及风力等天气变量;其二是读取每日每小时的天气数据,数据量总共是365×24,观测变量与前者类似。
Date temp_h temp_a temp_l humid_h humid_a humid_l visi_h visi_a visi_l wind_h wind_a wind_l
4/1/2017 50 42 37 93 77 59 10 9 4 28 13 38
4/2/2017 64 52 41 71 47 24 10 10 10 9 3-
4/3/2017 61 53 46 71 51 31 10 10 8 15 4 51
4/4/2017 48 48 46 100 91 71 10 7 1 21 11 29
4/5/2017 62 53 44 100 85 52 10 5 0 15 4 48
4/6/2017 52 47 42 100 90 80 10 7 1 29 14 36
4/7/2017 50 46 42 87 65 50 10 10 9 21 13 43
4/8/2017 60 50 39 62 40 23 10 10 7 10 5 43
4/9/2017 66 53 42 57 40 23 10 10 9 10 4-
4/10/2017 75 63 51 59 44 33 10 10 8 12 6 18
4/11/2017 78 67 57 68 54 36 10 10 8 8 5-
4/12/2017 75 65 55 82 62 24 10 9 5 14 4 17
4/13/2017 66 57 48 63 41 26 10 10 9 12 4 17
4/14/2017 64 57 50 54 41 28 10 10 9 12 5 17
4/15/2017 63 55 48 88 63 47 10 10 7 10 4 17
Table 3每日天气
Date Time Temp.Humidity Pressure Visibility Wind.Speed Precip Events Conditions
4/1/2017 12:15 AM 39.2°F 93%30.41 in 5.0 mi 20.7 mph 9.99 in Overcast
4/1/2017 1:15 AM 39.2°F 93%30.41 in 6.0 mi 21.9 mph N/A Overcast
4/1/2017 2:15 AM 39.2°F 93%30.41 in 6.0 mi 21.9 mph N/A Overcast
4/1/2017 3:15 AM 39.2°F 93%30.41 in 4.0 mi 25.3 mph N/A Overcast
4/1/2017 4:15 AM 39.2°F 93%30.41 in 4.0 mi 11.5 mph N/A Overcast
4/1/2017 5:15 AM 39.2°F 93%30.41 in 5.0 mi 9.2 mph N/A Overcast
4/1/2017 6:15 AM 37.4°F 93%30.41 in 6.0 mi 3.5 mph N/A Overcast
4/1/2017 7:15 AM 37.4°F 93%30.41 in 10.0 mi 5.8 mph N/A Overcast
4/1/2017 8:15 AM 39.2°F 87%30.41 in 10.0 mi 6.9 mph N/A Overcast
4/1/2017 9:15 AM 39.2°F 87%30.41 in 10.0 mi 4.6 mph N/A Overcast
4/1/2017 10:15 AM 42.8°F 76%30.41 in 10.0 mi 3.5 mph N/A Overcast
4/1/2017 11:15 AM 44.6°F 71%30.41 in 10.0 mi 6.9 mph N/A Overcast
4/1/2017 12:15 PM 44.6°F 71%30.41 in 10.0 mi 5.8 mph N/A Overcast
4/1/2017 1:15 PM 44.6°F 71%30.41 in 10.0 mi 9.2 mph N/A Overcast
4/1/2017 2:15 PM 44.6°F 71%30.42 in 10.0 mi 4.6 mph N/A Overcast
Table 4每小时天气
2.2处理数据
为了研究在一个时间段内每个公共自行车站的使用情况,并对其进行可视化,需要对已经获得的数据进行处理。
数据清理,citi bike数据中日期与时间连接在一起,需要将其分开,另外,在天气数据中,每一个数据包含单位,需要将其去除,让其成为计算机可操作的数据;
利用R中dplyr包里的group_by函数,对citi bike数据集按照起始站(start station)进行分组,获得新的数据集,起始站数据集
利用R中dplyr包里的group_by函数,对citi bike数据集按照终点站(end station)进行分组,获得新的数据集,终点站数据集
2.3可视化
将不同数据集输入到专业数据可视化网站plotly对新获得的数据集进行可视化
Figure1显示一年内有多少自行车从车站出发,尺寸大小代表出发数量
Figure2显示一年内有多少自行车到来车站,尺寸大小代表出发数量
Figure3显示了出发车辆占车站总车辆数的比例
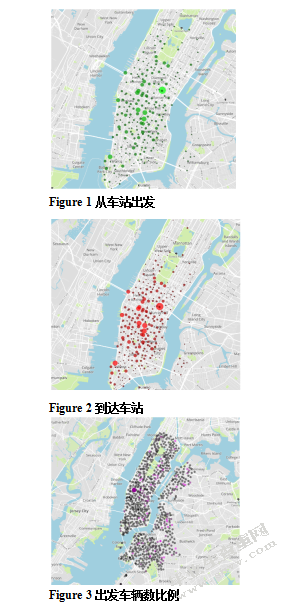

Figure 1从车站出发
Figure 2到达车站
Figure 3出发车辆数比例
进一步,研究早晨和傍晚的高峰时刻对自行车用量的影响
Figure 4显示了晚高峰的用车比例,颜色深浅和尺寸大小都代表了用车比例
Figure 5显示了早高峰的用车比例,颜色深浅和尺寸大小都代表了用车比例
Figure 6显示了晚高峰的出发比例
Figure 7显示了五月份每一天每一个时刻车站含有车的数量

Figure 4
Figure 5
Figure 6
利用Rstudio里的shiny,展示五月份每一天每一个时刻车站含有车的数量Figure 7
Figure 7车站内自行车数量
3、预测模型
3.1数据处理
从citi bike数据集中计算得到每日骑行次数,并与每日天气数据进行合并,给天气状况变量重新赋值,0=好天气,1=坏天气;给假期变量重新赋值,0=非假期,1=有假期;最后对星期、假期、天气变量因子化,得到用量-每日天气数据集。
从citi bike数据集中计算得到每小时骑行次数,并与每小时天气数据进行合并,处理方法与上一步骤类似,最后得到用量-每小时天气数据集
3.2对每日自行车使用量进行预测
这部分利用用量-每日天气数据集进行建模。共享单车使用数量受到天气因素影响较大,另外使用量也受到工作日以及非工作日,节假日和季节的制约,因此该部分主要探究共享单车的使用量与上述变量之间的关系。
3.2.1模型假设与约定
数据真实可靠
不同模型均使用相同的训练集和测试集,其中随机选取70%作为训练集,30%作为测试集
把RMSE作为不同模型的对比标准,RMSE越小越好。RMSE=,MSE为均方误差
3.2.2符号说明
名词解释名词解释
num自行车使用量wind_h当日最大风力
temp_h当日最高气温wind_a当日平均风力
temp_a当日平均气温wind_l当日最小风力
temp_l当日最低气温precip当日降雨量
humidity_h当日最高湿度weather当日天气状况
humidity_a当日最平均湿度holiday是否加假日
humidity_h当日最低湿度season季节
visibility_h当日最高能见度dayofweek星期几
visibility_a当日平均能见度
visibility_l当日最低能见度
其中num为自行车使用量,也是被预测变量。
3.2.3线性模型
对num进行全变量建模,Adjusted R-Square=0.8336,p-value<2.2e-16
RMSE=6291.082
Estimate Std.Error t value Pr(>|t|)
(Intercept)-7683.64 9578.93-0.802 0.423297
temp_h 1748.38 509.29 3.433 0.000707***
temp_a-2039.97 1001.05-2.038 0.042707*
temp_l 1051.54 502.00 2.095 0.037289*
humidity_h 231.42 100.41 2.305 0.022066*
humidity_a-302.58 169.87-1.781 0.076179.
humidity_l 149.49 97.65 1.531 0.127159
visibility_h NA NA NA NA
visibility_a 557.78 753.41 0.740 0.459845
visibility_l 700.19 287.00 2.440 0.015455*
wind_h-238.76 168.97-1.413 0.158999
wind_a-179.87 259.56-0.693 0.489009
wind_l 134.79 49.66 2.714 0.007147**
precip-100.94 17.09-5.906 1.24e-08***
weather1-2830.85 1321.67-2.142 0.033250*
Holiday1-13879.14 2949.21-4.706 4.35e-06***
seasonspring-4298.64 1507.01-2.852 0.004732**
seasonsummer-8061.90 1468.23-5.491 1.05e-07***
seasonwinter-6244.81 1849.94-3.376 0.000864***
dayofweek2 3747.33 1768.89 2.118 0.035204*
dayofweek3 3965.62 1870.13 2.121 0.035030*
dayofweek4 4134.33 1774.63 2.330 0.020686*
dayofweek5 1397.26 1810.23 0.772 0.440979
dayofweek6-5668.10 1832.25-3.094 0.002222**
dayofweek7-8318.17 1821.29-4.567 8.04e-6
根据建模结果,我们发现visibility_h变量存在奇异值,检查数据visibility_h这列数据均为相同的大小,因此该变变量没有考虑价值,故而删除该变量,随后模型亦舍弃该变量,不再赘述。
3.2.3.1模型改进
根据上述全模型结果,删除变量visibility_h后,Adjusted R-Square=0.8336,
p-value<2.2e-16,RMSE=6291.082
Estimate Std.Error t value Pr(>|t|)
(Intercept)-7683.64 9578.93-0.802 0.423297
temp_h 1748.38 509.29 3.433 0.000707***
temp_a-2039.97 1001.05-2.038 0.042707*
temp_l 1051.54 502.00 2.095 0.037289*
humidity_h 231.42 100.41 2.305 0.022066*
humidity_a-302.58 169.87-1.781 0.076179.
humidity_l 149.49 97.65 1.531 0.127159
visibility_a 557.78 753.41 0.740 0.459845
visibility_l 700.19 287.00 2.440 0.015455*
wind_h-238.76 168.97-1.413 0.158999
wind_a-179.87 259.56-0.693 0.489009
wind_l 134.79 49.66 2.714 0.007147**
precip-100.94 17.09-5.906 1.24e-08***
weather1-2830.85 1321.67-2.142 0.033250*
Holiday1-13879.14 2949.21-4.706 4.35e-06***
seasonspring-4298.64 1507.01-2.852 0.004732**
seasonsummer-8061.90 1468.23-5.491 1.05e-07***
seasonwinter-6244.81 1849.94-3.376 0.000864***
dayofweek2 3747.33 1768.89 2.118 0.035204*
dayofweek3 3965.62 1870.13 2.121 0.035030*
dayofweek4 4134.33 1774.63 2.330 0.020686*
dayofweek5 1397.26 1810.23 0.772 0.440979
dayofweek6-5668.10 1832.25-3.094 0.002222**
dayofweek7-8318.17 1821.29-4.567 8.04e-06***
当继续去除一些不显著的变量时候(p-value较大的变量),发现模型没有变得更好,相反RMSE还有一定程度的变大,因此保留该改进后的模型。
3.2.4随机森林
随机森林是一种基于分类树的算法,其运算量在没有很大提高的情况下能提高运算精度,在这里,依然使用去掉visibility_h后的数据对自行车使用量num进行预测。结果如下,
根据结果,发现方差解释度达到81.56%,RMSE=6683.772
3.2.5 stepwise
Stepwise方法包括向前、向后、双向三个方向,在这三个相似的模型中使用BIC(贝叶斯信息准则),这是因为BIC引入了模型参数个数的惩罚项,并且BIC惩罚项比AIC大,同时BIC也考虑了样本数量,所以,当样本数量较大的时候,BIC在防止模型精度过高从而导致模型复杂度过高上比AIC更有效。
其中L=极大似然函数的估计值,n=样本量,k=参数个数+2
向前法模型保留变量:全部保留,共16个变量
向后法保留变量:temp_h+temp_a+temp_l+visibility_l+wind_h+wind_l+precip+holiday+season+dayofweek共10个变量
双向法保留变量:temp_h+temp_a+temp_l+visibility_l+wind_h+wind_l+precip+holiday+season+dayofweek共10个变量
向前向后双向
Adusted R-Square 0.8336 0.8296 0.8296
P-value<2.2e-16<2.2e-16<2.2e-16
RMSE 6291.082 6295.711 6295.711
从模型上看,三种方法都有不错的Adjusted R-Square和P-Value,RMSE也十分相近,但是从模型复杂度上来说,向后法和双向法更,因为这两个方法在相同的精度下,把变量个数减少到10个,模型更简便。
3.2.6其他模型与比较
首先,GLM是最小二乘回归的拓展,适用于因变量是正整数或者分类数据的情况,在本例中,每日自行车使用量是正整数,且根据是否工作日,是否节假日,哪个季节均可分类,因此我考虑了该模型,并设定参数为正态分布(gaussian)。
其次,由于自行车每日使用量在数值上比其他变量的绝对值要大很多,因此我也考虑了对自行车使用量num进行了log(num)变换,但是结果并不理想。
最后考虑广义相加模型(GAM),自行车使用量num与其他变量之间并不一定存在很强的线性关系,这从之前的模型中RMSE以直很难降低可以看出,因此考虑GAM模型,该模型可应用与因变量和自变量不呈线性关系的情况,且可对部分或全部的自变量采用平滑的方法建立模型,设定分布参数为正态分布(gaussian)。
GLM log(num)GAM
Adjusted R-Square-0.7269-
P-Value-<2.2e-16-
RMSE 6291.082 10095.74 6291.082
3.2.7总结
根据以上所有模型的结果,RMSE都十分相近,在尝试不同思路的情况下,依然不能更进一步降低RMSE的值,更有模型在原本以为会有更好结果的情况下给出了相似甚至更高的RMSE。但是,上述模型stepwise中的向后法和双向法在相似的RMSE情况下极大的简化了模型,由此可以认为这两种线性模型在应用于预测每日用车量的需求下是比较优秀的。但是我们也不能否认随机森林这一非线性模型的优良性能,其给出的模型具有高于80%的方差解释率,RMSE也比较底,在预测中尚可接受。
3.3对每小时自行车使用量进行预测
本部分建模使用用量-每小时天气数据集。此部分分析过程与上一部分,即对每日自行车用量预测部分,相似。需要预测的自行车使用量num相同,不一样的是自变量有所区别。
3.3.1符号说明
名词解释名词解释
num自行车使用量condition天气状况
time时刻holiday节日
temp气温season季节
humidity湿度dayofweek星期几
visibility能见度
precip降雨量
events是否极端天气
3.3.2模型
由于建模过程与上部分类似,该部分将尽可能简洁。
线性模型向前向后双向GLM log(num)GAM
Adujsted R-Square 0.4566 0.4566 0.4566 0.4566 0.4881
P-value<2.2e-16<2.2e-16<2.2e-16<2.2e-16<2.2e-16
RMSE 1254.244 1254.244 1253.526 1253.526 1254.24 1839.629 1254.24
3.3.3总结
相较于上一部分,模型间的比较是相似的,向后法和双向法依然在相似RMSE的情况下给出的最简化的线性模型。但是对于小时用车量的预测并不如上一部分对每日用车辆预测的结果精确,首先Adjusted R-Square降低到了约0.4,约为上一部分的53%,其次针对每小时用车辆预测的RMSE相较于每日预测的RMSE没有减小到合理的程度。因此,对每小时用车辆的预测方法还不够完善。
4.总结
在这两个月的时间里,从选题到完成整个论文对我来是一个漫长的过程,在这个过程中,我的思路不断清晰,每一个阶段都指定相应的计划,比如在开始阶段,在citi bike的官网下载数据并进行数据清理,学习R相关的包从专业天气网站爬取所需要的天气数据,应用处理大数据的包对数据进行分类和整合;数据可视化阶段,学习shiny做数据可视化,另一方面尝试使用数据可视化专业网站plotly来展示共享自行车的使用状况,虽然这部分工作没有实质性的解决一些问题,但是在这个过程中我熟悉使用了R语言对大数据的相关处理操作,而可视化方面的探索提高了我对数据概况的展示能力,并且数据可视化在将来的各个方面都大有应用,我深信这一点,至少在这个项目中,我们可以利用数据可视化给APP设计界面,给共享单车管理者们提供直观的可视化的数据作为参考。最后是数据建模阶段,我对数据的每一个变量深入思考,思考他们的含义,思考怎样定义数据类型,探索怎样的模型能够增加模型的精确度,在这个过程中,加深了我对模型的深入理解,学会去用Adjusted R-Square和cross validation去比较模型的好坏,成功的一方面是对于每日用车量的建模结果比较好,Adjusted R-Square和RMSE都比较令人满意,但是不足的是还未找到更好的方法去预测每小时的用车量,这是遗憾的一点。总的来说,要完善整个项目,在数据可视化方面还需要加强,给用户就近推进最近的公用自行车站是一个很有意思的方向;另外在建模方面,继续提高对于每天用车量和每小时用车量预测的精度,以给公用自行车管理者提供最佳的公用自行车分配方案,提高利用率和服务效率,不断推进“最后一公里”的绿色出行理念,最后达到提升城市公共交通的使用率,减小出行的时间和费用成本的目的。
下载提示:
1、如文档侵犯商业秘密、侵犯著作权、侵犯人身权等,请点击“文章版权申述”(推荐),也可以打举报电话:18735597641(电话支持时间:9:00-18:30)。
2、网站文档一经付费(服务费),不意味着购买了该文档的版权,仅供个人/单位学习、研究之用,不得用于商业用途,未经授权,严禁复制、发行、汇编、翻译或者网络传播等,侵权必究。
3、本站所有内容均由合作方或网友投稿,本站不对文档的完整性、权威性及其观点立场正确性做任何保证或承诺!文档内容仅供研究参考,付费前请自行鉴别。如您付费,意味着您自己接受本站规则且自行承担风险,本站不退款、不进行额外附加服务。
原创文章,作者:写文章小能手,如若转载,请注明出处:https://www.447766.cn/chachong/13682.html,