绪论
1.1 选题背景和意义
1.1.1 选题背景
在我国资本市场和市场经济快速发展的过程中,伴随而来的是上市公司之间愈演愈烈的竞争。面对日趋激烈的竞争压力,许多上市公司在发展过程中往往急于扩大规模。比如许多的医药上市公司,在国家对药品质量要求越来越严格的同时也在大力鼓励医药行业的发展,加强市场集中度。这就引发了药企的并购热潮,连续并购成了一些大型医药企业的选择,比如上海医药,在一年间就发起了连续十多起的并购;三胞集团以8.19亿收购了X医药界“谷歌”丹德里昂;复星医药斥巨资以10.9亿收购印度药企Gland phrama。但在企业规模快速扩张的同时,与收益相伴相随的潜在的财务风险也可能不断扩大。例如新华医疗在频繁的并购下财务风险更是急速扩大。从2016年开始产生财务危机,净利润开始断崖式大幅下跌,2017年也不断下滑,就是一个典型的反面案例。不断变化的市场、压力极大的竞争、不确定的政策都有可能阻碍企业的发展。
因此近年来,预防和控制公司的财务风险,受到公司的各个利益相关者普遍的关注,提出了对公司财务风险的预测要做到既准确又及时的要求。对于财务风险的预测,从二十世纪三十年代就有学者开始展开了研究。最早是通过单变量模型来对财务风险进行预测。随着更多的学者们加入到对财务风险研究,越来越多的方法也被运用于财务风险的识别预警中。逻辑回归模型、支持向量机模型、神经网络预警模型、随机森林预警模型、主成分分析法、因子分析法、功效系数模型和风险坐标图法等方法在预警模型的构建中各有利弊。
1.1.2 选题意义
医药制造业作为典型的高投资、高收益、高风险的行业,财务风险管理与内部控制作为企业财务管理的重要部分,是医药制造业健康稳定发展的基础。因此医药制造上市公司必须充分认识行业的特点,在既是机遇又是挑战的情况下,利用定性分析、定量分析、建立预警模型等方式来识别、防范和控制财务风险,调整自身的战略,建立约束机制,从而谋求更加长远的发展。
有效的财务风险预警模型能帮助企业提早识别和控制风险;也能够帮助投资者发现具有成长力的公司,合理制定投资计划,保护投资者利益;预警模型的构建也有利于监管层识别企业风险,提早对企业进行一定控制,从而也能够维护金融市场的稳定。
1.2 研究内容与方法
1.2.1 研究内容
本文第一部分阐述了选题的背景和意义,介绍了研究的内容和方法。
第二部分基于国内外的研究文献展开综述,介绍了国内外用于财务预警的各种方法,并对主要的几个模型特点进行总结评述。
第三部分从宏观环境和政策、医药行业背景和企业内部原因三个方面对影响财务风险的因素进行影响机制的分析。
第四部分主要介绍随机森林算法相关内容,然后结合财务风险的特点,梳理财务指标,构建比较全面且合适的指标体系。
第五部分对选取用以实证的数据来源进行说明。再对数据进行预处理,删除异常值、无用的数据。然后构建随机森林预警模型,再将测试集代入训练好的预警模型中,计算出模型的预测精度。
第六部分对全文进行总结,提出完善财务预警内控机制的展望。
1.2.2 研究方法
本文将理论分析与实证方法相结合。理论分析探究影响财务风险的各因素的影响机制,梳理出一套完整且适用的财务指标体系。实证分析借助R语言软件,利用医药制造业实际数据训练随机森林财务预警模型,并对模型进行测试检验。
2.国内外的研究动态
2.1 国外财务风险研究综述
国外资本市场的发达使得学术界很早就开始了对财务风险的研究,众多学者提出了各种分析方法,构建了不同的预警模型。
2.1.1 单变量判别分析法
单变量判别分析是基于某个特定指标,为这个指标设置一个区间,一旦指标数值不在合理区间范围内,则企业可能面临着财务风险。如Fitzpatrick(1932)[3]通过对 19家公司财务数据进行研究,发现产权比率和股东权益净利率可以较有效的判别企业是否存在财务风险。Beaver(1996)[2]通过对79家公司财务数据进行研究,发现债务保障率指标对财务风险的判别效果最好。两位学者分别通过产权比率、股东权益净利率和债务保障率指标来判别企业是否存在财务风险。
2.1.2 多变量判别分析法
多变量判别分析法并不单单基于某个特定的变量,而是组合了多个变量来对结果进行判断。主要包括的方法有构建多元判别、Logistic、人工神经网络等模型。
多元判别模型基于多变量的统计方法构建模型,Altman(1968)[1]通过观察和分析X破产和非破产企业的数据,选取出了五个财务指标。并且对每个财务指标基于相应的权重,构建出首个多变量模型即Z-Score模型,可用于对企业营运状况、是否破产进行判别。
Logistic模型回归又称逻辑回归模型,模型中包含ax+b的形式。逻辑回归模型的因变量是二分类的也可以是多分类的。以企业是否存在财务风险为例,将所有企业分为两组,分别为是否破产,自变量为两组企业的财务指标,因变量为是否有财务风险。将数据进行logistic回归分析,可以得到不同的指标在这个模型中各自相应的权重。通过自变量不同的权重可以看出哪些自变量是反映企业存在财务风险的指标,同时也可以根据所得的权重——构建好的模型来预测其他的公司是否存在财务风险。这个模型的预测率较高。首次利用逻辑回归模型进行财务风险评价研究的是Ohlson(1980)[4],利用两组公司的数据进行研究,分别为存在财务危机和不存在财务危机。通过寻找企业财务危机分割点来确定公司财务风险评价模型,具有很高的准确率。David West(2000)[6]通过对比多变量模型对公司财务风险评价的准确度,发现Logistic模型对风险评估的精确度很高。
人工神经网络又称ANN模型,Odom和Sharda(1990)[5]首次利用神经网络模型针对财务风险展开了研究。他们选出了5个财务类指标作为预警指标,以公司是否破产将样本数据分为两组,使用BP神经网络构建财务风险预测模型。最后结果得到了人工神经网络方法相较于传统的多元判别方法具有更好的预测能力,在数据处理和预测准确度方面具有明显的优势,它的自主学习能力和纠错能力较强,能够较好的对结果进行判定。
2.2 国内财务风险研究综述
国内近几年对财务风险识别的研究方法十分多样化,包括定性识别和定量识别。定性识别指的是基于经验和直觉,通过逻辑分析和归纳演绎,通过语言的描述来说明被分析对象的性质特征。定量识别是利用搜集到的数据,构建数学模型,用数学的语言进行描述被分析对象的特征、数量关系与数量变化。近年来我国用于构建预警模型的方法也十分多样化。
2.2.1 定性识别
国内对于财务风险识别的定性研究方法主要有以下几个:专家调查法、幕景分析法、四阶段症状法以及财务报表分析法。刘文琦(2011)[18]介绍专家调查法是通过采用系统的程序,事先草拟调查提纲,提供背景材料,轮番征询不同经验丰富的专家的预测意见,从而判断公司是否可能在此背景下遭遇财务风险。张春梅(2012)[33]介绍幕景分析法能识别关键的因素以及其影响,联合使用数字、图表及折线等方式来描述某种状态。当影响财务风险的条件和因素发生变化时,财务风险会有不同的状态。幕景分析方法在具体的运用中,分为筛选、监测和诊断三个过程。黄朝阳(2016)[12]介绍四阶段症状法是把有财务风险的企业分为四个阶段,分别为危机潜伏期、发作期、恶化期和实现期。在每个阶段企业的表现都各不相同。根据企业不同的特定表现,来判定企业财务风险的大小,对症下药,提出风险管理的意见。
财务报表中各指标通常可以反映一个企业的营运状况、偿债能力、盈利能力等,通过找到财务报表中某些指标的矛盾之处,可以揭示是否存在财务xx以及存在财务风险的情况。如江锋(2012)[15]提及刘姝威利用企业的会计报表进行定性分析,通过深度的考察来找到其中矛盾之处。从而揭发了轰动一时的银广夏和蓝田股份财务作假案件。吕露(2018)[21]通过分析公司的财务报表了解到公司的经营、盈利、负债状况以及现金流量的情况,从而明确能够对企业财务造成影响的因素。
2.2.2 定量识别方法
定量识别方法包括构建逻辑回归模型、支持向量机模型、神经网络预警模型、随机森林预警模型等,还有的学者将两个模型结合起来运用。除这些主要模型之外,还存有一些其他的方法,比如利用德菲尔法和极小广义方差法构建财务风险评价指标体系、主成分分析法、因子分析法、功效系数模型和风险坐标图法。
构建逻辑回归模型操作简单,并且具有较高的预测精确度。吴淑艳(2016)[26]将筛选出的指标进行主成分分析,然后构建Logistic模型。通过实证分析证明该模型判定结果与实际结果基本相符,对公司财务风险评估的准确度为94.1%,模型具有良好的判别能力,可为公司财务风险评估提供参考。罗晓光(2011)[17]基于logistic回归法构建了财务风险评估体系,通过多指标监控了商业银行的财务风险。总体精确度达到87.96%。但是逻辑回归要基于最大似然法估计参数,而最大似然法预测的概率要基于所给定的指标中,无法考虑其他非指标因素的影响,与实际有所不符。
支持向量机模型是一种监督学习的模型,可以通过分析数据来进行回归或分析。在小样本、非线性的高维数据处理中有很好的表现。叶兰洲(2017)[32]对上市公司的财务指标展开建模和仿真研究,证明了支持向量机对样本集有很好的分类效果,并且准确度较强于传统的线性方法,得出了支持向量机在上市公司的风险预测方面具有很强的准确率和可行性的结论。曹纳(2018)[9]构建财务与非财务结合的评价指标体系,为财务风险预警的信息化提供了借鉴。SVM可以很好的对企业财务风险进行分类,进而为企业的财务管理提供参考。
人工神经网络模型有较强的自我学习、自我组织、自我适应能力。近些年在人工智能中运用极为广泛,曾被誉为是发展人工智能的希望。尤谊(2013)[29]选取电力上市公司的财务数据,构建了基于BP神经网络的预警模型。通过对模型中网络的反复训练,探究出了输入和输出量之间内在的联系,减少了人为主观因素的干扰,提高了模型的精度。曹彤(2014)[8]结合了BP神经网络和因子分析两种方法,利用2009-2011年山东67家制造业公司的财务和非财务指标数据构建了预警模型,最后测试结果为88%,精确度基本符合模型设计的预期标准,表明该模型能够较好地为山东制造业企业提供财务风险预警信息。刘磊(2016)[19]运用RBF神经网络对26家物流上市企业进行了财务风险预警模型的构建。李光荣(2017)[20]通过运用自适应共振理论算法和自组织特征映射算法分别构建财务风险识别模型。
随机森林包含多棵决策树的分类器,能够对样本进行训练并进行预测。可以用于处理大量、高维的变量,并且对噪声和异常值有很大的容忍度。能够估计遗失的数据,不用担心数据缺乏完整性,可以维持较高的稳定性还有精准度。林成德(2007)[16]将随机森林运用于指标体系的设计中,更好地挖掘出了原始数据内在的信息,使得所得结果更加稳定,所得到的指标体系具有很好的分类准确性以及泛化性能。方匡南(2011)[10]提出随机森林是一种准确率较高的统计学习理论,并且对噪声和异常值有较高的容忍度,还不会出现过度拟合的问题。江峰(2012)[13]将随机森林方法应用于经济管理学中,利用随机森林对上市公司财务指标筛选,并且对筛选后的指标进行建模,得到95.4%的模型准确率,证明了随机森林适用于财务舞弊的分析中。杨俊芬(2016)[31]在用随机森林建模时发现全部的特征变量对建模的效果最好,因此在建模时,无需过多处理原始数据,应保留原始数据信息。近几年有些学者对随机森林算法进行了改进,提高了预测精度,扩大了可解决的数据范围并且增强了模型的解释能力。许保勋(2012)[7]提出了随机森林的属性加权子空间抽样的改进算法,提高了与分类相关的属性抽取概率,能够解决超高维数据分类问题。姚登举(2014)[30]根据特征变量的重要性对特征进行排序,通过后向序列的搜索方法找到能够使分类性能最优的特征子集,构建了以随机森林为基础的封闭式特征选择算法RFFS。汪政元(2016)[24]提出了贡献度随机森林算法,利用最优分箱(OB)对财务指标进行最优降维,用证据权重变化(WOE)对模型变量进行简化。并且证明了CRF模型的分类性能显著优于其他模型,提高了精确度同时也增强了解释能力。吴辰文(2017)[27]将RPS-VIM和MAE-VIM顺序相应组合,发现这样能够使模型的预测精度得到提高。
将随机森林模型与其他模型对比,其在稳定性、预测精度和可操作性上的优势也是十分明显的。孟杰(2014)[22]分别建立了随机森林、逻辑回归、SVM支持向量机、神经网络的财务预警模型,通过实证分析得到了几种模型的预测精度,结果证明随机森林的预测精度最为精确。他认为逻辑回归方法容易受到数据共线性的影响,且难以将非线性的数据进行拟合;SVM模型则倾向于分析样本容量小的小样本数据,因为它是基于结构风险最小化原则建立的;神经网络则是较为复杂,不易操控。而随机森林可以拟合非线性数据,并且能够适用于各种样本中,原理也较为简单,是多棵决策树的组合,能够被广泛运用于财务风险预测中来更好地提高企业抗风险能力。各数据挖掘模型各有优劣,也有许多学者就将多种方法结合运用,通过优势互补,提高了模型的预测精度和稳定性。曾媛媛(2013)[34]认为决策树和支持向量机各有优劣,而且部分优劣可以互补,结合运用会有更好的效果。张亮(2015)[36]通过实证分析得到基于logistic和SVM两种数据挖掘方法所得到的预警模型精度要高于只基于一种方法建立的预警模型。王元坤(2017)[28]结合了神经网络和随机森林算法,通过随机森林进行特征选择,选择出更为科学合理的特征变量,再将这些特征变量代入神经网络模型中,提高模型整体的稳定性和准确度。
除了运用于财务风险分析中除上述几种模型之外还有很多其他种类的模型,也能够较好的判别风险。比如朱若男(2014)[35]利用变异系数法来确定各指标相应的权重,并且结合德菲尔法和极小广义方差法构建财务风险评价指标体系,提出了基于灰色定权聚类的上市公司财务风险预警模型。王君萍(2016)[25]利用能源上市公司的财务数据,基于主成分分析法构建了财务风险识别模型。赵相忠(2016)[37]基于因子分析法构建了财务风险评价模型。胡梦泽(2017)[13]利用建筑行业企业的数据,运用功效系数模型和风险坐标图法,识别出了23种施工企业面临的主要财务风险。
2.3 国内外研究总结及评述
随着对于财务风险识别方法的深入研究和创新扩展,数据挖掘方法得到了很大的发展。通过对比定性和定量识别方法,定性识别方法虽然能够更加全面地考虑可量化的指标以及不可量化的指标,但相之下定量方法更加的方便有效、节省成本,并且能够避免定性识别方法中主观性较强的缺陷。
定量识别方法从最初的单变量分析方法到多元线性判别方法再到逻辑回归方法,再到神经网络分析法和随机森林,每一次的进步都带来了预警模型预测精度的提高。国内近五年来用于定量识别财务风险的研究方法很多,主要有逻辑回归、支持向量机、神经网络和随机森林的方法,还有主成分分析法、德菲尔法和极小广义方差法、因子分析法以及功效系数模型和风险坐标图法等。基于两种及以上的数据挖掘方法所得到的预警模型在预测精确度和稳定性上得到了很好的提升,因此通过信息融合技术能够有效提升数据挖掘效果。
对比几种主要的研究方法,多元线性判别法对于财务指标有着严格的正态性分布要求,SVM支持向量机更适合运用于非线性、小样本数据。因此神经网络和随机森林算法更适用于针对上市公司建立财务预警模型。由于人工神经网络对数据完整性的要求十分高,所以本文就选择了随机森林算法来构建财务风险预警模型。
3.理论研究
3.1 财务风险与预警的概念
财务风险有广义的财务风险和狭义的财务风险。广义的财务风险指的是存在盈利的不确定性,狭义的指的是存在损失的不确定性。苗家欣(2015)[23]指出企业财务风险是在各种因素的影响下,企业在生产活动以及日常经营中,出现经济损失、经济效益与预期目标存在偏离可能。因为近几年来医药制造业大体上都处于盈利状态,因此本文采取财务风险广义的定义,以盈利的不确定性作为财务风险。根据著名的杜邦分析法可知,衡量一个企业是否盈利,其中最重要的财务指标是净资产收益率(roe)。因此本文以“净资产收益率”作为财务质量“好”和“坏”的划分标准。因此本文以特定行业中净资产收益率前80%的公司为财务质量好,以净资产收益率后20%的公司为财务质量不好。财务质量好即为财务风险小,财务质量不好即为存在较大的财务风险。
财务预警指的是企业要建立对于财务危机的预警机制,定期地开展对于财务状况的预测和评估工作。及时发现财务信息出现的问题以及可能面临的财务风险,提早做出处理,避免企业出现财务危机,导致破产。国内外财务预警的模型主要可以分为两大类,一类是单变量模型,另一类是多变量模型。本文选用多变量模型中的随机森林算法来构建预警模型。
3.2 财务风险归因分析
3.2.1 宏观环境和政策分析
宏观经济、XX支出、关税政策都会在不同的方面上直接或间接地影响到医药制造业的发展。宏观经济的影响通过医药制造业的上游企业进行传导,比如粮食、化工原料、能源动力、交通运输行业。上游行业价格的上涨会通过影响医药制造业的成本而影响到该行业的发展。中央XX对于医药卫生资金的投入也很大程度上会影响到医疗体制改革,影响行业的发展。我国的医药产品相当大一部分用于出口,尤其是化学原料药和中成药。因此控制药品出口退税率可以来调控医药的出口,通过关税政策调控行业的发展。
3.2.2 医药制造业背景分析
医药制造行业自身存在的问题也会在一定程度上影响各个医药企业的发展。该行业存在的问题主要有以下几点:一是医药企业多而乱,缺乏主体性。绝大部分的医药企业缺乏自身的特殊性,医药品种基本相当,没有明确自身的定位。二是缺乏可支撑的医药核心技术,还没完善医药技术创新和科研成果快速产业化的机制。三是仍未摆脱较低的出口附加值、环境污染严重的化学原料及常规手术器械。
3.2.3 企业内部的原因分析
医药企业之所以存在财务风险,与其内部控制没有做到位有着十分紧密的联系。首先是部分企业对于风险控制的意识不足。没有做到强化风险管控,将其落实到日常经营的工作当中。其次是内控的执行力不够,将内控制度作为摆设,没有严格按照内控流程工作。使得企业存在不合理的资金结构、不科学的决策、不合理的存货结构、不够显著的资金流动性、不够合理的股利分配政策等问题。企业内部的原因都会在一定程度上给企业财务带来较大的风险。
3.3 预警机制的必要性
资本市场快速发展,既是上市企业迎来机遇,也是伴随着风险挑战。企业自身规模的扩张可能使企业面临更大的财务风险。若缺失企业的内部风险控制,则可能会导致巨额资产亏损、财务舞弊、效益滑坡等问题。缺少风险内控,不仅会对企业的自身的经营能力以及盈利能力产生影响,还会在一定程度上对企业债权人以及股东的效益产生影响。因此只有在发展以及运行过程中提早对潜在危机进行预测,采取有效的防范措施,才不会导致企业陷入财务危机导致破产。才能保证企业长久的正常运营。所以上市公司需要建立并完善对风险防范内控体系,对财务风险进行提早识别预测。
4.模型说明
4.1 随机森林算法概述
4.1.1 随机森林定义
随机森林是包含多棵决策树,可以用来执行回归和分类任务的机器学习算法。其输出类别是由多棵决策树的输出类别的众数所决定。
4.1.2 随机森林特点
随机森林相当于决策树和双重随机性的结合。一是决策树为采取自上而下递归的方式,以基尼系数或者是以熵值为度量,构造熵值下降最快,也就是信息增益越大的那棵树。到达叶子节点,熵值通常为零。二是双重随机性指的是数据随机和特征随机,避免异常数据或者是特征造成的误差。数据随机是进行有放回的抽样,每次按照一定比例采取样本。特征随机是在选取分类特征时也按照同样的比例每次抽取一定数量的特征数。
4.1.3 随机森林模型构建原理
(1)用N表示样本个数,M表示特征个数。
(2)从容量为N的原样本集中有放回地进行重复抽样,每次抽取的样本容量也都为N ,抽样N次,形成N个训练集。这样每次抽样时原样本集中数据未被抽中的概率可见式(4.1)


当N很大时,这个概率值趋于0.368,如式(4.2)

这表示每次抽样时,原样本集中的数据有大概37%的样本不会被抽中,这些数据被称为袋外数据。为被抽中的数据集可直接作为测试集,用于测试模型的预测精度。
(3)按一定比例确定特征数(通常取总特征数的平方根),输入m(m<M)个特征,作为决策树上的决策点。以基尼系数下降最快来确定最优的特征作为决策点。基尼系数由公式(4.1)可见。

(4)训练完成形成N棵决策树,随机森林模型最后输出的分类结果是由这N棵决策树通过自己的分类结果进行简单的投票决定。决策树生成流程如图4.1。
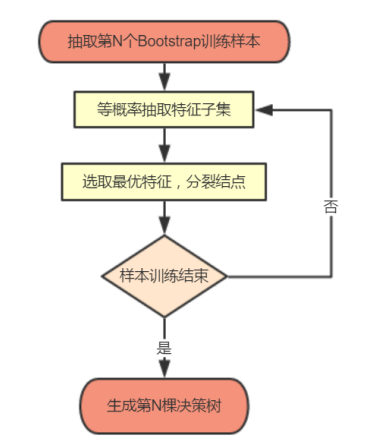
图4.1 随机森林中单个决策树训练过程
4.1.4 随机森林优点
随机森林的优点有如下几点:第一,随机森林对高纬度的数据集能够进行很好地处理,可以处理成千上万的输入变量,并确定每个决策点最优的分裂特征,不需要进行特征选择。第二,当数据集存在异常值时有较好的稳健性,且具有较强的泛化能力。第三,当数据存在大量的缺失时,也能够很好的保持精确性。第四,无需针对模型的精确性进行测试集数据的设置,袋外数据直接可用于测试集。第五,每次抽样都进行了双重随机抽样,保证了每棵树的独立性。
4.1.5 随机森林缺点
随机森林缺点有如下几点:第一,只能选取不同的特征变量和数据,无法对模型内部的运行进行操控,更像是一个黑盒。第二,在解决回归问题时不能给出连续型的输出,可能会导致在存在特定噪声时出现过拟合的问题。
4.2 财务指标体系构建
财务指标的选取既不能过少,如果过少会导致模型无法得到足够的数据支撑,如果过多的话也会导致信息冗杂,模型出现过拟合的现象。因此需要科学合理地选取财务指标来构建财务指标体系。
财务指标的选取要充分考虑各方面因素,使其具备广泛性、全面性、可获得性等原则。首先广泛性即所选取的指标要在前人的报告中已得到权威验证以及具备一定有效性,可以被广泛地采用。其次全面性即指标要覆盖企业财务状况的各个方面,对财务信息和企业所处地位有更全面的反映。最后可获得性是因为财务预警模型的建立是以实证方法进行的,需要各指标对应的数据作为实证的支撑,因此指标的获得必须可获得、易操作。本文使用的数据主要来源于国泰安数据库,部分数据来自于同花顺网站。
对于一个企业而言,反映企业财务状况和行业中所处地位的信息是有多方面的。其中很多重要的信息都来源于企业的财务报表。通过结合资产负债表、利润表、现金流量表中的信息,能够充分地挖掘企业潜在的有关信息,更加深入详细地了解一家企业。基于这些报表中的数据构建财务预警模型,也就能更好地判断企业的财务状况。因此本文从企业的偿债能力、盈利能力、营运能力、成长能力入手,构建了财务指标体系。
4.2.1 偿债能力
企业一般都是采取适当的负债经营,因此资金链的通常是企业经营非常重要的环节。一旦企业因资金链的断裂而无法偿还债务,就会使得企业陷入被动的境地,导致财务危机。所以一个企业的债务偿还能力是衡量企业是否存在财务风险的一个非常重要的指标。因此将企业的偿债能力纳入财务指标体系,具体财务指标及含义如表4.1所示。
表4.1 反映偿债能力的财务指标及含义
| 财务指标名称 | 财务指标含义 |
| 流动比率 | 在短期债务到期之前,流动资产可以变现偿还的能力 |
| 速动比率 | 流动资产可以立即变现偿还的能力 |
| 资产负债率 | 负债所得资产在总资产中的比例 |
| 产权比率 | 反映长期的偿债能力 |
4.2.2 盈利能力
企业的盈利能力可以反映出其在营业收入方面的情况。当企业具备良好的稳定收入,那么其在现金流的运转方面也是比较有保障的,不容易陷入财务危机之中。如果企业的盈利能力不足,经常处于亏损状态,那企业就更加容易陷入财务危机,财务风险也更大。因此该盈利能力能够对企业的发展现状以及资金实力做出判断。具体财务指标及含义如表4.2所示。
表4.2反映偿债能力的财务指标及含义
| 财务指标名称 | 财务指标含义 |
| 资产报酬率 | 总资产的获利能力 |
| 总资产净利润率 | 反映总资产的利用效率 |
| 净资产收益率 | 反映净资产的利用效率 |
| 营业净利率 | 反映获得净利润的能力 |
| 投资收益率 | 反映所有者权益可获得盈利的能力 |
| 营业利润率 | 反映经营的效率 |
| 每股收益 | 反映经营的成果 |
4.2.3 营运能力
企业的营运能力反映出了企业在资源配置方面做出的配置情况。所有的企业资源都是有限的。在有限的资源条件下,做出更为合理的配置和统筹规划,能使企业的经营效益得到最大化,从而使得财务状况良好的运转。如果资源的配置不合理,那也是非常容易使得企业顾此失彼,陷入财务危机。因此将营运能力也纳入到财务指标体系之中,具体财务指标及含义如表4.3所示。
表4.3反映偿债能力的财务指标及含义
| 财务指标名称 | 财务指标含义 |
| 应收账款周转率 | 反映应收账款的周转速度 |
| 存货周转率 | 反映存货的周转速度 |
| 流动资产周转率 | 反映流动资产的周转速度 |
| 固定资产周转率 | 反映固定资产的周转速度 |
| 总资产周转率 | 反映总资产的周转速度 |
| 股东权益周转率 | 反映所有者权益的周转速度 |
4.2.4 成长能力
企业的成长能力能够反映出企业是否具备长远发展的能力。能够不断发展的企业,说明其在各方面的经营都比较有成效,能够作为企业财务状况良好的判断标准之一,具体财务指标及含义如表4.4所示。
表4.4 反映偿债能力的财务指标及含义
| 财务指标名称 | 财务指标含义 |
| 总资产增长率 | 反映总资产规模的增长状况 |
| 净资产收益增长率 | 反映净资产规模的增长状况 |
| 股权资本增长率 | 反映所有者权益规模的增长状况 |
| 净利润增长率 | 反映净利润规模的增长状况 |
| 营业利润增长率 | 反映营业利润规模的增长状况 |
综上所诉,在企业这四个能力的范围内,本文总共采用了22个财务指标运用于财务预警模型的构建,详见下表4.5。
表4.5 财务指标及其计算公式
| 财务指标 | 偿债能力 | 流动比率 | 流动资产/流动负债 |
| 速动比率 | (流动资产-存货)/流动负债 | ||
| 资产负债率 | 负债总额/资产总额 | ||
| 产权比率 | 负债总额/股东权益 | ||
| 盈利能力 | 资产报酬率 | 息税前利润/平均资产总额 | |
| 总资产净利润率 | 净利润/平均资产总额 | ||
| 净资产收益率 | 税后利润/所有者权益 | ||
| 营业净利率 | 净利润/营业收入 | ||
| 投资收益率 | 年平均利润总额/投资总额 | ||
| 营业利润率 | 营业利润/总主营业收入 | ||
| 每股收益 | 归属于普通股股东当期净利润/当期发行在外普通股加权平均数 | ||
| 营运能力 | 应收账款周转率 | 主营业务收入/平均应收账款 | |
| 存货周转率 | 主营业务成本/平均存货 | ||
| 流动资产周转率 | 主营业务收入/平均流动资产 | ||
| 固定资产周转率 | 主营业务收入/平均固定资产 | ||
| 总资产周转率 | 主营业务收入/平均资产总额 | ||
| 股东权益周转率 | 营业总收入/平均股东权益 | ||
| 成长能力 | 总资产增长率 | 期末总资产/期初总资产-1 | |
| 净资产收益增长率 | 期末经资产/期初净资产-1 | ||
| 股权资本增长率 | 期末股东资本/期初股东资本-1 | ||
| 净利润增长率 | 期末净利润/期初净利润-1 | ||
| 营业利润增长率 | 期末营业利润总额/期初营业利润总额-1 |
5.实证过程
5.1 数据说明及初步整理
本文实证过程中采取的数据均来自于国泰安CSMAR数据库。行业的划分以证监会的分类为标准,由此选取了医药制造业中的221家公司。采用其2015-2017三年的22个财务指标数据为研究对象。在利用R语言建立随机森林模型过程中,因为不能存在缺失值,因此将每年中存在指标缺失的一行删除。最后得到2015年有152行数据,2016年158行数据,2017年147行数据。
另外加入公司的财务质量指标“q”,利用表格的自定义排序功能,以“净资产收益率”为主要关键词进行降序排序,将每个年份中的前80%记为财务质量“good”,后百20%记为财务质量“bad”。并且将原数据前两列的代码和截止时间删除,将表格转化为CSV格式。
5.2 模型构建及操作过程
5.2.1 导入数据
将2015年的数据集导入Rstudio,并将其命名为rdata:rdata<-read.csv(“D:\\2015sjzh.csv”,header=T)
在Rstudio中观察导入的数据是否正常:View(rdata)
将Rstudio的储存路径更改为D盘下的r_working文件:setwd(“D:\\r_working”)
5.2.2 设置训练集和测试集
在rdata的数据范围内,通过重复取样,将样本分为两种类型的数据集,占比分别为70%和30%:sample_set<-sample(2,nrow(rdata),replace=T,prob=c(0.7,0.3))
将第一种类型数据集命名为训练集train_set:train_set<-rdata[sample_set==1,]
将第二种类型数据集命名为测试集test_set:test_set<-rdata[sample_set==2,]
5.2.3 训练模型
在已下载好randomForest的R的前提下加载这个R包:library(randomForest)
设置随机树种子,标记为“961”,使下次产生的随机数仍得到相同的结果:set.seed(961)
使用R包,生成随机森林模型,并命名为rf_model:
rf_model<-randomForest(q ~ .,data=train_set,ntree=100,mtry=4,importance=TRUE)
再次输入rf_model,得到对训练集的训练结果如表5.1:
表5.1 2015年数据的模型训练结果
| Type of random forest: classification
Number of trees: 100 No. of variables tried at each split: 4 | |||
| OOB estimate of error rate: 2.75% | |||
| Confusion matrix: | |||
| bad | good | Class.error | |
| bad | 23 | 1 | 0.04166667 |
| good | 2 | 83 | 0.02352941 |
由以上数据可以得知,用随机森林模型对训练集进行分类训练,错误率为2.75%。可以看到模型将训练集中的“bad”属性误判为“good”的错误率为4.17%,而对“bad”属性的判别准确率为95.8%;将“good”误判为“bad”的错误率为2.35%,而对“good”属性的判别准确率为97.6%。
5.3 模型测试及结果分析
用已经训练好的随机森林分类模型(rf_model)对测试集数据的公司财务质量进行预测,将测试结构命名为rf_predict:rf_predict<-predict(rf_model,test_set)
列出一张可视表,观察对象是测试集, 测试对象是质量(q), 用刚才建立的随机森林模型进行测试:table(observed=test_set$q,predicted=rf_predict)
得到的预测结果见表5.2:
表5.22015年数据模型预测结果
| observed | bad | good |
| bad | 6 | 0 |
| good | 0 | 37 |
由结果可以看到,在测试集的所有观察值中,属性为“bad”的,被识别为“bad”的有6家,被识别为“good”的为0家,识别准确率为100%;属性为“good”的,被识别为“bad”的有0家,被识别为“good”的为37家,识别正确率为100%。整体准确率为100%,因此由2015年数据训练出的随机森林模型具有较强的准确性。
5.4 训练及测试其它年份数据
5.4.1 2016年数据的模型训练及测试
将2016和2017年的数据分别导入Rstudio中,除了导入的数据不同之外,其他过程按照相同的方法,分别建立训练模型并对测试集进行准确度测试。
表5.3 2016年数据的模型训练结果
| Type of random forest: classification
Number of trees: 100 No. of variables tried at each split: 4 | |||
| OOB estimate of error rate: 2.83% | |||
| Confusion matrix: | |||
| bad | good | Class.error | |
| bad | 21 | 1 | 0.04545455 |
| good | 2 | 82 | 0.02380952 |
由表5.3可以得知,用随机森林模型对训练集进行分类训练,错误率为2.83%。可以看到模型将训练集中的“bad”属性误判为“good”的错误率为4.55%,而对“bad”属性的判别准确率为95.5%;将“good”误判为“bad”的错误率为2.38%,而对“good”属性的判别准确率为97.6%。
表5.4 2016年数据模型预测结果
| observed | bad | good |
| bad | 9 | 1 |
| good | 1 | 41 |
由表5.4可以看到,在测试集的所有观察值中,属性为“bad”的,被识别为“bad”的有9家,被识别为“good”的为1家,识别准确率为90%;属性为“good”的,被识别为“bad”的有1家,被识别为“good”的为41家,识别正确率为97.6%。整体准确率为96.2%,因此由2016年数据训练出的随机森林模型具有较强的准确性。
5.4.2 2017年数据的模型训练及测试
表5.5 2017年数据的模型训练结果
| Type of random forest: classification
Number of trees: 100 No. of variables tried at each split: 4 | |||
| OOB estimate of error rate: 1.87% | |||
| Confusion matrix: | |||
| bad | good | Class.error | |
| bad | 22 | 2 | 0.08333333 |
| good | 0 | 83 | 0.00000000 |
由表5.5可以得知,用随机森林模型对训练集进行分类训练,错误率为1.87%。可以看到模型将训练集中的“bad”属性误判为“good”的错误率为8.33%,而对“bad”属性的判别准确率为91.7%;将“good”误判为“bad”的错误率为0.00%,而对“good”属性的判别准确率为100%。
表5.62017年数据模型预测结果
| observed | bad | good |
| bad | 4 | 1 |
| good | 0 | 34 |
由表5.6可以看到,在测试集的所有观察值中,属性为“bad”的,被识别为“bad”的有4家,被识别为“good”的为1家,识别准确率为80%;属性为“good”的,被识别为“bad”的有0家,被识别为“good”的为34家识别正确率为100%。整体准确率为97.4%,因此由2017年数据训练出的随机森林模型具有较强的准确性。
5.5 特征变量重要性
运用基于2015年数据构建的随机森林模型,输出每个特征变量的重要性:importance(rf_model)。
Mean Decrease Accuracy代表的是基于特征变量对准确率影响程度的大小,数值越大,说明重要性越大。并基于它进行特征变量排序,如表5.7所示。
表5.7 基于2015年数据特征标量的重要性大小
| 名称 | Financial indicator | Mean Decrease Accuracy |
| 净资产收益率 | jzcsyl | 7.2868605 |
| 总资产净利润率 | zzcjlr | 5.8525613 |
| 资产报酬率 | zcbcl | 5.0346018 |
| 每股收益 | mgsy | 3.6956044 |
| 所有权权益增长率 | syqyzzl | 2.4517453 |
| 营业利润率 | yylrl | 2.4437644 |
| 净利润增长率 | zlrzzl | 1.4280755 |
| 产权比率 | cqbl | 1.3858198 |
| 总资产增长率 | zzczzl | 1.2122178 |
| 速动比率 | sdbl | 1.041153 |
| 营业利润增长率 | yylrzzl | 0.7407509 |
| 存货周转率 | chzzl | 0.5988114 |
| 净资产收益增长率 | jzczzl | 0.4859623 |
| 投资收益率 | tzsyl | 0.4000991 |
| 流动比率 | Ldbl | 0.3736274 |
续表5.7 基于2015年数据特征标量的重要性大小
| 流动资产周转率 | ldzczzl | -0.3444452 |
| 应收账款周转率 | yszkzzl | -0.6941527 |
| 资产负债率 | zcfzl | -0.8338785 |
| 固定资产周转率 | gdzczzl | -1.5181217 |
5.6 实证分析小结
基于2015-2017年的医药制造业财务指标数据,建立的随机森林模型的准确率分别为100%、96.2%、97.4%,准确率都比较高,因此证明了该随机森林模型对与财务质量和状况的预测有较大的可行性。
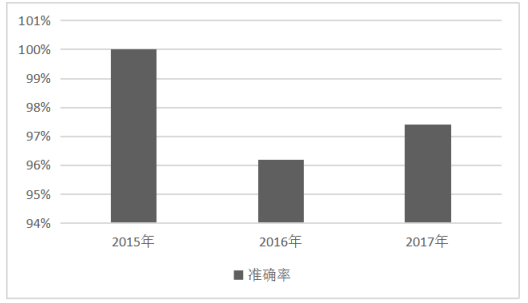
图5.12015-2017年模型预测准确率
将排序表格转化为柱状图,可以更加直观清晰地看出各特征变量的重要性大小排序。净资产收益率对于模型准确率的影响最大,其次是总资产近利润率,影响最小的是固定资产周转率。如图5.1所示。
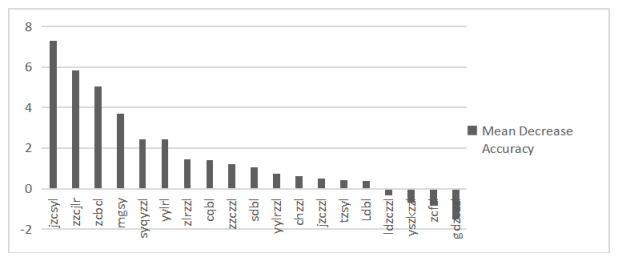
图5.2基于预测准确率的特征变量重要度
总结展望
6.1 总结
本文共选取了22个财务指标,利用医药制造业2015-2017三年的财务数据,运用R语言中的randomForest软件包建立起随机森林模型。根据建模后所得到的结果可分析得知无论是对训练集的分类还是对测试集的预测,构建得到的随机森林模型都能很好地发挥作用,预测准确率都在96%以上。这说明可以采用该方法对公司的财务风险进行预测。
6.2展望
企业不仅要注重自身的发展、规模的扩大、利润的提升,也要注重在经营过程中对于自身风险的防控。建立起以随机森林模型等方法为主的财务风险预警模型是很好的选择。只有企业在加强内控的前提下,才能另企业不断壮大发展下去。
在预防风险的意识不断加深的社会背景下,相信类似随机森林这类的方法会在社会大众之中变得更加的普及。

1、如文档侵犯商业秘密、侵犯著作权、侵犯人身权等,请点击“文章版权申述”(推荐),也可以打举报电话:18735597641(电话支持时间:9:00-18:30)。
2、网站文档一经付费(服务费),不意味着购买了该文档的版权,仅供个人/单位学习、研究之用,不得用于商业用途,未经授权,严禁复制、发行、汇编、翻译或者网络传播等,侵权必究。
3、本站所有内容均由合作方或网友投稿,本站不对文档的完整性、权威性及其观点立场正确性做任何保证或承诺!文档内容仅供研究参考,付费前请自行鉴别。如您付费,意味着您自己接受本站规则且自行承担风险,本站不退款、不进行额外附加服务。
原创文章,作者:打字小能手,如若转载,请注明出处:https://www.447766.cn/chachong/79603.html,