1引言
1.1GDP的影响
随着国家的发展,我们的生活水平也在不断提高,国内的经济也在不断的变化,因国内的生产总值(GDP)受着经济、资源、人口数量的增加、科技、环境等诸多不同的影响,这就使GDP的存在很多的变化,又因GDP不仅能放映一个国家的经济问题,还能够反映一个国家的经济实力,除此之外我们还能从GDP中看出国家的经济发展情况,他是昌隆还是衰退,还有就是它能够很直接的表现出国民的收入问题以及消费问题,因此可以从GDP中看出一个国家内的经济状况。因此GDP变化对于国家来说是非常重要的,所以研究GDP预测是非常有必要的。通过前人多年的研究,时间序列模型在对于研究GDP中有个很大的影响,时间序列模型现已在GDP预测中有着很大的帮助与决策作用。
因在核算体系中国内的生产总值(GDP)是一个非常重要的综合性统计的指标,国内生产总值能够更清楚的反映各国家的经济实力和市场规模,与此同时也是各个国家XX制定的经济发展战略与抉择经济策略的重要根据。因GDP会随着时间的变化而变化,那么他们之间存在着一定的关系。由于ARIMA模型建立在时间序列上,因此ARIMA模型的预测本质上是通过使用时间变化来发展经济现象,通过这种现象能够使其从而扩大了社会和经济发展的总体规律。我们知道,各省的地区生产总值加起来等于全国的国内生产总值,那么我们可以通过研究各省的地区生产总值来了解全国的国内生产总值的相关情况。我们如果要进行各省的地区生产总值进行研究时,就需要一个宏观的准确的预测。一个国家未来的GDP走势会影响着这个国家的发展,因此我们可以通过运用ARIMA模型来进行预测。并且通过其得到的数据来调整这个国家的经济状况。更可以为国家以及各省份的经济发展、目标提供非常重要的决策与参考。可以通过运用Eviews8软件来建立时间序列模型,并根据历史数据做出该地区的预测,并对其进行分析。
1.2贵州省经济历史背景
在通过历史数据可知在近七年来,贵州省GDP一直增速连续全国前三。在2015年贵州省的生产总值第一次突破到万亿元,紧接着在2016年贵州省地区的生产总值再次突破到一个高峰,全年实现生产总值11733.43亿元,增幅比全国国内生产总值增幅高3.8个百分点。贵州地区生产总值于2017年攀升为13540.83亿元,其增速达到了10.2%。近年来,在全贵州省人民的共同努力下,全省经济保持了快速增长,经济保持稳定。有着很大的进展。保持着良好的经济发展状态。随着政策的改革,贵州省紧紧抓住了国家资本市场的扶贫政策,通过大力发展国家大数据,根据贵州省的优势把畜牧业发展开来,把生态环境与发展共同起步前进,两头都抓把以贫困地区为重点,通过旅游来带动发展等,通过提高人民的收入来改善人们的生活,让人民过上美好而又舒心的生活,那么这样贵州省GDP才会有效的提高,这样才能体现出GDP的重要性。因此,研究贵州省的GDP未来趋势,会使经济得到很好的调整,让经济向着好的方面发展,那么可想而知研究贵州省的GDP是多么的重要。通过采用时间序列分析方法以贵州省过去的GDP数据为基础,通过处理后进行选择来建立出与其拟合较好的时间序列模型,通过建模的数据结果来分析其经济增长特征来对未来五年的经济发展做出很精确的预测分析,并且通过预测分析结果能够为XX提供很好的依据与制定出很好的经济发展战略。
1.3研究目的和意义
随着国家的高速发展,各个地区的经济也在不断的增长,在经济发展过程中,GDP也变成人们重点的关注对象。GDP的构成是在一个国度生存,人们在必然期间内的全数常住单元的全数生产活动的终究成果。总所周知,因一个国家的综合力大都是用国内生产总值这个指标来衡量的,此外,它还可以用来衡量一个国家整体的经济波动。还有着分析经济周期状况等等。在这个发展中的国家里,GDP数据也是不可缺少的,因为GDP这个指标的大小反映了经济体量的大小,其增长速度综合反映了经济的运行情况,因而人们在关注经济问题时总是非常关注这个指标。并且XX在制定经济发展规划和出台经济政策时一个主要的参考指标便是GDP[1]。当我们把GDP作用研究对象时,我们除了需要历史数据,我们还需要一个非常好的分析方法。从以往的研究表明来看,对研究GDP预测这一问题,大都是运用时间序列模型的方法来处理此问题的。那么我们可以运用时间序列模型对贵州省的GDP进行准确预测分析,研究GDP对于社会、对于经济都是具有重要的理论和实际意义的。
每一个发达城市都离不开经济的发展,经济的发展表现大都是取决于每个地区的GDP,所以研究GDP是每一个国家或者地区的重中之重。因时间序列模型是一种模型比较简单,其数据要求也相对简单。因他只需要变量本身的历史数据来进行数据处理和分析,通过得到处理分析后的数据,把它运用到实际生活中来,最后发现他在实践生活中具有非常广泛而且实用。这就可以知道这种模型是一种非常实用而又高精度的预测方法了。通过以贵州省过去的GDP数据为基础,用时间序列模型对这些数据进行分析处理,来研究未来几年的GDP走势,通过这种方法可以知道,时间序列模型能够准确地预测我省GDP将来的走势,还能揭示GDP发展变化的规律,通过研究得出的未来GDP的走势来进一步的调整贵州省的经济规划。这样能够为贵州省的发展带来很好的帮助,这也能够给每一个贵州省人民带来可观的经济收入,这能够为国家宏观经济的有效调控和政策制定提供理论引导。
2文献综述
根据近十几年关于GDP的文献来看,研究方法大多数都是时间序列方法。大多作者都是通过才用时间序列分析方法来对历史数据进行处理,根据其要求建立ARIMA模型,并对其模型进行显著性检验,最终满足各个综合条件得到最优的时间序列模型,并运用此模型来预测分析。
随着经济的日渐增长,GDP的数值就引起了很多人的关注,曾俞会新在2000年的研究中建立一个时间序列模型,这个模型是关于我国人均内生产总值,使用的方法是判别时间序列平稳性的方法[2]。在研究中,他对时间序列的单个阶数采用单一根方法进行检测,这种检测方法比较简单,通过这种检测能够判断出是否出现虚假回归的情况。他进而对差分序列的平稳性进行了鉴别,然后根据自回归函数图和偏相关函数图的情况对时间序列模型的自回归性进行检验,接着他利用TSP软件来处理自回归阶数(AR(p))与移动平均阶数(MA(q)),进而对时间序列模型的参数进行确定,所采用的方法是最小二乘法,所得到的相关参数通过了相关检验。最后他模型回归的结果做了进一步的分析。在2008年时宋海礁收集了上海29年的地区生产总值的数据,时间跨度为1978-2006年,他然后采用实证分析法对这些数据进行了处理和分析,根据相关模型的结果对上海市2007-2009年的地区生产总值数据进行了预测。通过对比预测的数据与实际值GDP数值发现两者误差较小,进而得出ARIMA模型在进行短期预测可靠性实高。魏后凯在200年时收集了15年的我国各区域的时间数据和面板数据,这15年为1985年到1999年,运用实证分析法仔细研究了在我国各区域经济发展中外商投资所起到到的作用大小,从数据处理的结果分析可以看出,在这15年间,东部地区经济高速增长的90%的原因可以归结中外商投资企业的作用。[3]。刘颖等人在2005年时采用实证方法研究我国人均国内生产总值,建模时采用了伯克斯-詹金斯(Box-Jenkins)模型,并利用模型预测了近期的数据[4]。在2006年时赵盈为了研究我国我国国内生产总值增速变化的特点采用了B-J方法,建立ARIMA模型,对我国1954年到2004年共计51年的国内生产总值的数据进行处理和回归,进而详细分析了我国国内生产总值增速情变动情况[5]。赵晓葵(2009)收集了我国从1966到2006年共计41年的国内生产总值数据,并对这些数据的时间序列性进行了检验,进而选择ARMA模型进行建模和分析,从分析的结果来看,Box-Jenkins方法非常适合对GDP时间序列进行建模和预测,而这种模型准确性很高,成果的可靠性也比较高[6]。在2010年时赵喜仓等人收集我国的季度国内生产总值季度数据,这些数据的时间跨度为1992年到2008年,共计17年,在建模时将时间趋势和季节性剔除后建立了季节时间序列模型[7]。李守丽(2012)将郑州市的地区生产总值作用研究对象,在数学建模时运用了曲线拟合和参数估计方法,进而采用ARIMA模型预测了2013年到现在预测了未来5年郑州市地区生产总值。[8]。在2017年李辉等获得了伊犁州1978到至2014年共计27年的数据,并用Eviewes8.0软件来处理数据处理,进而检测了模型进行显著性检验,
在考虑到各种情况后建立了时间序列回归模型,还预测了各地的经济政策9]。在第2007年时靳珊分析我国1950-2006年的国内生产总值的数据。并对相关数据进行了分析。因而国内生产总值(GDP)是一种非常重要的的指标,本文收集了贵州省1950年到2006年共计计56年的国内生产总值数据,进而使用并且采用Eviews软件建立了ARIMA(1,1,1)模型,最后分析了国内生产总值增速变化的特点10]。
3时间序列建模
3.1时间序列的概念
时间序列是指一组数字序列是由在不同时期里同一种现象的观察值持续排列而形成[11]。一般情况下,大家采用时间序列法来处理历史数据,从而得到此类现象随着时间的变化而变化的规律,进而将这个规律运用到对现象在未来变化的预测中。我们对经济数据进行处理时,一般使用像指数平滑法,滑动平均法这样的确定性时间序列分析法。但是随着国家的快速发展,影响GDP的不确定性很多,同时,生活中的经济的影响力也在增加,引起了很多人的关注。在20世纪70年代初,有两位著名作家一个叫Box,另一位叫詹金斯,他们共同提出时间序列分析方法并且是基于随机理论上的。因时间序列分析的基本模型主要是包括两种模型,一种是AR模型,另一种是MA模型,通过他们的不断努力之后,他们把时间序列分析理论提高到了一个新的水平,并且提高了预测的准确性。
3.2数据平稳性检验
在我们这个美好的生活中,人们也离不开数据了,在我们每时每刻都产生不同的数据,在常见的数据中,大多数数据是非平稳的,这就不能够直接进行拟合,因此我们要进行数据的平稳化处理。该方法是先通过原始数据制作原始序列的序列图,根据原始序列图判断序列是否有明显的趋势和季节变化。,我们还可以根据单位根检验(ADF)来确定他的t统计量和p值。如果原始序列是非平稳的,则可以对原始数据执行对数处理或直接执行连续的差异。然后再分别用同样的方法检验,直到结果检验显示具有平稳性,在其数据中差分的次数即为d的值。
3.3模型识别
由于模型识别可根据两种系数来看出,一种是自相关系数(ACF),另一种则是偏自相关系数(PACF),那么我们就可以根据样本中的自相关图和样本偏差自相关图来找其系数。通过两个图得到的样本自相关系数与偏自相关系数,ARMA(p,q)模型的阶数和系数特性能够通过对这两个系数的分析而确定。对这两个系数的分析有三种情况:第一种,不仅部分相关函数出现了截尾现象,而且自相关函数出现了拖尾现象在平稳序列中,则可以确定。该序列适合AR模型。第二种,如果平稳序列的部分相关函数有尾也就是拖尾,且自相关函数被截断也就是截尾,则可以判断该序列适合于MA模型同时。第三种,在平稳序列中如果拖尾性均出现在自相关函数和偏相关函数里,我们可以确定ARMA模型可以处理这个序列。
3.4模型定阶和参数估计
在平稳时间序列中我们可以根据自相关函数和偏自相关函数对ARMA模型的阶数p和q进行大体估算,进而可以采用相关方法来对其进行确定。最小的信息准则是AIC所遵循的,这样可以计算出的数据得到最准确的ARMA模型阶数和参数,在经济数据的样本量比较少的情况下可以使用此方法[12]。
通过使用B-J建模的方法定出相应阶数,并得到多个模型,我们在估计不同模型的参数以确定数据模型的顺序之后,应该估计ARMA模型的设计参数,最后,我在通过使用最小二乘法OLS,来估计参数。
3.5模型检验和预测
对估计结果进行相关检查和诊断是必不可以少的步骤,根据检查和诊断的情况可以分析得出这个模型与我们所掌握的情况是相一致。如果不相一致的话,需要找到相关原因,并采取方法进行修改。在建立模型并获得各相关因子的参数后我们必须对模型的参数进行检验,这里要用到t检验;进而查看白噪声的现象是不是出现在残差序列中,这里要用Q统计量对应的p值来判断残差序列是否为白噪声序列。通过残差序列图对模型进行适应性检验和参数的显著性检验[13]。得到拟合程度最好的时间序列模型,最后我们利用所建立的最优模型来进行预测分析贵州省的未来几年的GDP情况。
4实证分析
4.1数据来源
本文的数据来源于贵州省统计局2018年年鉴中的2-6历年地区生产总值表。本文以贵州省1978-2017年地区生产总值数据为例,通过运用时间序列分析的方法对贵州省的数据进行分析处理,最后得到最优的模型,之后运用所得模型来预测2013-2017年的贵州省历史数据国民生产总值(GDP),用2013-2017年的预测值与其实际生产总值做比较,通过得到的预测值与实际值之间是否与之相吻合,在看其是否可以应用于实际的预测中来。得出的结果若可行,则对贵州省未来5年的国民生产总值(GDP)做出预测分析。
4.2贵州省地区生产总值时间序列分析
在ARMA模型中,时间序列的产生是随机的,而且随着时间的变化这种随机性依然存在,而且这种随机也比较平稳的,在根据模型计算转变出的图形中,这种随机性表现为在一定的水平线的上下出现样本点,这些样本点的出现不具有规律性,且限定在一定范围内。遇到非平稳时间序列时差分平稳化和零均值处理的步骤必不可少,而且要提前做。[14]。
4.2.1模型的平稳性检验
本文收集了贵州省历史数据,时间跨度为1978年到2017年的GDP数据,通过运用Eviews8.0软件绘制出贵阳省的原始时间序列图,其下图为图4-1


通过进行单位根检验得到上表4-1,从原始表4-1以看出其P值为1,ADF=2.888759,这两个值都大于给定的临界值,所以待检验序列为一个非平稳序列,所以得到该检验没有通过。因此需要进一步对原始数据序列进行分析与处理,为了能够使其达到平稳化,可以选择以下两种方法,第一种方法为:取对数法,第二种方法为:差分法。

由图4-2显然看出:经过取对数处理后的对数序列仍具有明显的上升趋势,且由表4-2可以看出ADF=0.291745大于给定的临界值,不能够拒绝原假设,因此其序列为非平稳,应对其用低阶差分方法来对数据进行处理,使其能够达到平稳化。
那么需要对取对数后的数据进行一阶差分,并且其平稳性也需要进一步的检验。如下表4-3所示。

从表4-3可以看出ADF检验的结果表明统计量为0.0019,其统计量都小于给定下的检验值(1%、5%、10%),并其p值=0.0019小于显著水平0.05,因此接受原假设,那么可以确定一阶差分后的序列为平稳序列。可以知道其序列为一阶单整序列。
4.3贵州省GDP时间序列模型建立
本文是通过研究时间序列模型,来研究贵州省GDP的未来前景,在时间序列预测方面,首先需要根据时间序列和贵州数据找到最优预测模型。因此,预测的关键有两个因素,既为确定阶数和估计参数。
4.3.1模型识别
我们有很多方法可以识别和确定ARMA(p,q)模型,但我们通常获得的办法是观察样本的自相关函数,还有就是偏自相关函数。如下图4-3所示
注:D(LOGGDP)是LOGGDP一阶差分值

从图4-3中我们可以发现,在滞后一个阶段后LOGGDP一阶差分序列的自相关系数不断减小,最终接近0,均为截断,也就是截尾,在偏自相关分析图中乐意明显的看出,偏自相关系数在滞后一周期后还并不是0,也是不断的减小,最终达到0。我们也可以确定截尾这种现象也出现在了此序列的一部分自相关系数中。所以,自相关系统能够确定阶数q,可以取自1;p,并由不为0的偏自相关系数确定,观测图表的值能够为1。虽然做了以上工作,但我们还要对这个模型进行检测,来判断其是否具有合理性,然后可以使用规则来进行最优模型识别。
根据上述的图4-3,可以建立AIC定则模型识别定阶表,如下表4-4所示

由表4-4分析可知,在上述得到的所有模型中,得到ARMA(1,1)是最优的,因我们是一阶差分后的对数数据建立的ARMA(1,1)模型,就是相当于直接对对数GDP数据建立ARIMA(1,1,1)模型,故选择ARIMA(1,1,1)模型进行参数估计。
4.3.2模型参数估计与建立
以下是模型ARMA(1,1,1)的参数估计。该模型如下表4-5所示。

4.3.3模型检验
在完成参数估计后对模型和工作进行识别后,对统计量进行检验,进而确定做立的模型是不是合理。下图为所建立模型的残差序列图。
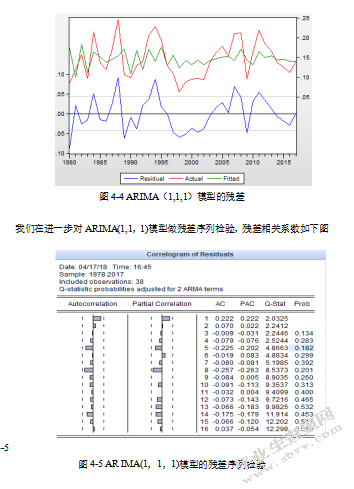
因白噪声检验是对模型最好的检验方法之一,所以需要确定何为白噪声检验,如果检验的结果表明Q统计量的P值最小值或者基本上都是大于0.05时,且PACF没有显著异于零,ACF也没有显著异于零,满足于上述要求那么对于这个残差序列进行的白噪声检验,就可以确定该残差序列是白噪声序列。
由上图4-5所知该模型满足白噪声序列,又模型参数的P值的最小值=0.134很小,参数显著,整个模型相对精简,更重要的是其模型也是更好的。
把上式模型差分形式去掉可得模型为
4.4贵州省GDP预测及分析
关于预测是大家都知道是通过运用一定的方法来对现有的信息资料进行精准的运算与分析,并找出其规律在对未来的事情进行下一步的测算,通过预算得到的结果来对未来做出相应的调整。
这里选择ARIMA(1,1,1)模型来预测2013-2017年贵州省GDP的预测值,
2013年一2017年贵州省地区生产总值预测值与实际值比较

由上表4-6可知,通过验证2013年一2017年的数据贵州省的预测值与实际值之间的差值都是非常小的,与此同时预测结果相对误差也都是小,则可以知道很明显表现出了预测效果是非常良好的,预测模型是非常好的,所以,由此可知AR IMA(1,1,1)模型对于贵州省的GDP预测是一个很好的时间序列模型,因此我们通过此模型来对预测贵州省未来5年的GDP数据,如下表4-7所示

由上表4-7可知在2018年贵州省GDP将达到15726.59亿元,比2017年增加了2186.88亿元,通过ARIMA((1,1,1)模型得到未来贵州省地区的生产总值(GDP)预测值将持续快速增长,随着贵州省经济的快速增长,贵州省人民的经济收入也不断增加,生活水平也会得到很大的提高。
5总结
本文所选的是以时间序列理论为基础的,运用时间序列模型来分析历史数据,并且揭示出其现象会随着时间变化而变化,找出其中的规律,通过这种规律我们再将他延伸到未来,预测未来得到的数据可考虑为未来实际数据的范围。用时间序列模型来研究贵州省的GDP,可较直观的看出其未来趋势,通过对贵州省1978年至2017年的地区生产总值为数据基础资料,用一定的时间序列方法来建模,得到模型ARIMA(1,1,1),并且模型ARIMA(1,1,1)用于比较贵州省2013-2017年的预测GDP和实际GDP,用建模得到的数据来分析未来贵州省GDP的走势,结果表明未来5年贵州省地区GDP将是持续增长的趋势,由于得到的预测结果表明贵州省未来的经济状况发展和经济增长趋势都呈现的是上升的,那么应该对贵州省的经济进行更好的相应调整,使贵州省的经济达到稳步快速发展,让贵州省每一个家庭都过上小康生活,所以贵州省应该根据利用好时间序列模型所得出的数据与其自身优势来发展经济,使贵州省的生产总值能够到达更好的结果。并且尽可能的争取实现在“十三五”期间各贫困县至少有一家上市公司。
参考文献
[1]刘薇.时间序列分析在吉林省GDP预测中的应用[D].东北师范大学,2008.
[2]俞会新.中国人均GDP的时间序列模型的建立与分析[J].河北工业大学学报,
2000,(05):74-77.
[3]魏后凯.外商直接投资对中国区域经济增长的影响[J].经济研究,2002,
(04):19-26+92-93.
[4]刘颖,张智慧.中国人均GDP(1952-2002)时间序列分析[J].统计与决策,
2005,(04):61-62.
[5]赵盈.我国GDP时间序列模型的建立与实证分析[J].西安财经学院学报,2006,(03):11-14.
[6]赵晓葵.基于Box-Jenkins方法的中国年度GDP时间序列分析建模与预测[J].青海师范大学学报(自然科学版),2009,(03):15-19.
[7]赵喜仓,周作杰.基于SARIMA模型的我国季度GDP时间序列分析与预测[J].统计与决策,2010,(22):18-20.
[8]李守丽.时间序列分析法在预测未来GDP中的应用[J].科技信息,2012,(28):114-115.
[9]李辉,田梓辰,李苏北,刘淼.基于时间序列分析方法的伊犁州GDP的预测研究[J].数学的实践与认识,2017,(13):15-23.
[10]靳珊.ARIMA模型在贵州GDP中的应用[J].科教文汇,2007(29):154-155.
[11]庞皓.计量经济学[M]科学出版社,2014,
[12]祝发龙,龙如银.计量经济学[M].徐州:中国矿业人学山版社,2002
[13]易丹辉.统计预测方法与应用[M].北京:中国统计出版社,2001
[14]Andrei,E.-A.and Bugudui,E.(2011)Econometric Modeling of GDP Time Series.Theoretical&Applied Economics,2011,91-98.
下载提示:
1、如文档侵犯商业秘密、侵犯著作权、侵犯人身权等,请点击“文章版权申述”(推荐),也可以打举报电话:18735597641(电话支持时间:9:00-18:30)。
2、网站文档一经付费(服务费),不意味着购买了该文档的版权,仅供个人/单位学习、研究之用,不得用于商业用途,未经授权,严禁复制、发行、汇编、翻译或者网络传播等,侵权必究。
3、本站所有内容均由合作方或网友投稿,本站不对文档的完整性、权威性及其观点立场正确性做任何保证或承诺!文档内容仅供研究参考,付费前请自行鉴别。如您付费,意味着您自己接受本站规则且自行承担风险,本站不退款、不进行额外附加服务。
原创文章,作者:写文章小能手,如若转载,请注明出处:https://www.447766.cn/chachong/15706.html,